lexikální analýza v kompilátoru
lexikální analýza v kompilátoru je prvním krokem v analýze zdrojového programu. Lexikální analýza čte vstupní proud ze zdrojového programu znak po znaku a vytváří posloupnost tokenů. Tyto tokeny jsou poskytovány jako vstup do analyzátoru pro analýzu. V této souvislosti budeme stručně diskutovat o procesu lexikální analýzy spolu s lexikálními chybami a jejich obnovením.
obsah: Lexikální analýza v kompilátoru
- terminologie v lexikální analýze
- co je lexikální analýza?
- příklady lexikální analýzy
- úloha lexikálního analyzátoru
- lexikální chyba
- Obnova chyb
- Klíčové Takeaways
terminologie v lexikální analýze
než se dostaneme do toho, co lexikální analýza je, jak se provádí, promluvme si o některých terminologiích, se kterými se setkáme při diskusi o lexikální analýze.
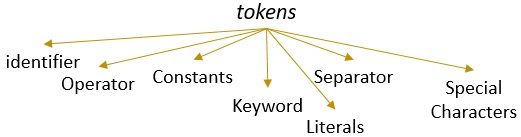
- lexém
lexém lze definovat jako posloupnost znaků, které tvoří vzor a mohou být rozpoznány jako token. - vzor
po identifikaci vzoru lexému lze popsat, jaký druh tokenu lze vytvořit. Například vzor některých lexémů tvoří klíčové slovo, vzor některých lexémů tvoří identifikátor. - Token
lexém s platným vzorem tvoří token. V lexikální analýze mohou být platným tokenem identifikátory, klíčová slova, oddělovače, speciální znaky, konstanty a operátory.
co je lexikální analýza?
dříve jsme nepoužívali lexikální analyzátor v našem kompilátoru obsahu v počítači. Dozvěděli jsme se, že kompilátor provádí analýzu zdrojového programu v různých fázích, aby jej transformoval na cílový program. Lexikální analýza je první fází, kterou musí zdrojový program projít.
lexikální analýza je proces tokenizace tj. čte vstupní řetězec zdrojového programu znak po znaku a jakmile identifikuje konec lexému, identifikuje jeho vzor a převede jej na token.
lexikální analyzátor se skládá ze dvou po sobě jdoucích procesů, které zahrnují skenování a lexikální analýzu.
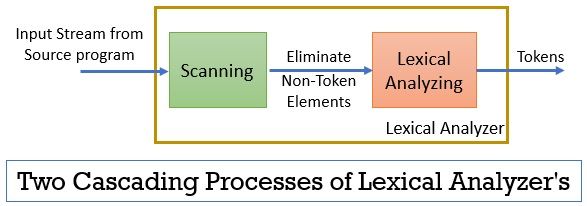
- skenování: fáze skenování-eliminuje pouze prvky bez tokenu ze zdrojového programu. Jako je odstranění komentářů, zhutnění po sobě jdoucích bílých mezer atd.
- Lexikální Analýza: Lexikální analytická fáze provádí tokenizaci na výstupu poskytovaném skenerem a tím vytváří tokeny.
program používaný pro provádění lexikální analýzy se označuje jako lexer nebo lexikální analyzátor. Nyní si vezměme příklad lexikální analýzy provedené na prohlášení:
Příklad 1 lexikální analýzy:
lexikální analýza při návrhu kompilátoru, identifikace tokenů.
Nyní, když si přečteme toto prohlášení, můžeme snadno zjistit, že ve výše uvedeném příkazu je devět žetonů.
- identifikátory – > lexikální
- identifikátory – > analýza
- identifikátory – > v
- identifikátory – > kompilátor
- identifikátory – > design
- oddělovač -> ,
- identifikátory – > identifikujte
- identifikátory – > tokeny
- oddělovač- > .
takže celkem je ve výše uvedeném proudu znaků 9 žetonů.
příklad 2 lexikální analýzy:
printf (“hodnota i je %d”, i);
nyní se pokusme najít tokeny z tohoto vstupního proudu.
- Klíčové slovo – > printf
- speciální znak -> (
- doslovný – > “hodnota i je %d”
- oddělovač -> ,
- identifikátor – > i
- zvláštní znak -> )
- separátor -> ;
Poznámka:
- celý řetězec uvnitř dvojitě obrácených čárek, tj. “” je považován za jediný token.
- prázdné prázdné místo oddělující znaky ve vstupním proudu odděluje pouze tokeny a tím je eliminováno při počítání tokenů.
Role lexikálního analyzátoru
jako první fáze analýzy zdrojového programu hraje lexikální analyzátor důležitou roli při transformaci zdrojového programu na cílový program.
celý tento scénář lze realizovat pomocí níže uvedeného obrázku:
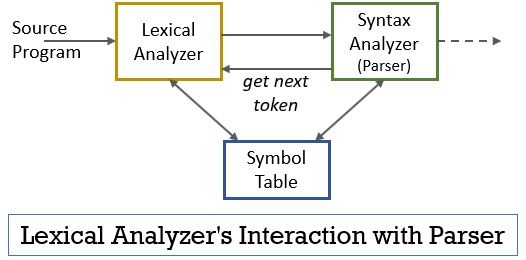
- fáze lexikálního analyzátoru má v sobě implementován program scanner nebo lexer, který produkuje tokeny pouze tehdy,když jim k tomu parser přikáže.
- analyzátor vygeneruje příkaz getNextToken a odešle jej lexikálnímu analyzátoru jako odpověď na to lexikální analyzátor začne číst znak vstupního proudu po znaku, dokud neidentifikuje lexém, který lze rozpoznat jako token.
- jakmile je token vytvořen, lexikální analyzátor jej odešle do analyzátoru syntaxe pro analýzu.
- spolu s analyzátorem syntaxe komunikuje lexikální analyzátor také se tabulkou symbolů. Když lexikální analyzátor identifikuje lexém jako identifikátor, zadá tento lexém do tabulky symbolů.
- někdy informace identifikátoru v tabulce symbolů pomáhají lexikálnímu analyzátoru při určování tokenu, který má být odeslán do analyzátoru.
- kromě identifikace tokenů ve vstupním proudu lexikální analyzátor také eliminuje prázdné místo/prázdné místo a komentáře programu. Mezi takové další věci patří znaky oddělující tokeny, karty, prázdná místa, nové řádky.
- lexikální analyzátor pomáhá při vztahování chybových zpráv vytvořených kompilátorem. Jen, například, lexikální analyzátor uchovává záznam každého nového znaku řádku, na který narazí při skenování zdrojového programu, takže snadno spojí chybovou zprávu s číslem řádku zdrojového programu.
- pokud zdrojový program používá makra, lexikální analyzátor rozšíří makra ve zdrojovém programu.
lexikální chyba
lexikální analyzátor sám o sobě není účinný pro určení chyby ze zdrojového programu. Zvažte například prohlášení:
prtf (“hodnota i je %d”, i) ;
nyní ve výše uvedeném příkazu, když se objeví řetězec prtf, lexikální analyzátor není schopen odhadnout, zda je prtf nesprávným hláskováním klíčového slova “printf” nebo je to nedeklarovaný identifikátor funkce.
ale podle předdefinovaného pravidla je prtf platný lexém, jehož vzor uzavírá, že je identifikačním tokenem. Nyní lexikální analyzátor pošle token prtf do další fáze, tj. analyzátor, který bude zpracovávat chybu, ke které došlo v důsledku transpozice písmen.
Obnova chyb
někdy je dokonce nemožné, aby lexikální analyzátor identifikoval lexém jako token, protože vzor lexému neodpovídá žádnému z předdefinovaných vzorů pro tokeny. V tomto případě musíme použít některé strategie obnovy chyb.
- při obnově panického režimu se po sobě jdoucí znak z lexému odstraní, dokud lexikální analyzátor neidentifikuje platný token.
- odstraňte první znak ze zbývajícího vstupu.
- Identifikujte možný chybějící znak a vhodně jej vložte do zbývajícího vstupu.
- nahraďte znak ve zbývajícím vstupu a získejte platný token.
- vyměňte pozici dvou sousedních znaků ve zbývajícím vstupu.
při provádění výše uvedených akcí obnovení chyb Zkontrolujte, zda předpona zbývajícího vstupu odpovídá jakémukoli vzoru žetonů. Obecně dochází k lexikální chybě v důsledku jediného znaku. Takže můžete opravit lexikální chybu jedinou transformací. A pokud je to možné, menší počet transformací musí převést zdrojový program na posloupnost platných tokenů, které může předat analyzátoru.
klíčová analýza
- lexikální analýza je první fází analýzy zdrojového programu v kompilátoru.
- lexikální analyzátor je implementován dvěma po sobě jdoucími procesy skenerem a lexikální analýzou.
- skener eliminuje prvky bez tokenu ze vstupního proudu.
- lexikální analýza provádí tokenizaci.
- lexikální analyzátor tedy generuje posloupnost žetonů a předává je do analyzátoru.
- analyzátor na držení tokenu z lexikálního analyzátoru zavolá getNextToken, který trvá na tom, že lexikální analyzátor čte vstupní proud znaků, dokud neidentifikuje další token.
- pokud lexikální analyzátor identifikuje vzor lexému jako identifikátor, pak lexikální analyzátor zadá tento lexém do tabulky symbolů pro budoucí použití.
- lexikální analyzátor není účinný k identifikaci jakékoli chyby v samotném zdrojovém programu.
- pokud dojde k lexému, jehož vzor neodpovídá žádnému z předdefinovaných vzorů tokenů, musíte provést akce obnovy chyb, abyste chybu opravili.
jedná se tedy o lexikální analýzu, která transformuje tok znaků na tokeny a předává je analyzátoru. Dozvěděli jsme se o práci lexikální analýzy pomocí příkladu. Diskusi jsme uzavřeli lexikální chybou a její strategií obnovy.
Leave a Reply