Comment J’écris Mes Blogs d’Analyse de Données par Kathleen E.’23
Mon cher ami et collègue blogueur Kidist A.’22 M’a demandé d’écrire un article pour décrire comment je vais écrire mes blogs d’analyse de données. Alors, voilà ! J’ai décrit mes étapes générales et lié à mes anciens messages pour donner des exemples de ce dont je parle.
Identifier une question

Je commence par me poser les questions suivantes:
- Quelle histoire veux-je raconter ?
- Comment l’analyse des données aide-t-elle à raconter cette histoire?
Si je suis coincé, j’essaie de penser à ma vie et au monde qui m’entoure. Y a-t-il des modèles que j’aimerais étudier ou des phénomènes que j’aimerais quantifier?
Voici quelques choses que je me suis posées dans le passé:
- À quoi ressemblent mes schémas de travail? Confusion, par les chiffres
- Qu’est-ce que ça fait de grimper 22 fois dans un immeuble de 20 étages? Green Building Challenge
- Que pensent les étudiants du MIT du nouveau système de blanchisserie de nos dortoirs? Washlava! Une analyse des sentiments
Ensuite, je me demande quel type de données serait utile pour répondre à votre question. Cela nous amène à l’étape suivante:
Recueillir des données
La collecte de données peut être simple ou assez fastidieuse. Les données peuvent exister déjà, soigneusement compilées dans une base de données. Si la base de données est publique, j’en ai fini avec cette étape! Si c’est privé, j’envoie généralement une demande au propriétaire pour l’utiliser. Si les données se trouvent dans une application comme Facebook, je cherche des moyens de demander un téléchargement de données. Les données pourraient également exister quelque part un peu plus gênant (dispersées sur le Web, par exemple) et je devrais aller les collecter.
Si les données n’existent pas encore, je peux commencer à les créer. Si la question à laquelle j’essaie de répondre est plus personnelle, je peux commencer à suivre quelque chose dans ma vie, soit automatiquement (comme avec une montre à comptage de pas), soit manuellement (comme enregistrer ce que Netflix montre que je regarde chaque soir). Ou, si les données concernent d’autres personnes, je pourrais mener une expérience ou envoyer une enquête.
Voici un organigramme que j’ai créé qui résume la façon dont je pourrais obtenir des données:
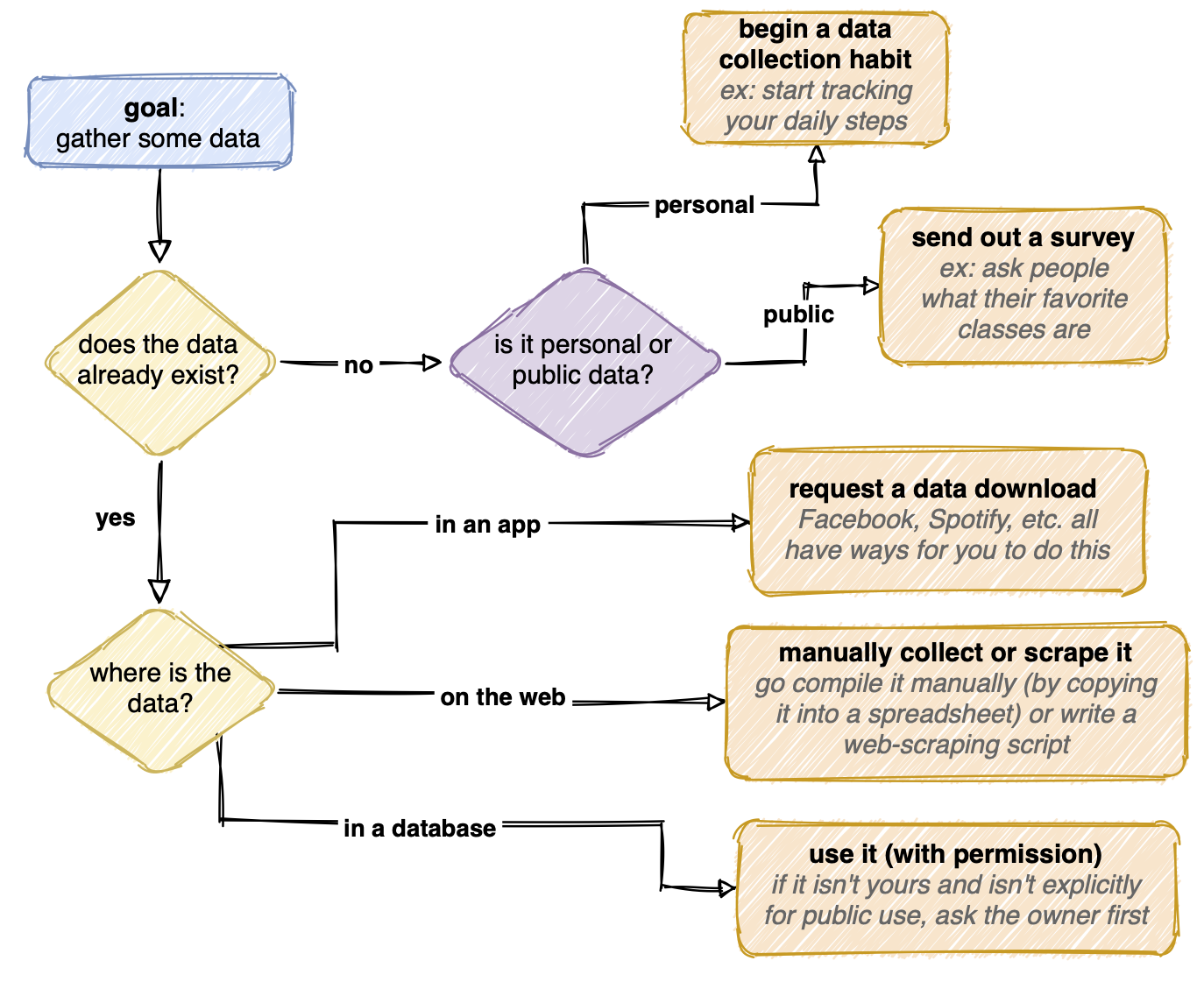
Nettoyez les données

Les données sont rarement prêtes à être analysées. Pour le préparer, je dois le “nettoyer”.
Qu’est-ce que cela signifie que les données ne soient pas prêtes à être analysées? Peut-être y a-t-il beaucoup de données qui ne se rapportent pas à ma question. Peut-être que les données sont représentées de manière vraiment désorganisée ou incohérente. Le nettoyage pourrait signifier extraire le sous-ensemble pertinent des données, l’organiser et modifier la façon dont elles sont représentées pour en faire une analyse plus simple.
Par exemple, dans dormspam-the-game (Partie 1), les données consistaient en une liste d’emplacements où chaque joueur (dans un jeu virtuel de cache-cache) choisissait de se cacher. Cependant, certaines entrées de la base de données étaient mal orthographiées, provoquant des erreurs dans mon code lorsqu’il tentait d’itérer sur une liste d’emplacements. J’ai dû aller remplacer ces entrées par des versions correctement orthographiées de l’emplacement.
Faites une analyse des données!
J’utilise généralement Python pour écrire des scripts pour analyser et visualiser mes données. J’ai mis une partie de mon code publiquement sur Github, pour que vous puissiez y jeter un coup d’œil. Cependant, Python n’est pas la seule option. Vous pouvez également utiliser une variété d’autres langages de script dotés d’excellents outils d’analyse et de visualisation. Vous pouvez également aller sans code et utiliser des fonctions de feuille de calcul. Cela dit, voici comment je travaille avec Python:
- J’aime utiliser des notebooks Jupyter (ou des notebooks Google Colab). Je les aime mieux qu’un fichier texte brut car ils permettent aux notes / documentations de démarquage et aux visualisations d’exister à côté de votre code. Si je planifie mes analyses, que j’apprends à utiliser un nouvel outil ou que je fais référence à un résultat passé, c’est bien que je puisse simplement faire défiler pour regarder les notes / sorties / tracés dans mon cahier au lieu d’une référence externe.
- Je compte beaucoup sur les paquets. J’importe presque toujours Pandas, Numpy et Matplotlib pour gérer et organiser mes données, effectuer des opérations statistiques et mathématiques de base et effectuer des visualisations de base, respectivement. Projet par projet, j’importe également des packages supplémentaires pour accéder à des modèles et des visualisations spéciaux qui pourraient être pertinents.
- Je commence par charger mes données. Je peux le charger localement à partir d’un fichier sur mon ordinateur. Ou, le plus souvent, ce que je fais, c’est le télécharger sur Google Sheets, utiliser la fonction “Publier sur le Web” pour générer un lien vers un fichier CSV, puis utiliser ce lien pour charger mes données. Je préfère utiliser Google sheets plutôt qu’un fichier local car il a un historique de version et des fonctions de collaboration plus agréables.
- Ensuite, je m’engage dans un processus itératif où je fais l’hypothèse d’une tendance dans les données, je fais une analyse pour étudier l’hypothèse, puis j’utilise les résultats pour générer plus d’hypothèses. Avec des données vraiment intéressantes ou étranges, ce processus peut durer un certain temps.
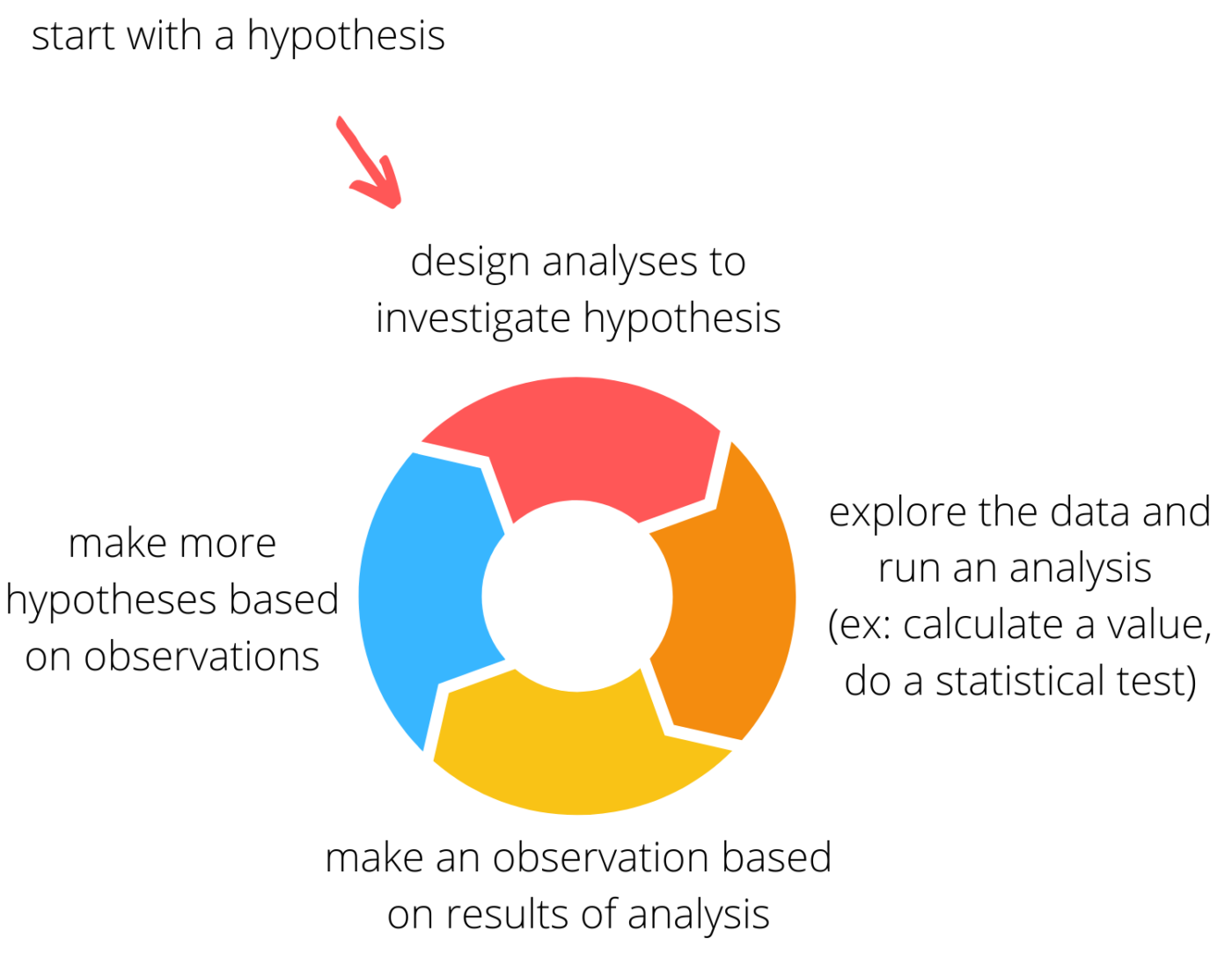
Créez des tracés
Pendant que j’analyse les données, une façon utile de repérer les motifs sympas est de faire des visualisations. Je peux le faire avec une variété de graphiques. Mon premier complot est souvent assez laid. Je peux utiliser diverses fonctions dans ma bibliothèque de traçage pour mieux mettre en évidence les données, à la fois scientifiquement et esthétiquement. Par exemple, je peux ajuster les couleurs et le dimensionnement des points de données, des lignes et des barres pour mieux démontrer les tendances. Je peux changer la façon dont les axes x et y sont représentés pour rendre le tracé plus propre.
En plus de créer des parcelles statiques, j’aime parfois animer des parcelles (voir Défi de construction verte et dormspam-the-game (Partie 1)). La création de tracés est un processus créatif, en particulier lors de la création de tracés animés où des caractéristiques telles que la couleur et la taille peuvent servir un objectif différent de celui d’un tracé statique.
Faire des visualisations est ma partie préférée du processus. J’aime laisser mes côtés artistiques et techniques se rencontrer.
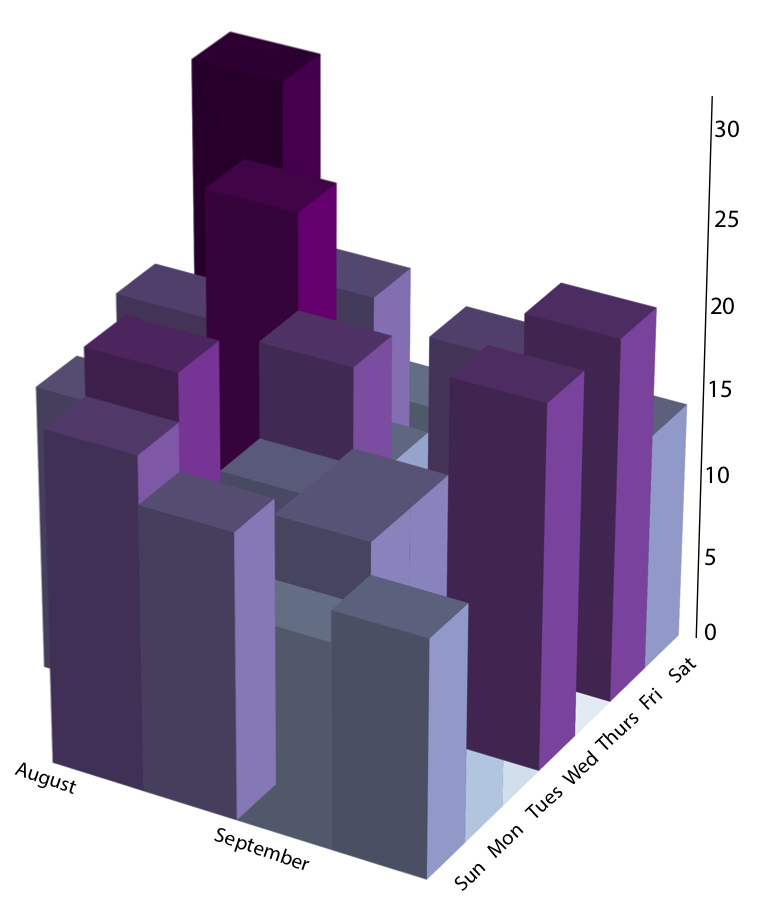
un tracé de mon tout premier article de blog montrant le nombre de mesures que j’ai prises, en milliers, au cours de mes premières semaines au MIT
Raconter une histoire
Il est important de réfléchir à la manière dont mes analyses de données et mes visualisations peuvent contribuer à raconter une histoire sur la tendance que j’étudie ou le phénomène que je quantifie. J’essaie de créer des intrigues de manière à permettre à chaque intrigue de montrer une nouvelle partie de l’histoire. J’essaie de leur ordonner mes intrigues mes posts de manière à ce que chacun de mes mots et mes intrigues ensemble racontent progressivement une histoire sur ce qui se passe. Par exemple, lorsque j’ai visualisé les données d’un jeu, je pourrais d’abord décrire les règles du jeu, puis décrire qui a gagné, puis comprendre comment les différentes stratégies des joueurs ont affecté le résultat.
Donc, c’est à peu près comme ça que je vais écrire mes blogs d’analyse de données. Je l’ai séparé en 6 étapes, mais penser “à l’envers” plutôt que strictement étape par étape peut aider à rendre votre travail dans les étapes précédentes plus significatif. Si vous réfléchissez à la façon de rendre l’histoire convaincante, vous pouvez faire de meilleures visualisations. Si vous savez quelles visualisations vous souhaitez effectuer, vous pouvez mieux diriger votre collecte de données.
Leave a Reply