Validace dat a ověřování dat-od slovníku ke strojovému učení
Aditya Aggarwal, Advanced Analytics Practice Lead, a Arnab Bose, hlavní vědecký pracovník, Abzooba
poměrně často používáme ověřování dat a validaci dat zaměnitelně, když mluvíme o kvalitě dat. Tyto dva pojmy jsou však odlišné. V tomto článku pochopíme rozdíl ve 4 různých kontextech:
- slovník význam verifikace a validace
- rozdíl mezi verifikací a validací dat obecně
- rozdíl mezi verifikací a validací z pohledu vývoje softwaru
- rozdíl mezi verifikací dat a validací dat z pohledu strojového učení
slovník význam verifikace a validace
Tabulka 1 vysvětluje význam slovníků verifikace a validace několika příklady.

abychom to shrnuli, ověření je o pravdě a přesnosti, zatímco ověření je o podpoře síly úhlu pohledu nebo správnosti nároku. Validace kontroluje správnost metodiky, zatímco ověření kontroluje správnost výsledků.
rozdíl mezi ověřením dat a validací dat obecně
Nyní, když rozumíme doslovnému významu těchto dvou slov, prozkoumejme rozdíl mezi “ověřením dat” a “ověřením dat”.
- ověření dat: ujistěte se, že jsou data přesná.
- ověření dat: ujistěte se, že jsou data správná.
uveďme příklady v tabulce 2.

rozdíl mezi verifikací a validací z pohledu vývoje softwaru
z pohledu vývoje softwaru,
- ověření se provádí, aby se zajistilo, že software je vysoce kvalitní, dobře navržený, robustní a bezchybný, aniž by se dostal do jeho použitelnosti.
- ověření se provádí za účelem zajištění použitelnosti softwaru a kapacity pro splnění potřeb zákazníka.
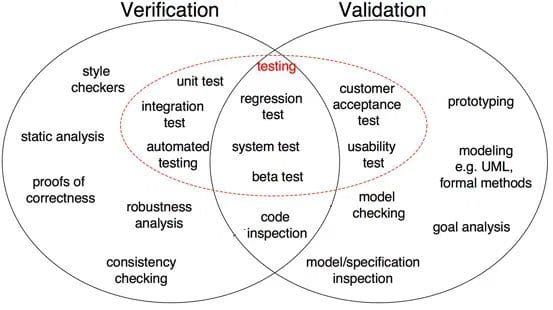
Obr 1: Rozdíly mezi verifikací a validací ve vývoji softwaru (zdroj)
jak je znázorněno na obr. 1, důkaz správnosti, analýza robustnosti, testy jednotek, integrační test a další jsou všechny ověřovací kroky, kde jsou úkoly orientovány na ověření specifik. Výstup softwaru je ověřen proti požadovanému výstupu. Na druhou stranu, kontrola modelu, testování černé skříňky, testování použitelnosti jsou všechny validační kroky, kde jsou úkoly orientovány tak, aby pochopily, zda software splňuje požadavky a očekávání.
rozdíl mezi ověřením dat a validací dat z pohledu strojového učení
role ověření dat v potrubí strojového učení je role gatekeepera. Zajišťuje přesné a aktualizované údaje v průběhu času. Ověření dat se provádí primárně v nové fázi získávání dat, tj. v kroku 8 potrubí ML, jak je znázorněno na obr. 2. Příkladem tohoto kroku je identifikace duplicitních záznamů a provedení deduplikace a odstranění nesouladu v informacích o zákaznících v poli, jako je adresa nebo telefonní číslo.
na druhé straně validace dat (v kroku 3 potrubí ML) zajišťuje, že přírůstková data z kroku 8, která jsou přidána do údajů o učení, jsou kvalitní a podobná (z pohledu statistických vlastností) stávajícím údajům o školení. Jedná se například o nalezení anomálií dat nebo detekci rozdílů mezi stávajícími údaji o školení a novými údaji, které mají být přidány do údajů o školení. V opačném případě může dojít k vynechání jakýchkoli problémů s kvalitou dat / statistických rozdílů v přírůstkových datech a v průběhu času se mohou hromadit chyby školení a zhoršovat přesnost modelu. Validace dat tedy detekuje významné změny (pokud existují) v přírůstkových tréninkových datech v rané fázi, což pomáhá s analýzou hlavních příčin.
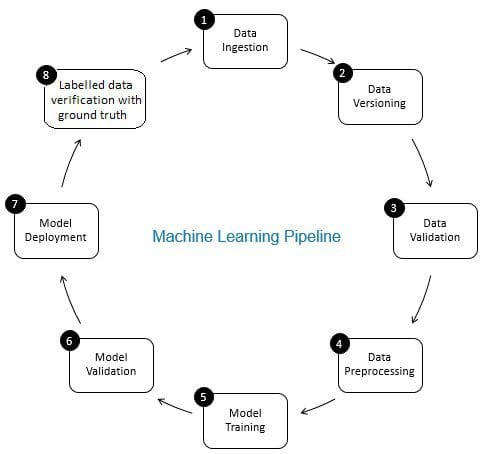
obr 2: součásti strojového učení potrubí
Aditya Aggarwal slouží jako vedoucí vědy o datech ve společnosti Abzooba Inc. S více než 12+ let zkušeností v oblasti řízení obchodních cílů prostřednictvím řešení založených na datech, Aditya se specializuje na prediktivní analytiku, strojové učení, business intelligence & obchodní strategie v celé řadě průmyslových odvětví.
Dr. Arnab Bose je hlavním vědeckým pracovníkem v Abzoobě, společnost pro analýzu dat a doplňková fakulta na University of Chicago, kde vyučuje strojové učení a prediktivní analytiku, operace strojového učení, analýza a prognóza časových řad, a zdravotní analytika v programu Master of Science in Analytics. Je 20letým veteránem prediktivní analytiky, který rád používá nestrukturovaná a strukturovaná data k předpovědi a ovlivňování výsledků chování ve zdravotnictví, maloobchodu, financích a dopravě. Mezi jeho současné oblasti zaměření patří stratifikace zdravotních rizik a řízení chronických onemocnění pomocí strojového učení, a nasazení výroby a monitorování modelů strojového učení.
související:
- MLOps – ” proč je to nutné?”a” co to je”?
- můj model strojového učení se nenaučí. Co mám dělat?
- pozorovatelnost dat, Část II: Jak vytvořit vlastní monitory kvality dat pomocí SQL
Leave a Reply