hvordan jeg skriver mine Dataanalyseblogs af Kathleen E. ‘ 23
min kære ven og kollega blogger Kidist A. ’22 anmodede om, at jeg skrev et indlæg for at beskrive, hvordan jeg går i gang med at skrive mine dataanalyseblogs. Så, her går! Jeg har skitseret mine generelle trin og linket til mine gamle indlæg for at give eksempler på, hvad jeg taler om.
Identificer et spørgsmål

jeg begynder med at spørge mig selv følgende:
- hvilken historie vil jeg fortælle?
- Hvordan hjælper dataanalyse med at fortælle den historie?
hvis jeg sidder fast, prøver jeg at tænke på mit liv og verden omkring mig. Er der nogen mønstre, jeg gerne vil undersøge, eller fænomener, jeg gerne vil kvantificere?
her er nogle ting, jeg har spurgt mig selv i fortiden:
- hvordan ser mine arbejdsmønstre ud? Forvirring, ved tallene
- Hvordan er det at klatre i en 20-etagers bygning 22 gange? Green Building Challenge
- hvordan føler MIT-studerende sig om vores sovesalers nye vaskesystem? Vasklava! En sentimentanalyse
dernæst spørger jeg mig selv, hvilken slags data der ville være nyttigt at besvare dit spørgsmål. Dette bringer os til næste trin:
saml nogle data
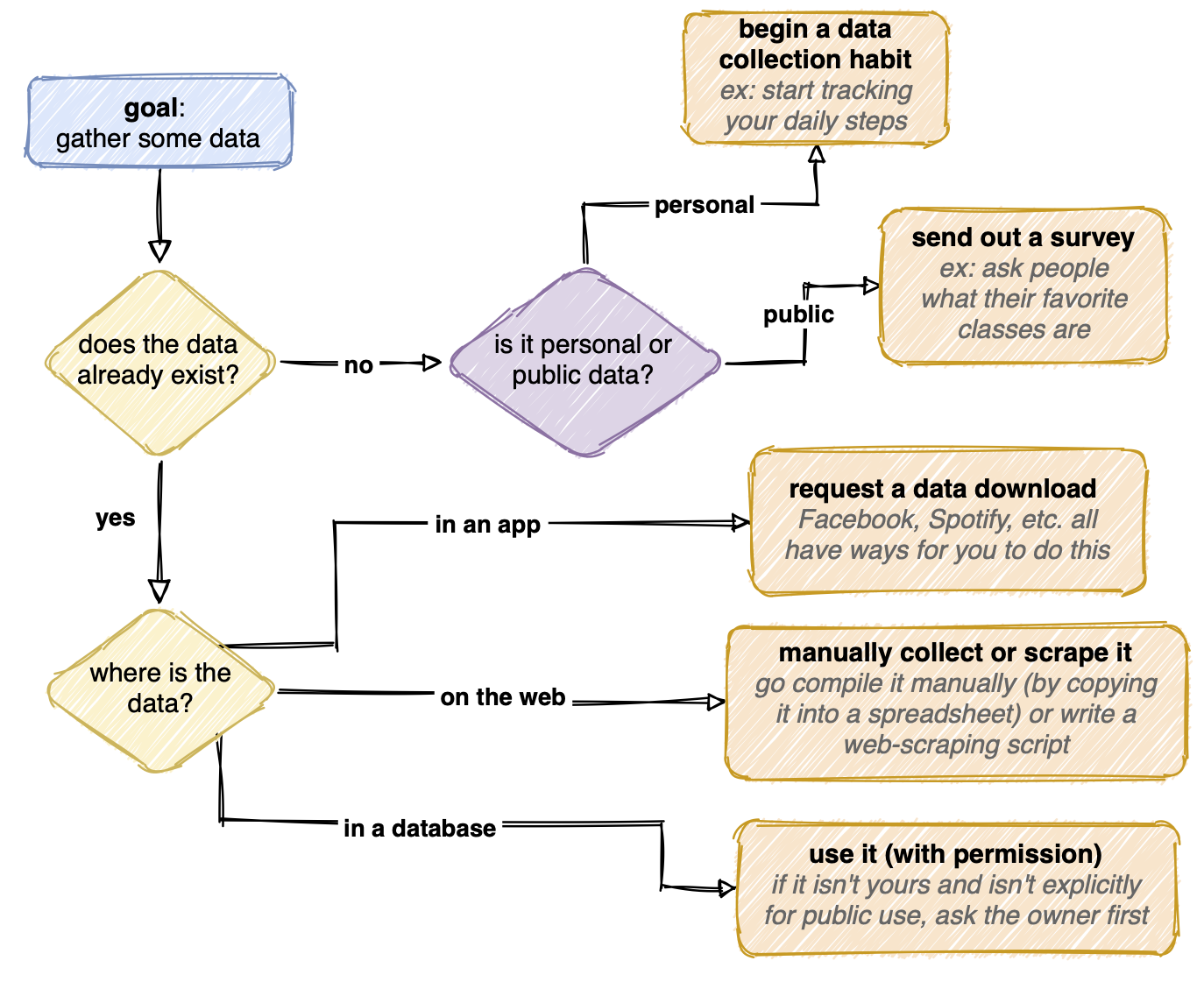
indsamling af data kan være ligetil eller ret kedelig. Dataene findes muligvis allerede, pænt samlet i en database. Hvis databasen er offentlig, er jeg færdig med dette trin! Hvis det er privat, sender jeg generelt en anmodning til ejeren om at bruge den. Hvis dataene er inde i en app som Facebook, ser jeg efter måder, hvorpå jeg kan anmode om en dataoverførsel. Dataene kunne også eksistere et sted lidt mere ubelejligt (spredt rundt på nettet, for eksempel), og jeg skulle indsamle det.
hvis dataene ikke findes endnu, kan jeg begynde at oprette dem. Hvis det spørgsmål, jeg forsøger at svare på, er mere personligt, kan jeg begynde at spore noget i mit liv, enten automatisk (som med et trinoptællingsur) eller manuelt (som at optage, hvad Netfleks viser, jeg ser hver nat). Eller hvis dataene handler om andre mennesker, kunne jeg gennemføre et eksperiment eller sende en undersøgelse.
her er et rutediagram, jeg lavede, der opsummerer, hvordan jeg kan gå om at få data:
rengør dataene

dataene kommer sjældent klar til at analysere. For at gøre det klar, skal jeg “rense” det.
hvad betyder det, at dataene ikke er klar til at analysere? Måske er der mange data, der ikke vedrører mit spørgsmål. Måske er dataene repræsenteret på en virkelig uorganiseret eller inkonsekvent måde. Rengøring kan betyde at udtrække den relevante delmængde af dataene, organisere dem og ændre, hvordan de er repræsenteret for at skabe en mere ligetil analyse.
for eksempel i dormspam-the-game (Del 1) bestod dataene af en liste over steder, hvor hver spiller (i et virtuelt spil skjul og søg) valgte at skjule og søge. Der var dog nogle poster i databasen, der blev stavet forkert, hvilket forårsagede fejl i min kode, da den forsøgte at gentage over en liste over placeringer. Jeg var nødt til at erstatte disse poster med korrekt stavede versioner af placeringen.
gør nogle dataanalyse!
jeg bruger generelt Python til at skrive scripts til at analysere og visualisere mine data. Jeg har lagt noget af min kode offentligt på Github, så du kan se på det. Python er dog ikke den eneste mulighed. Du kan også bruge en række andre scriptsprog, der har gode analyse-og visualiseringsværktøjer. Du kan også gå no-kode og bruge regnearksfunktioner. Med det sagt, her er hvordan jeg arbejder med Python:
- Jeg kan godt lide at bruge Jupyter Notebooks (eller Google Colab notebooks). Jeg kan godt lide disse bedre end en rå tekstfil, fordi de giver mulighed for markeringsnoter/dokumentation og visualiseringer at eksistere sammen med din kode ganske pænt. Hvis jeg planlægger mine analyser, lærer at bruge et nyt værktøj eller refererer til et tidligere resultat, er det rart, at jeg bare kan rulle rundt for at se på noter/output/plots inde i min notesbog i stedet for en ekstern reference.
- jeg er stærkt afhængig af pakker. Jeg importerer næsten altid Pandas, Numpy og Matplotlib til håndtering og organisering af mine data, udførelse af grundlæggende statistiske og matematiske operationer og udførelse af grundlæggende visualiseringer. På projekt-for-projekt-basis importerer jeg også yderligere pakker for at få adgang til specielle modeller og visualiseringer, der kan være relevante.
- jeg starter med at indlæse mine data. Jeg kan indlæse den lokalt fra en fil på min computer. Eller oftere, hvad jeg gør er at uploade det til Google Sheets, bruge funktionen “Udgiv til internettet” til at generere et link til en CSV, og brug derefter dette link til at indlæse mine data. Jeg foretrækker at bruge google sheets over en lokal fil, fordi den har pænere Versionshistorik og samarbejdsfunktioner.
- dernæst deltager jeg i en iterativ proces, hvor jeg antager en tendens i dataene, foretager en analyse for at undersøge hypotesen og derefter bruge resultaterne til at generere flere hypoteser. Med virkelig interessante eller ulige data kan denne proces fortsætte i et stykke tid.
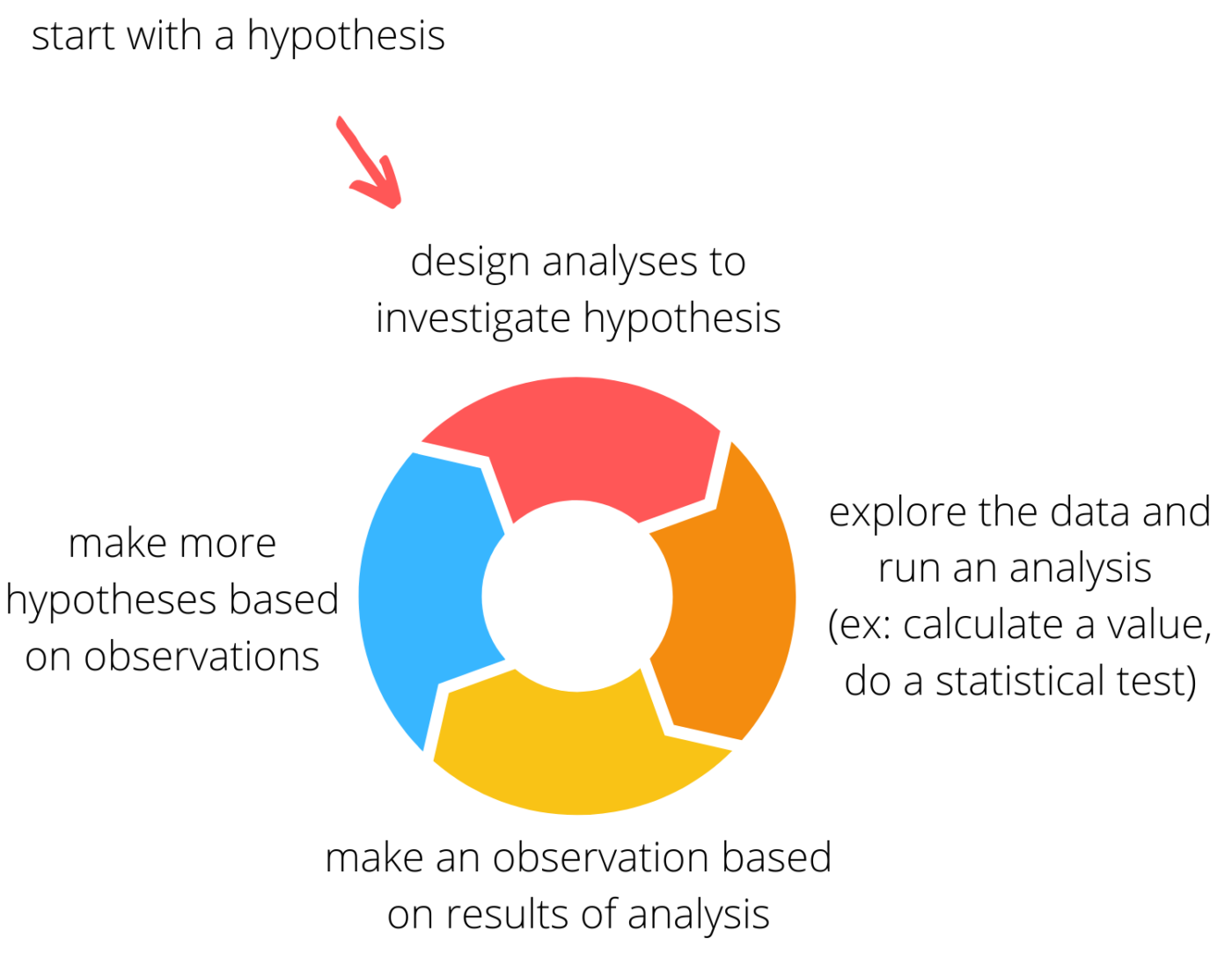
lav nogle plot
når jeg analyserer dataene, er en nyttig måde at få øje på kølige mønstre at lave visualiseringer. Jeg kan gøre dette med en række grafer. Mit første plot er ofte ret grimt. Jeg kan bruge forskellige funktioner i mit plottebibliotek for at gøre det bedre at fremhæve dataene, både videnskabeligt og æstetisk. For eksempel kan jeg justere farverne og størrelsen af datapunkter, linjer og søjler for bedre at demonstrere tendenser. Jeg kan ændre den måde, hvorpå h-og Y-aksen er repræsenteret for at få plottet til at se renere ud.
bortset fra at lave statiske plot, kan jeg lejlighedsvis lide at animere plot (se Green Building Challenge og dormspam-the-game (Del 1)). At lave plots er en kreativ proces, især når man opretter animerede, hvor funktioner som farve og størrelse kan tjene et andet formål, end de måske i et statisk plot.
gør visualiseringer er min favorit del af processen. Jeg elsker at lade mine kunstneriske og tekniske sider komme sammen.
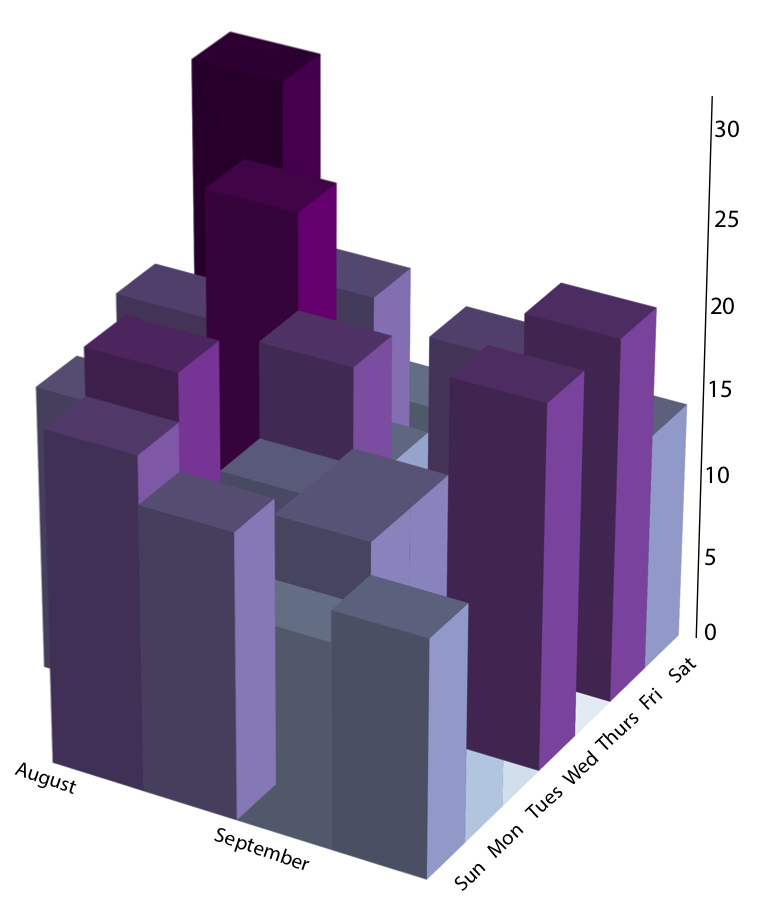
et plot fra mit første blogindlæg nogensinde, der viser antallet af trin, jeg tog, i tusinder, i mine første par uger på MIT
Fortæl en historie
det er vigtigt at tænke over, hvordan mine dataanalyser og visualiseringer kan bidrage til at fortælle en historie om den tendens, jeg undersøger eller fænomen, jeg kvantificerer. Jeg forsøger at lave plot på en måde, der gør det muligt for hvert plot at vise en ny del af historien. Jeg forsøger at bestille dem mine plots mine indlæg på en måde, at hver mine ord og mine plots sammen gradvist fortælle en historie om, hvad der foregår. For eksempel, når jeg har visualiseret dataene fra et spil, kan jeg først beskrive spillereglerne, derefter beskrive hvem der vandt, og derefter dykke ned i at forstå, hvordan forskellige spillerstrategier påvirkede resultatet.
så det er stort set, hvordan jeg går om at skrive mine dataanalyse blogs. Jeg adskilt det i 6 trin, men at tænke “baglæns” snarere end strengt trin for trin kan hjælpe med at gøre dit arbejde i tidligere trin mere meningsfuldt. Hvis du tænker på, hvordan du gør historien overbevisende, kan du lave bedre visualiseringer. Hvis du ved, hvilke visualiseringer du måske vil foretage, kan du bedre dirigere din dataindsamling.
Leave a Reply