Datenvalidierung und Datenverifizierung – Vom Wörterbuch zum maschinellen Lernen
Von Aditya Aggarwal, Advanced Analytics Practice Lead, und Arnab Bose, Chief Scientific Officer, Abzooba
Sehr oft verwenden wir Datenverifizierung und Datenvalidierung synonym, wenn wir über Datenqualität sprechen. Diese beiden Begriffe sind jedoch unterschiedlich. In diesem Artikel werden wir den Unterschied in 4 verschiedenen Kontexten verstehen:
- Wörterbuchbedeutung von Verifikation und Validierung
- Unterschied zwischen Datenverifizierung und Datenvalidierung im Allgemeinen
- Unterschied zwischen Verifikation und Validierung aus Sicht der Softwareentwicklung
- Unterschied zwischen Datenverifizierung und Datenvalidierung aus Sicht des maschinellen Lernens
Wörterbuchbedeutung von Verifikation und Validierung
Tabelle 1 erläutert die Bedeutung der Wörter Verifikation und Validierung anhand einiger Beispiele.

Zusammenfassend lässt sich sagen, dass es bei der Verifizierung um Wahrheit und Genauigkeit geht, während es bei der Validierung darum geht, die Stärke eines Standpunkts oder die Richtigkeit eines Anspruchs zu unterstützen. Die Validierung überprüft die Richtigkeit einer Methodik, während die Verifizierung die Genauigkeit der Ergebnisse überprüft.
Unterschied zwischen Datenüberprüfung und Datenvalidierung im Allgemeinen
Nachdem wir nun die wörtliche Bedeutung der beiden Wörter verstanden haben, wollen wir den Unterschied zwischen “Datenüberprüfung” und “Datenvalidierung” untersuchen.
- Datenüberprüfung: um sicherzustellen, dass die Daten korrekt sind.
- Datenvalidierung: um sicherzustellen, dass die Daten korrekt sind.
Lassen Sie uns anhand von Beispielen in Tabelle 2 näher darauf eingehen.

Unterschied zwischen Verifikation und Validierung aus Sicht der Softwareentwicklung
Aus Sicht der Softwareentwicklung,
- Die Überprüfung erfolgt, um sicherzustellen, dass die Software von hoher Qualität, ausgereift, robust und fehlerfrei ist, ohne in die Benutzerfreundlichkeit einzugreifen.
- Die Validierung wird durchgeführt, um die Benutzerfreundlichkeit der Software und die Fähigkeit zur Erfüllung der Kundenbedürfnisse sicherzustellen.
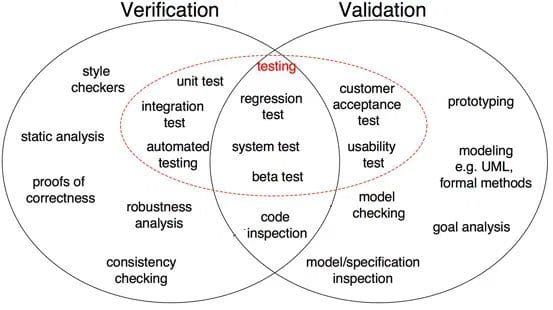
Abb. 1: Unterschiede zwischen Verifikation und Validierung in der Softwareentwicklung (Quelle)
Wie in Abbildung 1 gezeigt, sind Korrektheitsnachweis, Robustheitsanalyse, Komponententests, Integrationstest und andere Verifizierungsschritte, bei denen Aufgaben darauf ausgerichtet sind, Besonderheiten zu überprüfen. Die Softwareausgabe wird mit der gewünschten Ausgabe verglichen. Auf der anderen Seite sind Modellinspektion, Black-Box-Tests und Usability-Tests Validierungsschritte, bei denen die Aufgaben darauf ausgerichtet sind zu verstehen, ob die Software die Anforderungen und Erwartungen erfüllt.
Unterschied zwischen Datenüberprüfung und Datenvalidierung aus Sicht des maschinellen Lernens
Die Rolle der Datenüberprüfung in der Pipeline des maschinellen Lernens ist die eines Gatekeeper. Es sorgt für genaue und aktualisierte Daten im Laufe der Zeit. Die Datenüberprüfung erfolgt in erster Linie in der neuen Datenerfassungsstufe, d. H. in Schritt 8 der ML-Pipeline, wie in Fig. 2. Beispiele für diesen Schritt sind das Identifizieren doppelter Datensätze und das Durchführen einer Deduplizierung sowie das Bereinigen von Nichtübereinstimmungen in Kundeninformationen in Feldern wie Adresse oder Telefonnummer.
Andererseits stellt die Datenvalidierung (in Schritt 3 der ML-Pipeline) sicher, dass die inkrementellen Daten aus Schritt 8, die zu den Lerndaten hinzugefügt werden, von guter Qualität sind und (aus Sicht der statistischen Eigenschaften) den vorhandenen Trainingsdaten ähnlich sind. Dies umfasst beispielsweise das Auffinden von Datenanomalien oder das Erkennen von Unterschieden zwischen vorhandenen Trainingsdaten und neuen Daten, die den Trainingsdaten hinzugefügt werden sollen. Andernfalls können Datenqualitätsprobleme / statistische Unterschiede in inkrementellen Daten übersehen werden, und Trainingsfehler können sich im Laufe der Zeit ansammeln und die Modellgenauigkeit beeinträchtigen. Somit erkennt die Datenvalidierung signifikante Änderungen (falls vorhanden) in inkrementellen Trainingsdaten in einem frühen Stadium, das bei der Ursachenanalyse hilft.
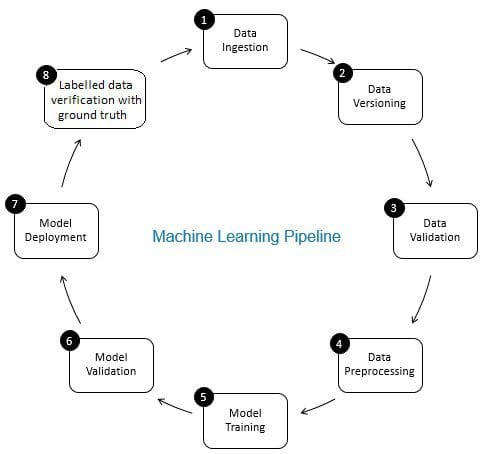
Abbildung 2: Komponenten der Pipeline für maschinelles Lernen
Aditya Aggarwal ist Data Science – Practice Lead bei Abzooba Inc. Mit mehr als 12 Jahren Erfahrung in der Erreichung von Geschäftszielen durch datengesteuerte Lösungen ist Aditya auf Predictive Analytics, Machine Learning, Business Intelligence & Business Strategy in einer Reihe von Branchen spezialisiert.
Dr. Arnab Bose ist Chief Scientific Officer bei Abzooba, einem Datenanalyseunternehmen und einer außerordentlichen Fakultät an der University of Chicago, wo er Maschinelles Lernen und prädiktive Analytik, maschinelle Lernoperationen, Zeitreihenanalyse und -prognose sowie Gesundheitsanalytik im Master of Science in Analytics unterrichtet Programm. Er ist ein 20-jähriger Veteran der Predictive Analytics-Branche, der gerne unstrukturierte und strukturierte Daten verwendet, um Verhaltensergebnisse in den Bereichen Gesundheitswesen, Einzelhandel, Finanzen und Transport zu prognostizieren und zu beeinflussen. Zu seinen aktuellen Schwerpunkten gehören die Stratifizierung von Gesundheitsrisiken und das Management chronischer Krankheiten mithilfe von maschinellem Lernen sowie die Bereitstellung und Überwachung von maschinellen Lernmodellen in der Produktion.
Verwandt:
- MLOps – “Warum ist es erforderlich?” und “Was es ist”?
- Mein maschinelles Lernmodell lernt nicht. Was soll ich tun?
- Datenbeobachtbarkeit, Teil II: Erstellen eigener Datenqualitätsmonitore mit SQL
Leave a Reply