leksikalsk analyse i Compiler
leksikalsk analyse i compiler er det første trin i analysen af kildeprogrammet. Den leksikalske analyse læser inputstrømmen fra kildeprogrammet tegn efter tegn og producerer sekvensen af tokens. Disse tokens leveres som et input til parseren til parsing. I denne sammenhæng vil vi diskutere processen med leksikalsk analyse kort sammen med de leksikalske fejl og deres opsving.
indhold: Leksikalsk analyse i Compiler
- terminologier i leksikalsk analyse
- Hvad er leksikalsk analyse?
- eksempler på leksikalsk analyse
- leksikalsk analysator
- leksikalsk fejl
- fejlgendannelse
- nøgle grillbarer
terminologier i leksikalsk analyse
før vi går ind i, hvad leksikalsk analyse er, hvordan den udføres, lad os tale om nogle terminologier, som vi vil støde på, mens vi diskuterer leksikalsk analyse.
- Lekseme
Lekseme kan defineres som en sekvens af tegn, der danner et mønster og kan genkendes som et token. - mønster
efter at have identificeret mønsteret af leksemet kan man beskrive, hvilken slags token der kan dannes. Såsom mønsteret for nogle leksemer danner et nøgleord, mønsteret for nogle leksemer danner en identifikator. - Token
et leksem med et gyldigt mønster danner et token. I leksikalsk analyse kan et gyldigt token være identifikatorer, nøgleord, separatorer, specialtegn, konstanter og operatører.
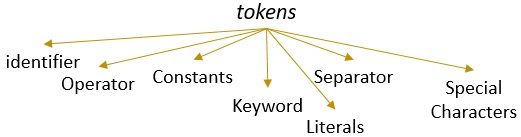
Hvad er leksikalsk analyse?
tidligere har vi nedlagt leksikalsk analysator i vores indhold compiler i computer. Vi har lært, at kompilatoren udfører analysen af kildeprogrammet gennem forskellige faser for at omdanne det til målprogrammet. Den leksikalske analyse er den første fase, som kildeprogrammet skal gennemgå.
den leksikalske analyse er processen med tokenisering dvs. det læser inputstrengen for et kildeprogramkarakter efter tegn, og så snart det identificerer en ende af leksemet, identificerer det dets mønster og konverterer det til et token.
den leksikale analysator består af to på hinanden følgende processer, der inkluderer scanning og leksikalsk analyse.
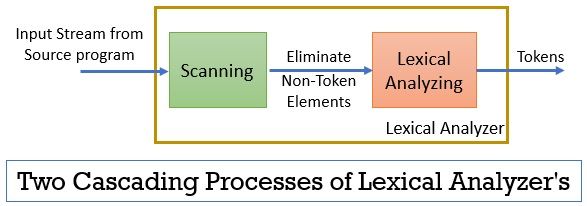
- Scanning: scanningsfasen-fjerner kun de ikke-token-elementer fra kildeprogrammet. Såsom at fjerne kommentarer, komprimering af de på hinanden følgende hvide rum osv.
- Leksikalsk Analyse: Leksikalsk analysefase udfører tokeniseringen på udgangen leveret af scanneren og producerer derved tokens.
det program, der bruges til at udføre leksikalsk analyse, kaldes leksikalsk eller leksikalsk analysator. Lad os nu tage et eksempel på leksikalsk analyse udført på en erklæring:
eksempel 1 af leksikalsk analyse:
leksikalsk analyse i compiler design, identificere tokens.
nu, når vi læser denne erklæring, kan vi let identificere, at der er ni tokens i ovenstående erklæring.
- identifikatorer – > leksikalsk
- identifikatorer – > analyse
- identifikatorer – > i
- identifikatorer – > compiler
- identifikatorer – > design
- Separator -> ,
- identifikatorer – > Identificer
- identifikatorer- > tokens
- Separator- >.
så som i alt er der 9 tokens i ovenstående strøm af tegn.
eksempel 2 på leksikalsk analyse:
printf(” værdi af i er %d “, i);
lad os nu prøve at finde tokens ud af denne inputstrøm.
- nøgleord – > printf
- specialtegn -> (
- bogstavelig – > “værdi af i er %d”
- Separator -> ,
- identifikator – > i
- specialtegn -> )
- Separator -> ;
Bemærk:
- hele strengen inde i de dobbelte inverterede kommaer, dvs. “” betragtes som et enkelt token.
- det tomme hvide rum, der adskiller tegnene i inputstrømmen, adskiller kun tokens og dermed elimineres det, mens man tæller tokens.
leksikalsk analysators rolle
som den første fase i analysen af kildeprogrammet spiller den leksikale analysator en vigtig rolle i transformationen af kildeprogrammet til målprogrammet.
hele dette scenario kan realiseres ved hjælp af nedenstående figur:
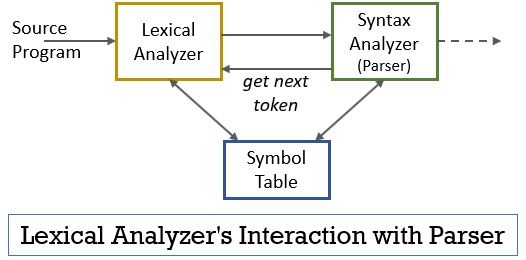
- den leksikalske analysatorfase har scanneren eller lekserprogrammet implementeret i det, der kun producerer tokens, når de er befalet af parseren til at gøre det.
- parseren genererer kommandoen getnekstoken og sender den til den leksikale analysator som et svar på dette begynder den leksikale analysator at læse inputstrømmen tegn for tegn, indtil den identificerer et lekseme, der kan genkendes som et token.
- så snart et token er produceret, sender den leksikale analysator den til syntaksanalysatoren til parsing.
- sammen med syntaksanalysatoren kommunikerer den leksikale analysator også med symboltabellen. Når en leksikalsk analysator identificerer et lekseme som en identifikator, indtaster det leksemet i symboltabellen.
- nogle gange hjælper identifikationsoplysningerne i symboltabellen leksikalsk analysator med at bestemme det token, der skal sendes til parseren.
- bortset fra at identificere tokens i inputstrømmen eliminerer den leksikale analysator også det tomme rum/det hvide rum og programmets kommentarer. Sådanne andre ting omfatter tegn de adskiller tokens, faner, tomme mellemrum, nye linjer.
- den leksikalske analysator hjælper med at relatere fejlmeddelelserne produceret af kompilatoren. Bare for eksempel holder den leksikale analysator registreringen af hvert nyt linjetegn, det kommer på tværs af, mens du scanner kildeprogrammet, så det nemt relaterer fejlmeddelelsen til kildeprogrammets linjenummer.
- hvis kildeprogrammet bruger makroer, udvider den leksikale analysator makroerne i kildeprogrammet.
leksikalsk fejl
den leksikale analysator i sig selv er ikke effektiv til at bestemme fejlen fra kildeprogrammet. Overvej for eksempel en erklæring:
prtf (“værdi af i er %d”, i);
i ovenstående erklæring, når strengen prtf er stødt på, kan den leksikale analysator ikke gætte, om prtf er en forkert stavning af nøgleordet ‘printf’ eller det er en sort funktionsidentifikator.
men ifølge den foruddefinerede regel er prtf et gyldigt leksem, hvis mønster konkluderer, at det er et identifikator-token. Nu sender den leksikale analysator prtf-token til næste fase, dvs.parser, der håndterer den fejl, der opstod på grund af transponering af bogstaver.
fejlgendannelse
nå, nogle gange er det endda umuligt for en leksikalsk analysator at identificere et lekseme som et token, da leksemets mønster ikke matcher nogen af de foruddefinerede mønstre for tokens. I dette tilfælde skal vi anvende nogle fejlgendannelsesstrategier.
- i Panic mode recovery slettes det successive tegn fra leksemet, indtil den leksikale analysator identificerer et gyldigt token.
- fjern det første tegn fra det resterende input.
- Identificer det mulige manglende tegn, og indsæt det korrekt i det resterende input.
- Udskift et tegn i det resterende input for at få et gyldigt token.
- udveksle placeringen af to tilstødende tegn i det resterende input.
under udførelsen af ovenstående fejlgendannelseshandlinger skal du kontrollere, om præfikset for det resterende input matcher ethvert mønster af tokens. Generelt opstår der en leksikalsk fejl på grund af et enkelt tegn. Så du kan rette den leksikalske fejl med en enkelt transformation. Og så vidt muligt skal et mindre antal transformationer konvertere kildeprogrammet til en række gyldige tokens, som det kan overdrage til parseren.
nøgle grillbarer
- leksikalsk analyse er den første fase i analysen af kildeprogrammet i kompilatoren.
- den leksikalske analysator implementeres ved to på hinanden følgende processer scanner og leksikalsk analyse.
- Scanner eliminerer ikke-token elementer fra input stream.
- leksikalsk analyse udfører tokenisering.
- således genererer den leksikale analysator en sekvens af tokens og videresender dem til parseren.
- parseren om at have et token fra den leksikalske analysator foretager et opkald getnekstoken, der insisterer på, at den leksikale analysator læser indtastningsstrømmen af tegn, indtil den identificerer det næste token.
- hvis den leksikale analysator identificerer mønsteret af et lekseme som en identifikator, indtaster den leksikale analysator det lekseme i symboltabellen til fremtidig brug.
- leksikalsk analysator er ikke effektiv til at identificere nogen fejl i kildeprogrammet alene.
- hvis der opstår et lekseme, hvis mønster ikke svarer til nogen af de foruddefinerede mønstre af tokens, skal du udføre fejlgendannelseshandlinger for at rette fejlen.
så det handler om den leksikalske analyse, som omdanner strømmen af tegn til tokens og sender den til parseren. Vi har lært om leksikalsk analyse ved hjælp af et eksempel. Vi har afsluttet diskussionen med den leksikale fejl og dens genopretningsstrategi.
Leave a Reply