Hvad er dataaggregering?
i sin enkleste form er dataaggregering processen med at kompilere typisk mængder information fra en given database og organisere den i et mere forbrugsstof og omfattende medium. Dataaggregering kan anvendes i enhver skala, fra pivottabeller til datasøer, for at opsummere information og drage konklusioner baseret på datarige fund. På grund af den voksende tilgængelighed til information og vigtigheden af personaliseringsmålinger på tværs af virksomheden er anvendelsen af dataaggregering blevet ekstremt relevant. Use case er industri-agnostisk og er ofte kritisk for succes og løbende forbedring af organisatoriske operationer over hele verden.
Hvorfor er dataaggregering vigtig?
i vores teknologisk avancerede verden Udvikler data sig konstant, udvides og bliver mere indviklede med hver handling input og output. Data er en af de mest værdifulde valutaer i vores tid, men data uden organisation, segmentering og forståelse er i det væsentlige ubrugelige.
det, der gør data værdifulde, er udvindingen af indsigt, der peger på nøgletendenser, resultater og giver en bedre forståelse af de aktuelle oplysninger. En proces, hvor data søges, indsamles og præsenteres i en sammenfattet, rapportbaseret form, dataaggregering hjælper organisationer med at nå specifikke forretningsmål eller udføre proces/menneskelig analyse i næsten enhver skala.
eksempler på dataaggregering
dataaggregering har været meget udbredt i hele samfundet i utallige år; men med fremskridt inden for computing og teknologi som AI og maskinindlæring er omfanget og kapaciteten af dataaggregering vokset eksponentielt.. Eksempler på dataaggregering kan være så enkle som at indsamle mængden af trin, du tog i denne uge på din pendling til arbejde, og så kompleks som at bruge en ride-sharing-app til at hylde en bil til din nøjagtige placering inden for få minutter. Mens den anden mulighed måske lyder enklere fra et slutbrugerperspektiv, er mængden af data, der skal beregnes og aggregeres for at gøre denne tur tilgængelig for dig, forbløffende. Betydningen af dataaggregering vil fortsætte med at vokse, efterhånden som teknologien bliver mere og mere indlejret i vores livsstil, både hjemme og på arbejdspladsen.
dataaggregering i aktion
i perspektivet af PagerDuty spiller dataaggregering en vigtig rolle i ordningen med realtidsoperationer på tværs af den digitale virksomhed. Bare sidste år indtog PagerDuty mere end tre milliarder forskellige signaler til kunder i alle brugssager. Mens dette tal er svimlende, består de oplysninger, der leveres til kunderne efter indtagelse, på en måde, der er meget mere handlingsbar og nem at forbruge. Dette er storskala dataaggregering på arbejdspladsen.
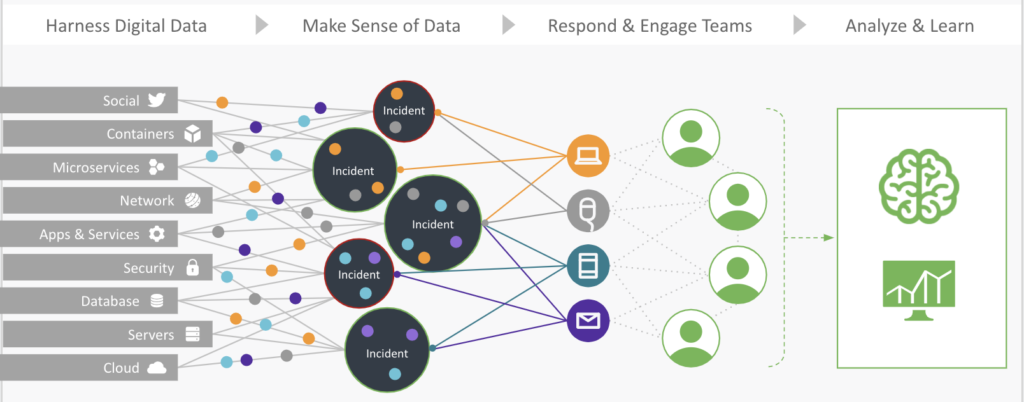
som du kan se på ovenstående billede af, hvordan PagerDuty-platformen behandler information fra forskellige applikationer, indtages signaler via platformen og aggregeres via almindelige variabler og signalmakeup. I dette tilfælde grupperer platformen signaler, der er indbyrdes forbundne inden for en given hændelses makeup. De aggregeres derefter i undergrupper for at gøre overflod af signalinformation lettere at forstå. Ved at gøre dette er PagerDuty-brugere i stand til at udlede handlingsbar indsigt fra platformen og træffe beslutninger baseret på de datakorrelationer, der udgør aggregatet, for at tage den rigtige handling på det rigtige tidspunkt.
Pagerdutys dataaggregeringsfunktioner giver teams mulighed for tovejs at integrere over 350+ integrationer med platformen for at analysere og levere data fra en centraliseret visning, hvilket giver kunderne fuld synlighed i den generelle sundhed i deres infrastruktur. Hvis du vil vide mere om, hvordan PagerDuty kan hjælpe med at samle og reducere driftsstøj—og meget mere—for dit team, kan du prøve PagerDuty i dag.
Leave a Reply