Análisis léxico en el compilador
El análisis léxico en el compilador es el primer paso en el análisis del programa fuente. El análisis léxico lee el flujo de entrada del programa de origen carácter por carácter y produce la secuencia de tokens. Estos tokens se proporcionan como entrada al analizador para su análisis. En este contexto, discutiremos brevemente el proceso de análisis léxico junto con los errores léxicos y su recuperación.
Contenido: Análisis Léxico en Compilador
- Terminologías en Análisis Léxico
- ¿Qué es el Análisis Léxico?
- Ejemplos de Análisis Léxico
- Función del Analizador Léxico
- Error Léxico
- Recuperación de errores
- Conclusiones clave
Terminologías en el Análisis léxico
Antes de entrar en lo que el análisis léxico es cómo se realiza, hablemos de algunas terminologías que encontraremos mientras discutimos el análisis léxico.
- Lexema
El lexema se puede definir como una secuencia de caracteres que forman un patrón y se puede reconocer como un token. - Patrón
Después de identificar el patrón de lexema, se puede describir qué tipo de token se puede formar. Como el patrón de algunos lexemas forma una palabra clave, el patrón de algunos lexemas forma un identificador. - Token
Un lexema con un patrón válido forma un token. En el análisis léxico, un token válido puede ser identificadores, palabras clave, separadores, caracteres especiales, constantes y operadores.
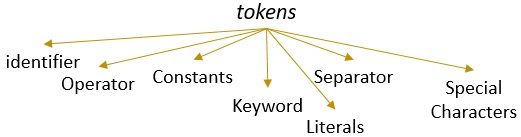
¿Qué es el Análisis Léxico?
Anteriormente hemos dejado de utilizar el analizador léxico en nuestro compilador de contenido en la computadora. Hemos aprendido que el compilador realiza el análisis del programa de origen a través de diferentes fases para transformarlo en el programa de destino. El análisis léxico es la primera fase por la que el programa fuente tiene que pasar.
El análisis léxico es el proceso de tokenización. lee la cadena de entrada de un programa de origen carácter por carácter y tan pronto como identifica un extremo del lexema, identifica su patrón y lo convierte en un token.
El analizador léxico consta de dos procesos consecutivos que incluyen escaneo y análisis léxico.
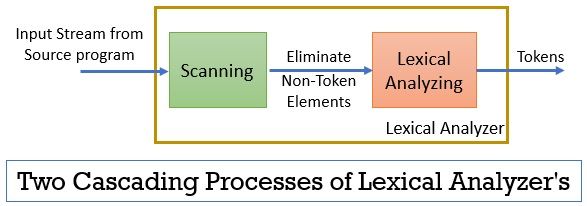
- Escaneo: La fase de escaneo solo elimina los elementos que no son tokens del programa de origen. Como eliminar comentarios, compactar los espacios en blanco consecutivos, etc.
- Análisis Léxico: La fase de análisis léxico realiza la tokenización en la salida proporcionada por el escáner y, por lo tanto, produce tokens.
El programa utilizado para realizar análisis léxico se conoce como lexer o analizador léxico. Ahora tomemos un ejemplo de análisis léxico realizado en una declaración:
Ejemplo 1 de Análisis Léxico:
Análisis léxico en el diseño del compilador, identifique tokens.
Ahora, cuando leamos esta declaración, podemos identificar fácilmente que hay nueve tokens en la declaración anterior.
- Identificadores -> léxica
- Identificadores -> análisis
- Identificadores -> en
- Identificadores -> compilador
- Identificadores -> diseño
- Separador -> ,
- Identificadores -> identificar
- Identificadores -> tokens
- Separador -> .
En total, hay 9 tokens en el flujo de caracteres anterior.
Ejemplo 2 de Análisis Léxico:
printf (“valor de i es %d”, i);
Ahora intentemos encontrar tokens de este flujo de entrada.
- Palabra clave – > printf
- Carácter especial-> (
- Literal – > “El valor de i es %d “
- Separador -> ,
- Identificador – > i
- Carácter especial -> )
- Separador -> ;
Nota:
- La cadena completa dentro de las comillas invertidas dobles, es decir,” “, se considera un solo token.
- El espacio en blanco que separa los caracteres en el flujo de entrada solo separa los tokens y, por lo tanto, se elimina al contar los tokens.
Función del Analizador Léxico
Al ser la primera fase en el análisis del programa fuente, el analizador léxico desempeña un papel importante en la transformación del programa fuente en el programa objetivo.
Todo este escenario se puede realizar con la ayuda de la figura que se muestra a continuación:
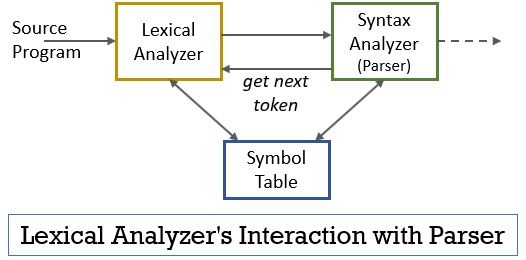
- La fase de analizador léxico tiene implementado el escáner o programa lexer que produce tokens solo cuando el analizador los ordena.
- El analizador genera el comando getNextToken y lo envía al analizador léxico como respuesta a esto, el analizador léxico comienza a leer el flujo de entrada carácter por carácter hasta que identifica un lexema que se puede reconocer como un token.
- Tan pronto como se produce un token, el analizador léxico lo envía al analizador de sintaxis para analizarlo.
- Junto con el analizador de sintaxis, el analizador léxico también se comunica con la tabla de símbolos. Cuando un analizador léxico identifica un lexema como identificador, ingresa ese lexema en la tabla de símbolos.
- A veces, la información del identificador en la tabla de símbolos ayuda al analizador léxico a determinar el token que debe enviarse al analizador sintáctico.
- Además de identificar los tokens en el flujo de entrada, el analizador léxico también elimina el espacio en blanco/espacio en blanco y los comentarios del programa. Tales otras cosas incluyen caracteres, fichas separadas, pestañas, espacios en blanco, líneas nuevas.
- El analizador léxico ayuda a relacionar los mensajes de error producidos por el compilador. Solo, por ejemplo, el analizador léxico mantiene el registro de cada carácter de línea nuevo con el que se encuentra mientras escanea el programa de origen para que relacione fácilmente el mensaje de error con el número de línea del programa de origen.
- Si el programa de origen utiliza macros, el analizador léxico expande las macros en el programa de origen.
Error léxico
El analizador léxico en sí no es eficiente para determinar el error del programa fuente. Por ejemplo, considere una declaración:
prtf (“el valor de i es %d”, i);
Ahora, en la instrucción anterior, cuando se encuentra la cadena prtf, el analizador léxico no puede adivinar si el prtf es una ortografía incorrecta de la palabra clave ‘printf’ o si es un identificador de función no declarado.
Pero de acuerdo con la regla predefinida, prtf es un lexema válido cuyo patrón lo concluye como un token de identificador. Ahora, el analizador léxico enviará el token prtf a la siguiente fase, es decir, el analizador que manejará el error que se produjo debido a la transposición de letras.
Recuperación de errores
Bueno, a veces es incluso imposible para un analizador léxico identificar un lexema como un token, ya que el patrón del lexema no coincide con ninguno de los patrones predefinidos para los tokens. En este caso, tenemos que aplicar algunas estrategias de recuperación de errores.
- En recuperación en modo pánico, el carácter sucesivo del lexema se elimina hasta que el analizador léxico identifique un token válido.
- Elimine el primer carácter de la entrada restante.
- Identifique el posible carácter faltante e insértelo en la entrada restante de forma adecuada.
- Reemplace un carácter en la entrada restante para obtener un token válido.
- Intercambie la posición de dos caracteres adyacentes en la entrada restante.
Mientras realiza las acciones de recuperación de errores anteriores, compruebe si el prefijo de la entrada restante coincide con cualquier patrón de tokens. Generalmente, un error léxico ocurre debido a un solo carácter. Por lo tanto, puede corregir el error léxico con una sola transformación. Y en la medida de lo posible, un número menor de transformaciones debe convertir el programa de origen en una secuencia de tokens válidos que pueda entregar al analizador.
Conclusiones clave
- El análisis léxico es la primera fase del análisis del programa fuente en el compilador.
- El analizador léxico se implementa mediante dos escáneres de procesos consecutivos y análisis léxico.
- El escáner elimina los elementos que no son tokens del flujo de entrada.
- El análisis léxico realiza la tokenización.
- Por lo tanto, el analizador léxico genera una secuencia de tokens y los reenvía al analizador sintáctico.
- El analizador al poseer un token del analizador léxico hace una llamada getNextToken que insiste en que el analizador léxico lea el flujo de entrada de caracteres hasta que identifique el siguiente token.
- Si el analizador léxico identifica el patrón de un lexema como identificador, entonces el analizador léxico ingresa ese lexema en la tabla de símbolos para su uso futuro.
- Lexical analyzer no es eficiente para identificar cualquier error en el programa de origen por sí solo.
- Si se produce un lexema cuyo patrón no coincide con ninguno de los patrones predefinidos de tokens, debe realizar acciones de recuperación de errores para corregirlo.
Por lo tanto, se trata del análisis léxico que transforma el flujo de caracteres en tokens y lo pasa al analizador sintáctico. Hemos aprendido sobre el trabajo del análisis léxico con la ayuda de un ejemplo. Hemos concluido la discusión con el error léxico y su estrategia de recuperación.
Leave a Reply