Data Validation and Data Verification-from Dictionary to Machine Learning
By Aditya Aggarwal, Advanced Analytics Practice Lead, ja Arnab Bose, Chief Scientific Officer, Abzooba
käytämme usein tietojen todentamista ja validointia keskenään, kun puhumme tietojen laadusta. Nämä kaksi termiä ovat kuitenkin erillisiä. Tässä artikkelissa ymmärrämme eron 4 eri yhteyksissä:
- Dictionary meaning of verification and validation
- Difference between data verification and data validation in general
- Difference between verification and validation from software development perspective
- Difference between data verification and data validation from machine learning perspective
Dictionary meaning of verification and validation
taulukossa 1 selitetään sanakirjasanojen verifiointi ja validointi muutamilla esimerkeillä.

yhteenvetona todennuksessa on kyse totuudesta ja tarkkuudesta, kun taas validoinnissa on kyse näkökulman vahvuuden tai väitteen oikeellisuuden tukemisesta. Oikeellisuustarkistetaan menetelmän oikeellisuus, kun taas tulosten oikeellisuus tarkastetaan.
ero tietojen todentamisen ja tietojen vahvistamisen välillä yleensä
nyt kun ymmärrämme näiden kahden sanan kirjaimellisen merkityksen, tutkitaan eroa “tietojen todentamisen” ja “tietojen vahvistamisen”välillä.
- tietojen tarkistaminen: tietojen paikkansapitävyyden varmistaminen.
- tietojen validointi: tietojen oikeellisuuden varmistaminen.
esitelläänpä esimerkkejä taulukossa 2.

ero todentamisen ja validoinnin välillä ohjelmistokehityksen näkökulmasta
ohjelmistokehityksen näkökulmasta,
- varmistus tehdään sen varmistamiseksi, että ohjelmisto on laadukas, hyvin suunniteltu, kestävä ja virheetön joutumatta sen käytettävyyteen.
- validoinnilla varmistetaan ohjelmistojen käytettävyys ja kyky täyttää asiakkaiden tarpeet.
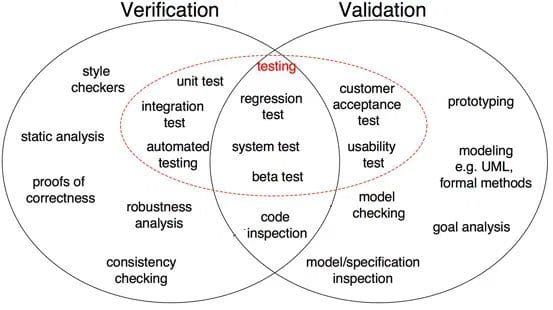
Kuva 1: Erot ohjelmistokehityksen todentamisen ja validoinnin välillä (lähde)
kuten kuvassa 1 osoitetaan, oikeellisuuden todistaminen, kestävyysanalyysi, yksikkötestit, integrointitesti ja muut ovat kaikki todentamisvaiheita, joissa tehtävät suuntautuvat yksityiskohtien todentamiseen. Ohjelmiston ulostulo verifioidaan haluttua tulostetta vastaan. Toisaalta mallitarkastus, mustan laatikon testaus, käytettävyystestaus ovat kaikki validointivaiheita, joissa tehtävät suuntautuvat ymmärtämään, täyttääkö ohjelmisto vaatimukset ja odotukset.
ero tietojen todentamisen ja tietojen vahvistamisen välillä koneoppimisen näkökulmasta
tietojen todentamisen rooli koneoppimisen putkistossa on portinvartijan rooli. Se takaa tarkat ja ajantasaiset tiedot ajan mittaan. Tietojen verifiointi tehdään ensisijaisesti uudessa tiedonhankintavaiheessa eli ML-putken vaiheessa 8, kuten kuvassa esitetään. 2. Esimerkkejä tästä vaiheesta ovat tunnistaa päällekkäisiä tietueita ja suorittaa deduplication, ja puhdistaa epäsuhta asiakastietojen alalla, kuten osoite tai puhelinnumero.
toisaalta tietojen validoinnilla (ML-putken vaiheessa 3) varmistetaan, että vaiheen 8 oppimistietoihin lisätyt inkrementaaliset tiedot ovat hyvälaatuisia ja vastaavat (tilastollisten ominaisuuksien näkökulmasta) olemassa olevia koulutustietoja. Tämä tarkoittaa esimerkiksi tietojen poikkeavuuksien löytämistä tai olemassa olevien koulutustietojen ja koulutustietoihin lisättävien uusien tietojen välisten erojen havaitsemista. Muussa tapauksessa mahdolliset lähtötietojen laatuongelmat/tilastolliset erot lisääntyvissä tiedoissa voivat jäädä huomaamatta ja koulutusvirheet voivat ajan mittaan kertyä ja heikentää mallin tarkkuutta. Näin ollen tietojen validointi havaitsee merkittäviä muutoksia (jos sellaisia on) inkrementaalisissa koulutustiedoissa varhaisessa vaiheessa, mikä auttaa perussyyn analysoinnissa.
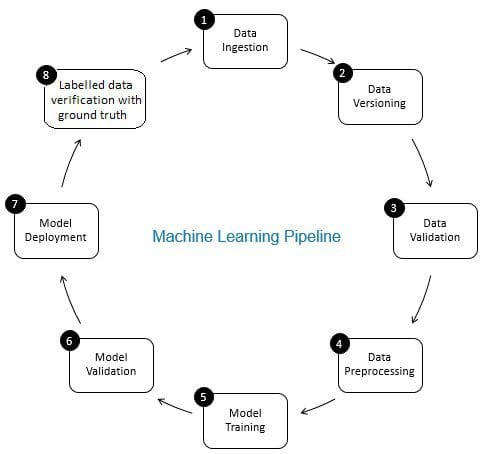
kuva 2: Koneoppimisputken komponentit
Aditya Aggarwal toimii Data Science-Practice Lead-yhtiössä Abzooba Inc. Yli 12 vuoden kokemuksella liiketoimintatavoitteiden ajamisesta datalähtöisten ratkaisujen avulla Aditya on erikoistunut ennakoivaan analytiikkaan, koneoppimiseen, liiketoimintatiedon ymmärtämiseen & liiketoimintastrategiaan eri toimialoilla.
Arnab Bose on data-analytiikkayritys abzooban tieteellinen johtaja ja Chicagon yliopiston dosentti, jossa hän opettaa koneoppimista ja ennakoivaa analytiikkaa, koneoppimisen operaatioita, aikasarja-analyysiä ja ennustamista sekä Terveysanalytiikkaa Master of Science in Analytics-ohjelmassa. Hän on 20-vuotinen ennustavan analytiikan alan veteraani, joka käyttää jäsenneltyä ja jäsenneltyä dataa ennustaakseen ja vaikuttaakseen käyttäytymisen tuloksiin terveydenhuollossa, vähittäiskaupassa, rahoituksessa ja kuljetuksissa. Hänen nykyisiä painopistealueitaan ovat terveysriskien ositus ja kroonisten sairauksien hallinta koneoppimisen avulla sekä koneoppimismallien tuotannon käyttöönotto ja seuranta.
liittyvät:
- MLOps – ” miksi sitä tarvitaan?”ja” mitä se on”?
- koneoppimismallini ei opi. Mitä minun pitäisi tehdä?
- Data Observability, Part II: How to Build Your Own Data Quality Monitors Using SQL
Leave a Reply