Analyse lexicale dans le compilateur
L’analyse lexicale dans le compilateur est la première étape de l’analyse du programme source. L’analyse lexicale lit le flux d’entrée du programme source caractère par caractère et produit la séquence de jetons. Ces jetons sont fournis comme entrée à l’analyseur pour l’analyse. Dans ce contexte, nous discuterons brièvement du processus d’analyse lexicale ainsi que des erreurs lexicales et de leur récupération.
Contenu: Analyse lexicale dans le Compilateur
- Terminologies dans l’Analyse lexicale
- Qu’est-ce que l’Analyse lexicale?
- Exemples d’Analyse lexicale
- Rôle de l’Analyseur Lexical
- Erreur lexicale
- Récupération d’erreur
- Points à retenir
Terminologies dans l’Analyse lexicale
Avant d’entrer dans l’analyse lexicale, comment elle est effectuée, parlons de certaines terminologies que nous rencontrerons en discutant de l’analyse lexicale.
- Lexème
Le lexème peut être défini comme une séquence de caractères qui forme un motif et peut être reconnu comme un jeton. - Motif
Après avoir identifié le motif du lexème, on peut décrire quel type de jeton peut être formé. Comme le modèle de certains lexèmes forme un mot-clé, le modèle de certains lexèmes forme un identifiant. - Jeton
Un lexème avec un motif valide forme un jeton. En analyse lexicale, un jeton valide peut être des identifiants, des mots-clés, des séparateurs, des caractères spéciaux, des constantes et des opérateurs.
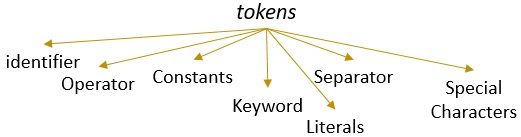
Qu’est-ce que l’Analyse lexicale ?
Plus tôt, nous avons abandonné l’analyseur lexical dans notre compilateur de contenu sur ordinateur. Nous avons appris que le compilateur effectue l’analyse du programme source à travers différentes phases pour le transformer en programme cible. L’analyse lexicale est la première phase que le programme source doit traverser.
L’analyse lexicale est le processus de tokenisation c’est-à-dire il lit la chaîne d’entrée d’un programme source caractère par caractère et dès qu’il identifie une fin du lexème, il identifie son motif et le convertit en jeton.
L’analyseur lexical se compose de deux processus consécutifs qui comprennent le balayage et l’analyse lexicale.
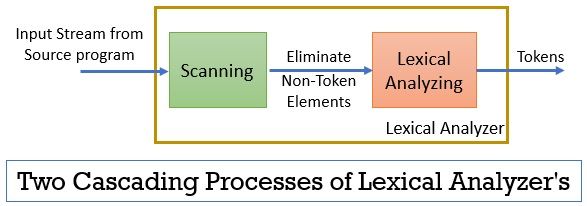
- Numérisation : La phase de numérisation élimine uniquement les éléments non symboliques du programme source. Tels que l’élimination des commentaires, le compactage des espaces blancs consécutifs, etc.
- Analyse lexicale: La phase d’analyse lexicale effectue la tokenisation sur la sortie fournie par le scanner et produit ainsi des tokens.
Le programme utilisé pour effectuer une analyse lexicale est appelé lexer ou analyseur lexical. Prenons maintenant un exemple d’analyse lexicale effectuée sur un énoncé:
Exemple 1 d’analyse lexicale :
Analyse lexicale dans la conception du compilateur, identifiez les jetons.
Maintenant, lorsque nous lirons cette déclaration, nous pouvons facilement identifier qu’il y a neuf jetons dans la déclaration ci-dessus.
- Identifiants – > lexical
- Identifiants – > analyse
- Identifiants – > dans
- Identifiants – > compilateur
- Identifiants – > conception
- Séparateur -> ,
- Identificateurs – > identifiez
- Identificateurs – > jetons
- Séparateur – >.
Donc, au total, il y a 9 jetons dans le flux de caractères ci-dessus.
Exemple 2 d’Analyse lexicale:
printf(“la valeur de i est %d”, i);
Essayons maintenant de trouver des jetons dans ce flux d’entrée.
- Mot-clé – > printf
- Caractère spécial -> (
- Littéral – > “La valeur de i est %d”
- Séparateur -> ,
- Identifiant – > i
- Caractère spécial -> )
- Séparateur -> ;
Note:
- La chaîne entière à l’intérieur des doubles virgules inversées, c’est-à-dire “”, est considérée comme un seul jeton.
- L’espace blanc vide séparant les caractères dans le flux d’entrée ne sépare que les jetons et est donc éliminé lors du comptage des jetons.
Rôle de l’analyseur lexical
Étant la première phase de l’analyse du programme source, l’analyseur lexical joue un rôle important dans la transformation du programme source en programme cible.
Tout ce scénario peut être réalisé à l’aide de la figure ci-dessous:
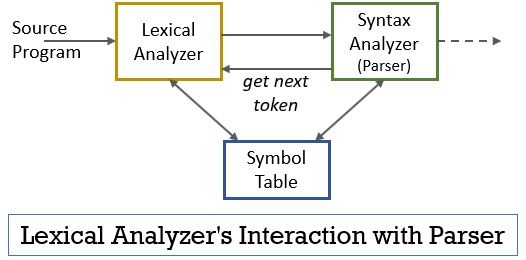
- La phase de l’analyseur lexical comprend le programme scanner ou lexer qui produit des jetons uniquement lorsqu’ils sont commandés par l’analyseur pour le faire.
- L’analyseur génère la commande getNextToken et l’envoie à l’analyseur lexical en réponse à cela, l’analyseur lexical commence à lire le flux d’entrée caractère par caractère jusqu’à ce qu’il identifie un lexème pouvant être reconnu comme un jeton.
- Dès qu’un jeton est produit, l’analyseur lexical l’envoie à l’analyseur de syntaxe pour analyse.
- En plus de l’analyseur de syntaxe, l’analyseur lexical communique également avec la table de symboles. Lorsqu’un analyseur lexical identifie un lexème comme identifiant, il entre ce lexème dans la table des symboles.
- Parfois, les informations d’identifiant dans la table de symboles aident l’analyseur lexical à déterminer le jeton qui doit être envoyé à l’analyseur.
- En plus d’identifier les jetons dans le flux d’entrée, l’analyseur lexical élimine également l’espace vide / espace blanc et les commentaires du programme. Ces autres choses incluent les caractères qui séparent les jetons, les onglets, les espaces vides, les nouvelles lignes.
- L’analyseur lexical aide à relier les messages d’erreur produits par le compilateur. Juste, par exemple, l’analyseur lexical conserve l’enregistrement de chaque nouveau caractère de ligne rencontré lors de l’analyse du programme source afin de relier facilement le message d’erreur au numéro de ligne du programme source.
- Si le programme source utilise des macros, l’analyseur lexical étend les macros du programme source.
Erreur lexicale
L’analyseur lexical lui-même n’est pas efficace pour déterminer l’erreur du programme source. Par exemple, considérons une instruction :
prtf (“la valeur de i est %d”, i);
Maintenant, dans l’instruction ci-dessus, lorsque la chaîne prtf est rencontrée, l’analyseur lexical est incapable de deviner si le prtf est une orthographe incorrecte du mot clé ‘printf’ ou s’il s’agit d’un identifiant de fonction non déclaré.
Mais selon la règle prédéfinie, prtf est un lexème valide dont le motif conclut qu’il s’agit d’un jeton identifiant. Maintenant, l’analyseur lexical enverra le jeton prtf à la phase suivante, c’est-à-dire à l’analyseur qui traitera l’erreur qui s’est produite en raison de la transposition des lettres.
Récupération d’erreur
Eh bien, il est parfois même impossible pour un analyseur lexical d’identifier un lexème en tant que jeton, car le motif du lexème ne correspond à aucun des motifs prédéfinis pour les jetons. Dans ce cas, nous devons appliquer des stratégies de récupération des erreurs.
- En mode panic recovery, le caractère successif du lexème est supprimé jusqu’à ce que l’analyseur lexical identifie un jeton valide.
- Élimine le premier caractère de l’entrée restante.
- Identifiez le caractère manquant possible et insérez-le dans l’entrée restante de manière appropriée.
- Remplacez un caractère dans l’entrée restante pour obtenir un jeton valide.
- Échangez la position de deux caractères adjacents dans l’entrée restante.
Lors de l’exécution des actions de récupération d’erreur ci-dessus, vérifiez si le préfixe de l’entrée restante correspond à un modèle de jetons. Généralement, une erreur lexicale se produit en raison d’un seul caractère. Ainsi, vous pouvez corriger l’erreur lexicale avec une seule transformation. Et autant que possible, un plus petit nombre de transformations doit convertir le programme source en une séquence de jetons valides qu’il peut remettre à l’analyseur.
Points clés
- L’analyse lexicale est la première phase de l’analyse du programme source dans le compilateur.
- L’analyseur lexical est mis en œuvre par deux processus consécutifs scanner et analyse lexicale.
- Le scanner élimine les éléments non symboliques du flux d’entrée.
- L’analyse lexicale effectue la segmentation en jetons.
- Ainsi, l’analyseur lexical génère une séquence de jetons et les transfère dans l’analyseur.
- L’analyseur en possession d’un jeton de l’analyseur lexical effectue un appel getNextToken qui insiste pour que l’analyseur lexical lise le flux de caractères d’entrée jusqu’à ce qu’il identifie le jeton suivant.
- Si l’analyseur lexical identifie le motif d’un lexème comme identifiant, l’analyseur lexical entre ce lexème dans la table des symboles pour une utilisation future.
- Lexical analyzer n’est pas efficace pour identifier une erreur dans le programme source seul.
- S’il se produit un lexème dont le motif ne correspond à aucun des motifs prédéfinis de jetons, vous devez effectuer des actions de récupération d’erreur pour corriger l’erreur.
Il s’agit donc de l’analyse lexicale qui transforme le flux de caractères en jetons et le transmet à l’analyseur. Nous avons appris le fonctionnement de l’analyse lexicale à l’aide d’un exemple. Nous avons conclu la discussion avec l’erreur lexicale et son programme de récupération.
Leave a Reply