Sanastoanalyysi Kääntäjässä
Sanastoanalyysi Kääntäjässä on ensimmäinen vaihe lähdeohjelman analysoinnissa. Leksikaalinen analyysi lukee lähdeohjelman tulovirran merkki kerrallaan ja tuottaa polettisarjan. Nämä kuponkia tarjotaan syötteenä jäsennin jäsentämistä. Tässä yhteydessä keskustelemme lyhyesti sanastoanalyysista sekä sanastovirheistä ja niiden takaisinperinnästä.
sisältö: Lexical Analysis in Compiler
- Terminologies in Lexical Analysis
- What is Lexical Analysis?
- esimerkkejä Leksikaalisista analyyseistä
- leksikaalisen analysaattorin rooli
- Lexical Error
- Error Recovery
- Key Takeaways
Terminologies in Lexical Analysis
ennen kuin ryhdymme käsittelemään leksikaalisen analyysin terminologioita
puhukaamme joistakin terminologioista, jotka olemme törmänneet keskustellessamme leksikaalisesta analyysistä.
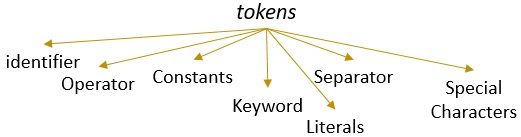
- Lekseemi
Lekseemi voidaan määritellä jonoksi merkkejä, jotka muodostavat kuvion ja jotka voidaan tunnistaa tokeniksi. - kuvio
lekseemin kuvion tunnistamisen jälkeen voidaan kuvata, millainen token voidaan muodostaa. Esimerkiksi joidenkin lekseemien kuvio muodostaa avainsanan, joidenkin lekseemien kuvio muodostaa tunnisteen. - Token
lekseemi, jolla on voimassa oleva kuvio, muodostaa Tokenin. Leksikaalisessa analyysissä kelvollinen token voi olla tunnisteet, avainsanat, erottimet, erikoismerkit, vakiot ja operaattorit.
mikä on leksikaalinen analyysi?
aiemmin olemme poistaneet käytöstä leksikaalisesta analysaattorista sisällönkääntäjässämme tietokoneella. Olemme oppineet, että kääntäjä suorittaa lähdeohjelman analyysin eri vaiheiden kautta muuttaakseen sen kohdeohjelmaksi. Leksikaalinen analyysi on ensimmäinen vaihe, jonka lähdekoodiohjelma joutuu käymään läpi.
leksikaalinen analyysi on tokenisointiprosessi ts. se lukee lähdeohjelman syöttömerkkijonon merkki kerrallaan ja heti kun se tunnistaa lekseemin lopun, se tunnistaa sen kuvion ja muuntaa sen tokeniksi.
leksikaalinen analysaattori koostuu kahdesta peräkkäisestä prosessista, joihin kuuluvat skannaus ja leksikaalinen analyysi.
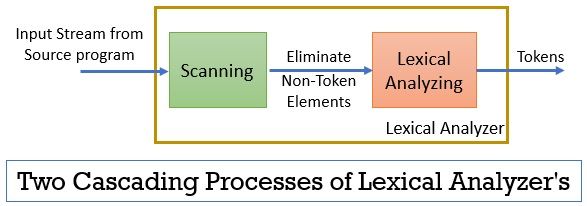
- skannaus: skannausvaihe-poistaa vain ei-token-elementit lähdeohjelmasta. Kuten kommenttien poistaminen, peräkkäisten valkoisten välilyöntien tiivistäminen jne.
- Leksikaalinen Analyysi: Leksikaalinen analysointivaihe suorittaa tokenisoinnin skannerin antamassa ulostulossa ja tuottaa siten tokeneja.
leksikaalisen analyysin suorittamiseen käytettävää ohjelmaa kutsutaan lekseriksi tai leksikaaliseksi analysaattoriksi. Otetaan nyt esimerkki leksikaalinen analyysi suoritetaan lausuman:
Esimerkki 1 Lexical Analysis:
Leksical analysis in compiler design, identify tokens.
nyt, kun luemme tämän lausuman, voimme helposti tunnistaa, että yllä olevassa lauseessa on yhdeksän polettia.
- Identifiers -> lexical
- Identifiers -> analysis
- Identifiers -> in
- Identifiers -> kääntäjä
- Identifiers -> design
- erotin -> ,
- Identifiers – > identify
- Identifiers – > tokens
- Separator – > .
joten kuten yhteensä, yllä olevassa merkkivirrassa on 9 polettia.
leksikaalisen analyysin Esimerkki 2:
printf (“I: n arvo on %d”, i);
yritetään nyt löytää tokeneita tästä tulovirrasta.
- Avainsana – > printf
- erikoismerkki -> (
- kirjaimellinen – > “I: n arvo on %d”
- erotin -> ,
- tunniste – > i
- erikoismerkki -> )
- erotin -> ;
Huomautus:
- koko merkkijono sisällä kaksinkertainen lainausmerkki eli “” pidetään yhtenä token.
- tulovirran merkit erottava tyhjä valkoinen väli erottaa vain poletit ja siten se eliminoituu poletteja laskettaessa.
leksikaalisen analysaattorin rooli
koska lähdeohjelman analysoinnin ensimmäinen vaihe leksikaalisella analysaattorilla on tärkeä rooli lähdeohjelman muuttumisessa kohdeohjelmaksi.
tämä koko skenaario voidaan toteuttaa alla olevan kuvan avulla:
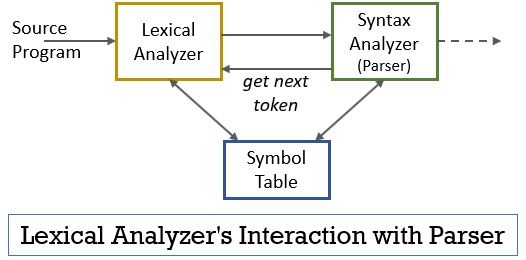
- lexical analyzer-vaiheessa on toteutettu skanneri tai lexer-ohjelma, joka tuottaa poletteja vain silloin, kun jäsennin niin määrää.
- jäsennin luo getnexttoken-komennon ja lähettää sen lexical analyzerille vastauksena tähän lexical analyzer alkaa lukea tulovirtaa merkki kerrallaan, kunnes se tunnistaa tokeniksi tunnistettavan lexemen.
- heti kun token on tuotettu, lexical analyzer lähettää sen syntaksianalysaattorille jäsennettäväksi.
- yhdessä syntaksianalysaattorin kanssa leksikaalinen analysaattori kommunikoi myös symbolitaulukon kanssa. Kun lexical analysaattori tunnistaa lexeme kuin tunniste se syöttää että lexeme osaksi symboli taulukkoon.
- joskus symbolitaulukon tunnistetieto auttaa leksikaalista analysaattoria määrittämään jäsentäjälle lähetettävän Tokenin.
- tulovirran polettien tunnistamisen lisäksi leksikaalinen analysaattori poistaa myös tyhjän tilan / valkoisen tilan ja ohjelman Kommentit. Tällaisia muita asioita ovat merkit separates tokens, välilehdet, tyhjät välilyönnit, uudet rivit.
- leksikaalinen analysaattori auttaa kääntäjän tuottamien virheilmoitusten suhteuttamisessa. Esimerkiksi lexical analyzer pitää kirjaa jokaisesta uudesta rivimerkistä, johon se törmää lähdeohjelmaa skannatessaan, joten se liittää virheilmoituksen helposti lähdeohjelman rivinumeroon.
- jos lähdeohjelmassa käytetään makroja, lexical analyzer laajentaa lähdeohjelman makroja.
leksikaalinen virhe
leksikaalinen analysaattori itsessään ei ole tehokas määrittämään lähdeohjelmasta tulevaa virhettä. Tarkastellaan esimerkiksi väitettä:
prtf(” I: n arvo on %d”, i);
nyt edellä mainitussa lauseessa merkkijonon prtf kohdatessa leksikaalinen analysaattori ei pysty arvailemaan, onko prtf hakusanan “printf” virheellinen kirjoitusasu vai onko se ilmoittamaton funktion tunniste.
, mutta ennalta määritetyn säännön mukaan prtf on kelvollinen lekseemi, jonka kuvio päättelee sen olevan tunnisteosoite. Nyt, lexical analysaattori lähettää prtf token seuraavaan vaiheeseen eli jäsennin, joka käsittelee virhe, joka tapahtui, koska osaksi kirjeiden.
Virheenpalautus
no, joskus lexical Analyzerin on jopa mahdotonta tunnistaa lekseemiä tokeniksi, koska lekseemin kuvio ei vastaa mitään ennalta määriteltyjä kaavakkeita tokeneille. Tässä tapauksessa, meidän on sovellettava joitakin virheiden palautusstrategioita.
- paniikkitilan palautuksessa perättäinen merkki lekseemistä poistetaan, kunnes leksikaalianalysaattori tunnistaa kelvollisen tunnuksen.
- poista ensimmäinen merkki jäljellä olevasta syötöstä.
- merkitään mahdollinen puuttuva merkki ja lisätään se jäljellä olevaan syötteeseen asianmukaisesti.
- korvaa merkki jäljellä olevassa syötteessä saadaksesi kelvollisen tunnuksen.
- vaihda kahden vierekkäisen merkin sijainti jäljellä olevassa syötteessä.
suorittaessasi yllä olevia virheenpalautustoimia tarkista, vastaako jäljellä olevan syötön etuliite mitään polettikuviota. Yleensä leksikaalinen virhe johtuu yhdestä merkistä. Niin, voit korjata leksikaalinen virhe yhdellä muutoksella. Ja mahdollisuuksien mukaan pienemmän määrän muunnoksia on muunnettava lähdeohjelma jaksoksi kelvollisia tokeneita, jotka se voi luovuttaa jäsentäjälle.
Key Takeaways
- leksikaalinen analyysi on kääntäjän lähdeohjelman analysoinnin ensimmäinen vaihe.
- leksikaalianalysaattori toteutetaan kahdella peräkkäisellä prosessiskannerilla ja leksikaalianalyysillä.
- skanneri poistaa ei-token-elementit tulovirrasta.
- leksikaalinen analyysi suorittaa tokenisaation.
- näin leksikaalinen analysaattori luo jonon tokeneita ja välittää ne eteenpäin jäsentimeen.
- jäsennin, jolla on token lexical analyzeristä, tekee puhelun getNextToken, joka vaatii lexical analyzeria lukemaan merkkien tulovirran, kunnes se tunnistaa seuraavan Tokenin.
- jos lexical analyzer tunnistaa lekseemin kuvion tunnisteeksi, leksical analyzer syöttää kyseisen lekseemin symbolitaulukkoon tulevaa käyttöä varten.
- Lexical analyzer ei ole tehokas tunnistamaan lähdeohjelman virheitä yksin.
- Jos esiintyy lekseemi, jonka kuvio ei vastaa mitään ennalta määritetyistä tokeneista, sinun on suoritettava virheenpalautustoimet korjataksesi virheen.
niin, tämä on kyse leksikaalinen analyysi, joka muuttaa virta merkkejä tokens ja siirtää sen jäsennin. Olemme oppineet leksikaalisen analyysin työskentelystä esimerkin avulla. Olemme päättäneet keskustelun sanakirjavirheeseen ja sen perintästrategiaan.
Leave a Reply