Data validering og data verifikation – fra Ordbog til Machine Learning
af Aditya Aggarval, Advanced Analytics Practice Lead, og Arnab Bose, Chief Scientific Officer, Absooba
ganske ofte, vi bruger data verifikation og data validering flæng, når vi taler om datakvalitet. Disse to udtryk er imidlertid forskellige. I denne artikel vil vi forstå forskellen i 4 forskellige sammenhænge:
- ordbog betydning af verifikation og validering
- forskel mellem dataverifikation og datavalidering generelt
- forskel mellem verifikation og validering fra programmeludviklingsperspektiv
- forskel mellem dataverifikation og datavalidering fra maskinlæringsperspektiv
ordbog betydning af verifikation og validering
tabel 1 forklarer ordbogens betydning af ordene verifikation og validering med et par eksempler.

for at opsummere handler verifikation om sandhed og nøjagtighed, mens Validering handler om at understøtte styrken af et synspunkt eller rigtigheden af et krav. Validering kontrollerer rigtigheden af en metode, mens verifikation kontrollerer nøjagtigheden af resultaterne.
forskel mellem dataverifikation og datavalidering generelt
nu hvor vi forstår den bogstavelige betydning af de to ord, lad os undersøge forskellen mellem “dataverifikation” og “datavalidering”.
- data verifikation: for at sikre, at dataene er korrekte.
- datavalidering: for at sikre, at dataene er korrekte.
lad os uddybe med eksempler i tabel 2.

forskel mellem verifikation og validering set fra programmeludviklingsperspektiv
set fra et programmeludviklingsperspektiv,
- verifikation udføres for at sikre, at programmet er af høj kvalitet, godt konstrueret, robust og fejlfri uden at komme ind i dets anvendelighed.
- Validering sker for at sikre programmel anvendelighed og kapacitet til at opfylde kundernes behov.
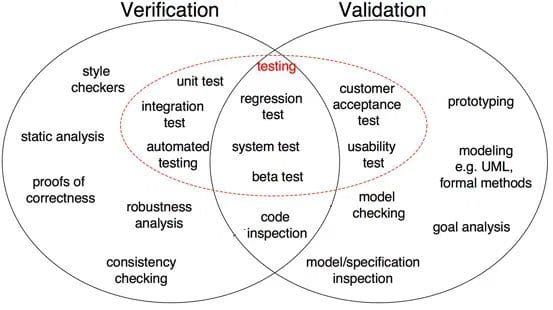
Fig 1: Forskelle mellem verifikation og validering i programmeludvikling (kilde)
som vist i Figur 1 er bevis for korrekthed, robusthedsanalyse, enhedstest, integrationstest og andre alle verifikationstrin, hvor opgaver er orienteret for at verificere SPECIFIKATIONER. Programmel output verificeres mod ønsket output. På den anden side er modelinspektion, test af sort boks, brugbarhedstest alle valideringstrin, hvor opgaver er orienteret for at forstå, om programmer opfylder kravene og forventningerne.
forskel mellem data verifikation og datavalidering fra machine learning perspektiv
rollen af data verifikation i machine learning pipeline er, at en gatekeeper. Det sikrer nøjagtige og opdaterede data over tid. Dataverifikation foretages primært i det nye dataindsamlingsstadium, dvs. i trin 8 I ML-rørledningen, som vist i Fig. 2. Eksempler på dette trin er at identificere duplikatposter og udføre deduplikering og at fjerne uoverensstemmelse i kundeoplysninger i felter som adresse eller telefonnummer.
på den anden side sikrer datavalidering (i trin 3 I ML-rørledningen), at de trinvise data fra trin 8, der føjes til læringsdataene, er af god kvalitet og ligner (fra statistiske egenskabsperspektiv) de eksisterende træningsdata. Dette inkluderer f.eks. at finde dataanomalier eller opdage forskelle mellem eksisterende træningsdata og nye data, der skal føjes til træningsdataene. Ellers kan ethvert datakvalitetsproblem/statistiske forskelle i inkrementelle data gå glip af, og træningsfejl kan ophobes over tid og forringe modelnøjagtigheden. Datavalidering registrerer således betydelige ændringer (hvis nogen) i trinvise træningsdata på et tidligt tidspunkt, der hjælper med rodårsagsanalyse.
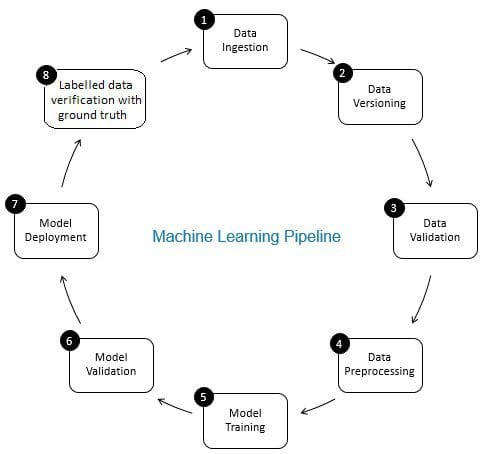
Fig 2: komponenter af Maskinindlæringsrørledning
Aditya aggarval fungerer som Data Science – Practice Lead hos
Dr. Arnab Bose er Chief Scientific Officer, et dataanalysefirma og et supplerende Fakultet ved University of Chicago, hvor han underviser i maskinindlæring og forudsigelig analyse, Maskinindlæringsoperationer, tidsserieanalyse og prognoser og sundhedsanalyse i Master of Science i Analytics-programmet. Han er en 20-årig veteran inden for forudsigelig analyseindustri, der nyder at bruge ustrukturerede og strukturerede data til at forudsige og påvirke adfærdsmæssige resultater inden for sundhedspleje, detailhandel, Økonomi og transport. Hans nuværende fokusområder inkluderer stratificering af sundhedsrisici og håndtering af kroniske sygdomme ved hjælp af maskinindlæring og produktionsudrulning og overvågning af maskinindlæringsmodeller.
relateret:
- MLOps – ” Hvorfor er det nødvendigt?”og” hvad er det”?
- min maskinindlæringsmodel lærer ikke. Hvad skal jeg gøre?
- Dataobservabilitet, del II: Sådan opbygges dine egne Datakvalitetsmonitorer ved hjælp af KVL
Leave a Reply