Lexikalische Analyse im Compiler
Die lexikalische Analyse im Compiler ist der erste Schritt bei der Analyse des Quellprogramms. Die lexikalische Analyse liest den Eingabestrom zeichenweise aus dem Quellprogramm und erzeugt die Sequenz von Token. Diese Token werden als Eingabe für den Parser zum Parsen bereitgestellt. In diesem Zusammenhang werden wir den Prozess der lexikalischen Analyse in Kürze zusammen mit den lexikalischen Fehlern und deren Wiederherstellung diskutieren.
Inhalt: Lexikalische Analyse im Compiler
- Terminologien in der lexikalischen Analyse
- Was ist lexikalische Analyse?
- Beispiele für lexikalische Analyse
- Rolle des lexikalischen Analysators
- Lexikalischer Fehler
- Fehlerbehebung
- Wichtige Erkenntnisse
Terminologien in der lexikalischen Analyse
Bevor wir uns mit der lexikalischen Analyse befassen, lassen Sie uns über einige Terminologien sprechen, auf die wir bei der Erörterung der lexikalischen Analyse stoßen werden.
- Lexem
Lexem kann als eine Folge von Zeichen definiert werden, die ein Muster bildet und als Token erkannt werden kann. - Muster
Nachdem man das Muster des Lexems identifiziert hat, kann man beschreiben, welche Art von Token gebildet werden kann. Wie das Muster eines Lexems ein Schlüsselwort bildet, bildet das Muster einiger Lexeme eine Kennung. - Token
Ein Lexem mit einem gültigen Muster bildet ein Token. In der lexikalischen Analyse kann ein gültiges Token Bezeichner, Schlüsselwörter, Trennzeichen, Sonderzeichen, Konstanten und Operatoren sein.
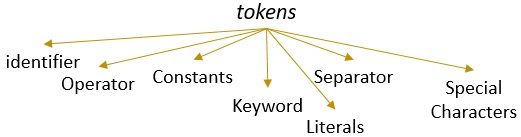
Was ist lexikalische Analyse?
Früher haben wir den lexikalischen Analysator in unserem Inhalts-Compiler im Computer nicht mehr verwendet. Wir haben gelernt, dass der Compiler die Analyse des Quellprogramms in verschiedenen Phasen durchführt, um es in das Zielprogramm umzuwandeln. Die lexikalische Analyse ist die erste Phase, die das Quellprogramm durchlaufen muss.
Die lexikalische Analyse ist der Prozess der Tokenisierung, d.h. es liest die Eingabezeichenfolge eines Quellprogramms Zeichen für Zeichen und sobald es ein Ende des Lexems identifiziert, identifiziert es sein Muster und konvertiert es in ein Token.
Der lexikalische Analysator besteht aus zwei aufeinanderfolgenden Prozessen, die das Scannen und die lexikalische Analyse umfassen.
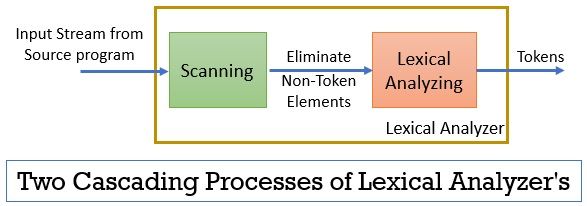
- Scannen: Die Scan-Phase-nur beseitigt die Nicht-Token-Elemente aus dem Quellprogramm. Wie das Entfernen von Kommentaren, das Komprimieren der aufeinanderfolgenden Leerzeichen usw.
- Lexikalische Analyse: Die lexikalische Analysephase führt die Tokenisierung an der vom Scanner bereitgestellten Ausgabe durch und erzeugt dadurch Token.
Das Programm zur Durchführung der lexikalischen Analyse wird als Lexer oder lexikalischer Analysator bezeichnet. Nehmen wir nun ein Beispiel für die lexikalische Analyse einer Anweisung:
Beispiel 1 der lexikalischen Analyse:
Lexikalische Analyse im Compiler-Design, Token identifizieren.
Wenn wir nun diese Aussage lesen, können wir leicht erkennen, dass die obige Aussage neun Token enthält.
- Bezeichner -> lexikalisch
- Bezeichner -> Analyse
- Bezeichner -> in
- Bezeichner -> Compiler
- Bezeichner -> Entwurf
- Trennzeichen -> ,
- Bezeichner -> identifizieren
- Bezeichner -> Token
- Trennzeichen -> .
Insgesamt befinden sich also 9 Token im obigen Zeichenstrom.
Beispiel 2 der lexikalischen Analyse:
printf(” Wert von i ist%d “, i);
Versuchen wir nun, Token aus diesem Eingabestrom zu finden.
- Schlüsselwort -> printf
- Sonderzeichen -> (
- Literal -> “Wert von i ist %d “
- Trennzeichen -> ,
- Kennung -> i
- Sonderzeichen -> )
- Trennzeichen -> ;
Hinweis:
- Die gesamte Zeichenfolge innerhalb der doppelten Anführungszeichen, dh ” “, wird als einzelnes Token betrachtet.
- Der leere Leerraum, der die Zeichen im Eingabestrom trennt, trennt nur die Token und wird daher beim Zählen der Token eliminiert.
Rolle des lexikalischen Analysators
Als erste Phase in der Analyse des Quellprogramms spielt der lexikalische Analysator eine wichtige Rolle bei der Umwandlung des Quellprogramms in das Zielprogramm.
Dieses gesamte Szenario kann mit Hilfe der folgenden Abbildung realisiert werden:
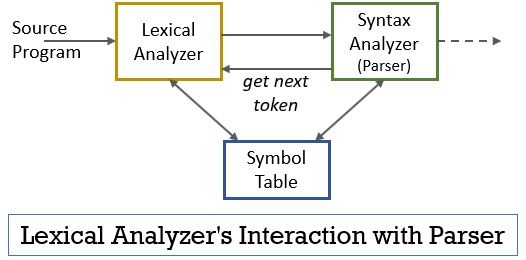
- In der lexikalischen Analysephase ist das Scanner- oder Lexer-Programm implementiert, das Token nur dann erzeugt, wenn sie vom Parser dazu aufgefordert werden.
- Der Parser generiert den Befehl getNextToken und sendet ihn als Antwort darauf an den lexikalischen Analysator Der lexikalische Analysator beginnt, den Eingabestrom zeichenweise zu lesen, bis er ein Lexem identifiziert, das als Token erkannt werden kann.
- Sobald ein Token erzeugt wird, sendet der lexikalische Analysator es zum Parsen an den Syntaxanalysator.
- Neben dem Syntaxanalysator kommuniziert der lexikalische Analysator auch mit der Symboltabelle. Wenn ein lexikalischer Analysator ein Lexem als Bezeichner identifiziert, gibt er dieses Lexem in die Symboltabelle ein.
- Manchmal hilft die Information der Kennung in der Symboltabelle dem lexikalischen Analysator bei der Bestimmung des Tokens, das an den Parser gesendet werden muss.
- Abgesehen von der Identifizierung der Token im Eingabestrom eliminiert der lexikalische Analysator auch den Leerraum / Leerraum und die Kommentare des Programms. Zu diesen anderen Dingen gehören Zeichen, die Token, Tabulatoren, Leerzeichen und neue Zeilen trennen.
- Der lexikalische Analysator hilft bei der Zuordnung der vom Compiler erzeugten Fehlermeldungen. Nur zum Beispiel hält der lexikalische Analysator die Aufzeichnung jedes neuen Zeilenzeichens, auf das er beim Scannen des Quellprogramms stößt, so dass er die Fehlermeldung leicht mit der Zeilennummer des Quellprogramms in Beziehung setzt.
- Wenn das Quellprogramm Makros verwendet, erweitert der Lexical Analyzer die Makros im Quellprogramm.
Lexikalischer Fehler
Der lexikalische Analysator selbst ist nicht effizient, um den Fehler aus dem Quellprogramm zu ermitteln. Betrachten Sie beispielsweise eine Anweisung:
prtf(” Wert von i ist %d “, i);
Nun kann der lexikalische Analysator in der obigen Anweisung, wenn die Zeichenfolge prtf angetroffen wird, nicht erraten, ob die prtf eine falsche Schreibweise des Schlüsselworts ‘printf’ oder eine nicht deklarierte Funktionskennung ist.
Aber gemäß der vordefinierten Regel ist prtf ein gültiges Lexem, dessen Muster es zu einem Bezeichner-Token macht. Jetzt sendet der lexikalische Analysator das prtf-Token an die nächste Phase, dh an den Parser, der den Fehler behandelt, der aufgrund der Transposition von Buchstaben aufgetreten ist.
Fehlerbehebung
Nun, manchmal ist es für einen lexikalischen Analysator sogar unmöglich, ein Lexem als Token zu identifizieren, da das Muster des Lexems keinem der vordefinierten Muster für Token entspricht. In diesem Fall müssen wir einige Fehlerbehebungsstrategien anwenden.
- Im Panikmodus wird das nachfolgende Zeichen aus dem Lexem gelöscht, bis der lexikalische Analysator ein gültiges Token identifiziert.
- Entfernen Sie das erste Zeichen aus der verbleibenden Eingabe.
- Identifizieren Sie das möglicherweise fehlende Zeichen und fügen Sie es entsprechend in die verbleibende Eingabe ein.
- Ersetzen Sie ein Zeichen in der verbleibenden Eingabe, um ein gültiges Token zu erhalten.
- Tauschen Sie die Position zweier benachbarter Zeichen in der verbleibenden Eingabe aus.
Überprüfen Sie beim Ausführen der obigen Fehlerbehebungsaktionen, ob das Präfix der verbleibenden Eingabe mit einem Token-Muster übereinstimmt. Im Allgemeinen tritt ein lexikalischer Fehler aufgrund eines einzelnen Zeichens auf. So können Sie den lexikalischen Fehler mit einer einzigen Transformation korrigieren. Und so weit wie möglich muss eine kleinere Anzahl von Transformationen das Quellprogramm in eine Folge gültiger Token konvertieren, die es an den Parser übergeben kann.
Wichtige Erkenntnisse
- Die lexikalische Analyse ist die erste Phase bei der Analyse des Quellprogramms im Compiler.
- Der lexikalische Analysator wird durch zwei aufeinanderfolgende Prozesse Scanner und lexikalische Analyse implementiert.
- Scanner eliminiert die Nicht-Token-Elemente aus dem Eingabestream.
- Die lexikalische Analyse führt eine Tokenisierung durch.
- Somit generiert der lexikalische Analysator eine Folge von Token und leitet sie an den Parser weiter.
- Der Parser, der ein Token vom lexikalischen Analysator besitzt, ruft getNextToken auf, das den lexikalischen Analysator dazu bringt, den Eingabestrom von Zeichen zu lesen, bis er das nächste Token identifiziert.
- Wenn der lexikalische Analysator das Muster eines Lexems als Bezeichner identifiziert, gibt der lexikalische Analysator dieses Lexem zur zukünftigen Verwendung in die Symboltabelle ein.
- Lexical Analyzer ist nicht effizient, um Fehler im Quellprogramm allein zu identifizieren.
- Wenn ein Lexem auftritt, dessen Muster keinem der vordefinierten Token-Muster entspricht, müssen Sie Fehlerbehebungsaktionen durchführen, um den Fehler zu beheben.
Hier geht es also um die lexikalische Analyse, die den Zeichenstrom in Token umwandelt und an den Parser weitergibt. Wir haben die Funktionsweise der lexikalischen Analyse anhand eines Beispiels kennengelernt. Wir haben die Diskussion mit dem lexikalischen Fehler und seiner Wiederherstellungsstrategie abgeschlossen.
Leave a Reply