Routing-Tabellen
Eine Routingtabelle ist eine Gruppierung von Informationen, die auf einem Netzwerkcomputer oder Netzwerkrouter gespeichert sind und eine Liste von Routen zu verschiedenen Netzwerkzielen enthalten. Die Daten werden normalerweise in einer Datenbanktabelle gespeichert und enthalten in erweiterten Konfigurationen Leistungsmetriken, die den in der Tabelle gespeicherten Routen zugeordnet sind. Weitere in der Tabelle gespeicherte Informationen umfassen die Netzwerktopologie, die dem Router am nächsten liegt. Obwohl eine Routingtabelle routinemäßig durch Netzwerkroutingprotokolle aktualisiert wird, können statische Einträge durch manuelle Aktionen eines Netzwerkadministrators vorgenommen werden.
Wie funktioniert eine Routing-Tabelle?
Routing-Tabellen funktionieren ähnlich wie die Zustellung von Postsendungen durch die Post. Wenn ein Netzwerkknoten im Internet oder ein lokales Netzwerk Informationen an einen anderen Knoten senden muss, ist zunächst eine allgemeine Vorstellung davon erforderlich, wohin die Informationen gesendet werden sollen. Wenn der Zielknoten oder die Adresse nicht direkt mit dem Netzwerkknoten verbunden ist, müssen die Informationen über andere Netzwerkknoten gesendet werden. Um Ressourcen zu sparen, führen die meisten lokalen Netzwerkknoten keine komplexe Routing-Tabelle. Stattdessen senden sie IP-Informationspakete an ein lokales Netzwerkgateway. Das Gateway verwaltet die primäre Routingtabelle für das Netzwerk und sendet das Datenpaket an den gewünschten Ort. Um eine Aufzeichnung darüber zu führen, wie Informationen weitergeleitet werden, verwendet das Gateway eine Routingtabelle, die das geeignete Ziel für ausgehende Datenpakete verfolgt.
Alle Routingtabellen verwalten Routingtabellenlisten für die vom Standort des Routers aus erreichbaren Ziele. Dazu gehört die Adresse des nächsten vernetzten Geräts auf dem Netzwerkpfad zur Zieladresse, die auch als “nächster Hop” bezeichnet wird.” Durch die Aufrechterhaltung genauer und konsistenter Informationen über Netzwerkknoten reicht das Senden eines Datenpakets auf dem kürzesten Weg zur Zieladresse im Internet normalerweise aus, um Netzwerkverkehr bereitzustellen, und ist eines der grundlegenden Merkmale der OSI-Netzwerk- und IP-Netzwerkschichten der Netzwerktheorie.
Was ist die Hauptfunktion eines Netzwerk-Routers?
Die Hauptfunktion eines Netzwerkrouters besteht darin, Datenpakete an das Zielnetzwerk weiterzuleiten, das in der Ziel-IP-Adresse des ausgehenden Datenpakets enthalten ist. Um das geeignete Ziel des Datenpakets zu bestimmen, führt der Router eine Suche der in der Routingtabelle gespeicherten Zieladressen durch. Die Routingtabelle ist im RAM des Gateway-Routers des Netzwerks gespeichert und enthält Informationen über Zielnetzwerke und die “Next Hop” -Zuordnungen für diese Adresse. Diese Informationen helfen dem Router, den besten ausgehenden Speicherort für das zu sendende Datenpaket zu bestimmen und zu identifizieren, um das ultimative Netzwerkziel zu finden. Dieser Ort kann auch die Gateway-Schnittstelle von direkt verbundenen Netzwerken sein.
Was ist ein direkt verbundenes Netzwerk?
Direkt angeschlossene Netzwerke sind an eine der Router-Schnittstellen eines lokalen Netzwerks angeschlossen. Da die Router-Schnittstelle normalerweise sowohl mit einer Subnetzmaske als auch mit einer IP-Adresse konfiguriert ist, wird die Schnittstelle auch als Netzwerkhost im angeschlossenen Netzwerk betrachtet. Infolgedessen werden sowohl die Subnetzmaske als auch die Netzwerkadresse der Schnittstelle (zusammen mit dem Schnittstellentyp und der Nummer) in die lokal gespeicherte Routingtabelle eingegeben. Der Eintrag erfolgt als angeschlossenes Netzwerk. Ein häufiges Beispiel für ein direkt verbundenes Netzwerk sind Webserver, die sich im selben Netzwerk wie der Computerhost befinden und ein direkt verbundenes Netzwerk in der Routingtabelle darstellen, die auf dem Gateway oder Router gespeichert ist.
Was ist ein Remote-Netzwerk?
Entfernte Netzwerke sind nicht direkt mit dem Gateway oder Router im Netzwerk verbunden. Was eine Routing-Tabelle betrifft, kann ein entferntes Netzwerk nur durch Weiterleiten von Datenpaketen an andere Router erreicht werden. Diese Netzwerke werden der lokalen Routingtabelle durch die Konfiguration statischer Netzwerkrouten oder durch Verwendung eines dynamischen Routingprotokolls hinzugefügt. Dynamische Routen werden vom Router “gelernt”, indem die effizientesten Mittel zur Zustellung von Datenpaketen unter Verwendung eines dynamischen Routing-Protokolls verfolgt werden. Netzwerkadministratoren sind in der Regel die einzigen Personen, die berechtigt sind, statische Routen zu Remotenetzwerkzielen manuell zu konfigurieren.
Was sind einige Probleme mit Routing-Tabellen?
Eine der größten Herausforderungen bei modernen Routing-Tabellen ist der enorme Speicherplatz, der zum Speichern der Informationen erforderlich ist, um eine große Anzahl von vernetzten Computergeräten auf begrenztem Speicherplatz auf dem Router zu verbinden. Die aktuelle Technologie, die auf den meisten Netzwerkroutern für die Adressaggregation verwendet wird, ist die Class Inter-Domain Routing (CIDR) -Technologie. CIDR verwendet ein bitweises Präfix-Matching-Schema. Dieses Schema beruht auf der Tatsache, dass jede Note in einem Netzwerk eine gültige Routing-Tabelle hat, die konsistent ist und Schleifen vermeidet. Leider sind die Tabellen im derzeit verwendeten “Hop / Hop” -Routingmodell nicht konsistent und es entstehen Schleifen. Dies führt dazu, dass sich Datenpakete in einem endlosen Lop befinden und seit Jahren ein großes Problem für das Netzwerk-Routing darstellen.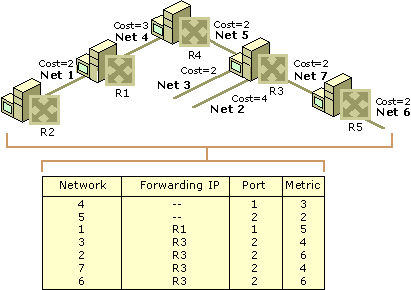
Was sind die Inhalte einer Routing-Tabelle?
Obwohl jede Netzwerk-Routing-Tabelle unterschiedliche Informationen enthalten kann, umfassen die primären Felder jeder Tabelle: die Netzwerk-ID, Kosten oder Metrik und der nächste Hop.
Netzwerk-ID – Dieses Feld in einer Routing-Tabelle enthält das Zieladressen-Subnetz.
Kosten oder Metrik – Dieses Feld speichert die Metrik oder “Kosten” des Netzwerkpfads, an den das ausgehende Datenpaket gesendet wird.
Nächster Hop – Das Gateway oder der nächste Hop ist die Zieladresse des nächsten Netzwerkstandorts, an den Datenpakete auf ihrem Weg zur Ziel-IP-Adresse übertragen werden.
Weitere Informationen, die in einer Netzwerk-Routing-Tabelle zu finden sind, umfassen:
Netzwerkroute Quality of Service – Im Laufe der Zeit sind einige Netzwerkrouter so konzipiert, dass sie eine Dienstqualitätsmetrik speichern, die verschiedenen Netzwerkrouten zugeordnet ist, die in Routingtabellen gespeichert sind. Eine dieser Metriken zeigt einfach an, dass eine bestimmte Route betriebsbereit ist, und setzt ein Flag in der Tabelle, um Speicher zu sparen.
Filterkriterien oder Zugriffslisten – Dieser Eintrag enthält Informationen oder Links zu Informationen, die die neuesten Informationen zu Zugriffslisten oder verschiedenen Filterkriterien enthalten, die einer bestimmten Netzwerkroute zugeordnet sein können.
Netzwerkschnittstelleninformationen – Dies können Daten zu bestimmten Ethernet-Karten oder andere Informationen sein, die zur Optimierung des Routings von Netzwerkdatenpaketen verwendet werden können.
Was ist eine Weiterleitungstabelle?
Eine Netzwerkweiterleitungstabelle oder Weiterleitungsinformationsbasis (FIB) wird normalerweise verwendet, wenn Netzwerke überbrückt oder verschiedene Routingoperationen durchgeführt werden, um die richtige Schnittstelle zu finden, über die eine Eingangsschnittstelle an das Netzwerk ein Datenpaket senden soll.
Anwendungen von Weiterleitungstabellen auf der Datenverbindungsschicht
Weiterleitungstabellen haben auf der Datenverbindungsschicht einige Verwendung gefunden. Beispielsweise haben MAC-Protokolle (Media Access Control) in lokalen Netzwerken eine Adresse, die außerhalb dieses Mediums nicht signifikant ist, und können zur Verwendung in einer Weiterleitungstabelle gespeichert werden, um das Ethernet-Bridging zu unterstützen. Andere Verwendungen umfassen ATM-Schalter (Asynchronous Transfer Mode), Frame-Relais und MPLS (Multiprotocol Label Switching). Für die Verwendung mit ATM gibt es sowohl lokale Adressen der Datenverbindungsschicht als auch andere, die für die Verwendung im Netzwerk von erheblicher Bedeutung sind.
Wie werden Weiterleitungstabellen mit Bridging verwendet?
Wenn eine MAC-Layer-Bridge die Schnittstelle identifiziert, an der eine Quelladresse zum ersten Mal angezeigt wurde, wird die Zuordnung zu Schnittstelle und Adresse vorgenommen. Wenn also ein Frame an der Brücke eine Zieladresse empfängt, die sich in der jeweiligen Weiterleitungstabelle befindet, wird der Frame an die Schnittstelle übertragen, die in der FIB gespeichert wurde. Wenn die Adresse zuvor nicht gesehen wurde, wird sie als “Broadcast” behandelt und sendet die Informationen an alle aktiven Schnittstellen mit Ausnahme derjenigen, die die Informationen erhalten haben.
Wie funktioniert ein Frame Relay?
Obwohl es keine zentral definierte Methode oder keinen zentral definierten Prozess gibt, der bestimmt, wie eine Weiterleitungstabelle oder ein Frame Relay funktioniert, ist das typische Modell in der gesamten Industrie, dass ein Frame Relay Switch eine statisch definierte Weiterleitungstabelle pro Schnittstelle hat. Sobald ein Frame zusammen mit einem DLCI (Data Link Connection Identifier) auf einer bestimmten Schnittstelle empfangen wird, stellt die Tabelle, die der Schnittstelle zugeordnet ist, die ausgehende Schnittstelle bereit. Dies stellt auch den neuen DLCI zum Einfügen in das Frame-Adressfeld in der Tabelle bereit.
Wie funktionieren ATM-Weiterleitungstabellen?
Ein ATM-Switch enthält eine Weiterleitungstabelle auf Verbindungsebene, ähnlich dem Modell, das in einer Frame-Relay-Tabelle verwendet wird. Anstelle von DLCI; die Schnittstelle enthält jedoch Weiterleitungstabellen, die die virtuelle Pfadkennung, die ausgehende Schnittstelle und die virtuelle Schaltungskennung enthalten. Die Tabelle kann entweder über das PNNI-Protokoll (Private Network to Network Interface) verteilt oder statisch definiert werden. Wenn die Tabelle von PNNI erstellt wird, wechseln die ATM-Switches, die sich am Rand des Netzwerks oder der Cloud befinden, und ordnen die End-to-End-IDs im Netzwerk zu, um den nächsten Hop-VCI oder VPI zu identifizieren.
Was ist Multiprotocol Label Switching (MPLS)?
Multiprotocol Label Switching (MPLS) hat eine Reihe von Aspekten, die ATM ähnlich sind. MPSL verwendet LER (Label Edge Router), die sich an den Grenzen der MPSL Cloud Map befinden, die sich zwischen einem lokalen Link-Label und der End-to-End-Kennung (die eine IP-Adresse sein kann) befinden. Bei jedem Hop in MPLS wird eine Weiterleitungstabelle verwendet, um dem LSR mitzuteilen, welche ausgehende Schnittstelle das Paket empfangen soll. Es bestimmt auch, welches Label beim Weiterleiten des Pakets an diese Schnittstelle angewendet werden soll.
Was sind die Anwendungen von Weiterleitungstabellen auf der Netzwerkschicht?
Im Gegensatz zu Netzwerk-Routing-Tabellen ist eine Weiterleitungstabelle oder FIB optimiert, um eine Zieladresse schnell nach Informationen zu suchen. In früheren Versionen von Weiterleitungstabellen wurde eine Teilmenge der Gesamtzahl der Router zwischengespeichert, die am häufigsten zum Weiterleiten von Datenpaketen verwendet wurden. Obwohl diese Methode für das Routing auf Unternehmensebene funktionierte, resultierten bei der Verwendung für den Zugriff auf das gesamte Internet erhebliche Leistungseinbußen daraus, dass der relativ kleine Cache ständig aktualisiert werden musste. Infolgedessen begannen die Weiterleitungstabellenimplementierungen, die Methodik zu verlagern, um sicherzustellen, dass eine FIB eine entsprechende RIB hatte, die mit einem vollständigen Satz von Routen optimiert und aktualisiert wurde, die der Netzwerkrouter gelernt hatte. Weitere Verbesserungen an FIBs sind schnellere Hardware-Lookup-Funktionen und TCAM (Ternary Content Addressable Memory). Aufgrund der hohen Kosten von TCAM; Diese Technologie ist jedoch normalerweise auf Edge-Routern zu finden.
Wie helfen Weiterleitungstabellen bei der Abwehr von Denial-of-Service-Angriffen?
Im Laufe der Zeit wurde die Verwendung einer Weiterleitungstabelle (oder FIB) zum Filtern eingehender Datenpakete zu einer “Best Practice” des Internets, um sich gegen DOS-Angriffe (Denial of Service) in einem Netzwerk zu schützen. In der einfachsten Form verwendet die Eingangsfilterung eine Zugriffsliste, um zu bestimmen, von wem Pakete gelöscht werden sollen, und um den Schaden zu mindern, den ein DoS-Angriff verursachen wird. Wenn das Netzwerk über eine größere Anzahl benachbarter Netzwerke verfügt, kann sich die Verwendung der Zugriffslistenmethode schnell auf die Leistung des Routers auswirken. Bei anderen Implementierungen sucht die Adresse nach der Quelladresse in der FIB. WENN keine Route zur Quelladresse der Informationen vorhanden ist, geht der Algorithmus davon aus, dass das Paket von einer gefälschten oder falschen Quelladresse stammt, und wird als möglicherweise Teil eines DoS-Angriffs verworfen.
Wie werden Weiterleitungstabellen zur Qualitätssicherung verwendet?
FIB-Tabellen können in einer Reihe von Netzwerkverwaltungsschemata verwendet werden, um eine höhere Dienstqualität für bestimmte Datenpakete im Netzwerk sicherzustellen. Diese Unterscheidung kann auf einem Feld int eh Datenpaket basieren, das die Routingpriorität des Pakets zusätzlich dazu angibt, wie lange das Paket im Falle einer Netzwerküberlastung “lebendig” bleiben möchte. Wenn Router diese Art von Dienst unterstützen, müssen sie normalerweise das Datenpaket an die Netzwerkschnittstelle senden, die “am besten” den Dienstanforderungen der Daten entspricht, die normalerweise als DSCP (Differentiated Service Code Points) bezeichnet werden. Obwohl dieser Akt die gesamte Rechenleistung, die zur Verarbeitung des Pakets erforderlich ist, geringfügig erhöht, wird davon ausgegangen, dass der Akt die Netzwerkressourcen nicht wesentlich beeinflusst.
Leave a Reply