Tables de Routage
Une table de routage est un regroupement d’informations stockées sur un ordinateur ou un routeur réseau en réseau qui comprend une liste d’itinéraires vers diverses destinations réseau. Les données sont normalement stockées dans une table de base de données et, dans des configurations plus avancées, elles incluent des métriques de performance associées aux routes stockées dans la table. Les informations supplémentaires stockées dans le tableau comprendront la topologie du réseau la plus proche du routeur. Bien qu’une table de routage soit régulièrement mise à jour par des protocoles de routage réseau, des entrées statiques peuvent être effectuées par une action manuelle de la part d’un administrateur réseau.
Comment fonctionne une Table de routage ?
Les tables de routage fonctionnent de la même manière que le bureau de poste livre le courrier. Lorsqu’un nœud de réseau sur Internet ou un réseau local doit envoyer des informations à un autre nœud, il faut d’abord avoir une idée générale de l’endroit où envoyer les informations. Si le nœud ou l’adresse de destination n’est pas connecté directement au nœud de réseau, les informations doivent être envoyées via d’autres nœuds de réseau. Afin d’économiser des ressources, la plupart des nœuds de réseau local ne maintiendront pas de table de routage complexe. Au lieu de cela, ils enverront des paquets d’informations IP à une passerelle de réseau local. La passerelle maintient la table de routage principale pour le réseau et enverra le paquet de données à l’emplacement souhaité. Afin de maintenir un enregistrement de la façon d’acheminer les informations, la passerelle utilisera une table de routage qui garde la trace de la destination appropriée pour les paquets de données sortants.
Toutes les tables de routage conservent des listes de tables de routage pour les destinations accessibles à partir de l’emplacement du routeur. Cela inclut l’adresse du périphérique en réseau suivant sur le chemin réseau vers l’adresse de destination, également appelée “saut suivant”.”En maintenant des informations précises et cohérentes concernant les nœuds de réseau, l’envoi d’un paquet de données le long de l’itinéraire le plus court vers l’adresse de destination sur Internet suffit normalement pour fournir du trafic réseau et constitue l’une des caractéristiques de base du réseau OSI et des couches de réseau IP de la théorie des réseaux.
Quelle est la fonction principale d’un routeur réseau ?
La fonction principale d’un routeur réseau est de transférer des paquets de données vers le réseau de destination inclus dans l’adresse IP de destination du paquet de données sortant. Afin de déterminer la destination appropriée du paquet de données, le routeur effectue une recherche des adresses de destination stockées dans la table de routage La table de routage est stockée en RAM sur le routeur passerelle du réseau et comprend des informations sur les réseaux de destination et les associations de “prochain saut” pour ces adresses. Ces informations aident le routeur à déterminer et à identifier le meilleur emplacement sortant pour le paquet de données à envoyer afin de trouver la destination réseau ultime. Cet emplacement peut également être l’interface de passerelle de tout réseau directement connecté.
Qu’est-ce qu’un Réseau directement connecté ?
Les réseaux directement connectés sont connectés à l’une des interfaces de routeur d’un réseau local. Étant donné que l’interface du routeur est normalement configurée avec un masque de sous-réseau et une adresse IP, l’interface est également considérée comme un hôte réseau sur le réseau connecté. En conséquence, le masque de sous-réseau et l’adresse réseau de l’interface sont entrés dans la table de routage stockée localement (avec le type et le numéro d’interface). L’entrée se fait en tant que réseau attaché. Un exemple courant de réseau directement connecté sont les serveurs web qui sont sur le même réseau que l’hôte informatique et constituent un réseau directement connecté dans la table de routage stockée sur la passerelle ou le routeur.
Qu’est-ce qu’un réseau distant ?
Les réseaux distants ne sont pas directement connectés à la passerelle ou au routeur du réseau. En ce qui concerne une table de routage, un réseau distant ne peut être atteint qu’en réacheminant des paquets de données vers d’autres routeurs. Ces réseaux sont ajoutés à la table de routage local par la configuration de routes de réseau statiques ou par l’utilisation d’un protocole de routage dynamique. Les routes dynamiques sont ” apprises” par le routeur en suivant le moyen le plus efficace de délivrer des paquets de données en utilisant un protocole de routage dynamique. Les administrateurs réseau sont généralement les seules personnes autorisées à configurer manuellement des itinéraires statiques vers des destinations réseau distantes.
Quels sont les problèmes avec les tables de routage ?
L’un des défis les plus importants des tables de routage modernes est la grande quantité de stockage nécessaire pour stocker les informations nécessaires pour connecter un grand nombre de périphériques informatiques en réseau sur un stockage limité sur le routeur. La technologie actuelle utilisée sur la plupart des routeurs réseau pour l’agrégation d’adresses est la technologie de routage inter-domaines de classe (CIDR). CIDR utilise un schéma de correspondance de préfixe au niveau du bit. Ce schéma repose sur le fait que chaque note d’un réseau aura une table de routage valide qui est cohérente et évitera les boucles. Malheureusement, dans le modèle de routage “Hop / Hop” actuellement utilisé, les tables ne sont pas cohérentes et les boucles se développent. Il en résulte que les paquets de données se retrouvent dans un lop sans fin et constitue un problème majeur pour le routage réseau depuis des années.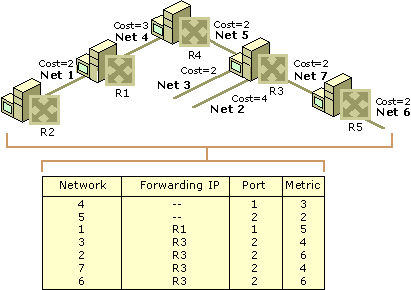
Quel est le contenu d’une table de routage ?
Bien que chaque table de routage réseau puisse contenir des informations différentes, les champs principaux de chaque table incluent: l’ID réseau, le coût ou la métrique, et le saut suivant.
ID réseau – Ce champ dans une table de routage inclura le sous-réseau d’adresse de destination.
Coût ou métrique – Ce champ enregistre la métrique ou “coût” du chemin réseau que le paquet de données sortant sera envoyé.
Saut suivant – La passerelle ou saut suivant est l’adresse de destination de l’emplacement réseau suivant auquel les paquets de données seront transmis sur leur chemin vers l’adresse IP de destination.
Les informations supplémentaires qui peuvent être trouvées dans une table de routage réseau comprennent:
Qualité de service des routes réseau – Au fil du temps, certains routeurs réseau sont conçus pour stocker une métrique de qualité de service associée à différentes routes réseau stockées dans des tables de routage. L’une de ces métriques indique simplement qu’une route donnée est opérationnelle et définit un indicateur dans la table afin d’économiser de la mémoire.
Critères de filtrage ou Listes d’accès – Cette entrée contient des informations ou des liens vers des informations contenant les dernières informations concernant les listes d’accès ou divers critères de filtrage pouvant être associés à une route de réseau donnée.
Informations d’interface réseau – Cela peut représenter des données concernant des cartes Ethernet spécifiques ou d’autres informations pouvant être utilisées pour optimiser le routage des paquets de données réseau.
Qu’est-ce qu’une table de transfert ?
Une table de transfert de réseau ou une base d’informations de transfert (FIB) est normalement utilisée lors du pontage de réseaux ou lors de diverses opérations de routage afin de localiser l’interface correcte qu’une interface d’entrée au réseau doit envoyer un paquet de données.
Les applications de tables de transfert au niveau de la couche de liaison de données
Les tables de transfert ont trouvé une certaine utilité au niveau de la couche de liaison de données. Par exemple, les protocoles MAC (contrôle d’accès aux médias) sur les réseaux locaux ont une adresse qui n’est pas significative en dehors de ce support et peuvent être stockés pour être utilisés dans une table de transfert pour faciliter le pontage Ethernet. Les autres utilisations incluent les commutateurs ATM (Mode de transfert asynchrone), les relais de trame et les MPLS (commutation d’étiquettes multiprotocoles). Pour une utilisation avec ATM, il existe à la fois des adresses locales de couche de liaison de données et d’autres qui ont une bonne importance pour une utilisation sur le réseau.
Comment les tables de transfert sont-elles utilisées avec le pontage ?
Lorsqu’un pont de couches MAC identifie l’interface à laquelle une adresse source a été vue pour la première fois, l’association avec l’interface et l’adresse est effectuée. En conséquence, lorsqu’il y a une trame reçue au pont une adresse de destination située dans la table de transfert respective, la trame sera transmise à l’interface qui a été stockée dans le FIB. Si l’adresse n’a pas été vue auparavant, elle sera traitée comme une “diffusion” et enverra les informations sur toutes les interfaces actives à l’exception de celle qui a reçu les informations.
Comment fonctionne un Relais de trame ?
Bien qu’il n’existe pas de méthode ou de processus définis de manière centralisée qui détermine le fonctionnement d’une table de transfert ou d’un relais de trame, le modèle typique trouvé dans toute l’industrie est qu’un commutateur de relais de trame aura une table de transfert définie de manière statique par interface. Une fois qu’une trame ainsi qu’un DLCI (identifiant de connexion de liaison de données) sont reçus sur une interface donnée, la table associée à l’interface fournira l’interface sortante. Cela fournit également le nouveau DLCI à insérer dans le champ d’adresse de trame de la table.
Comment Fonctionnent Les Tables De Transfert ATM ?
Un commutateur ATM contient une table de transfert de niveau de liaison similaire au modèle utilisé dans une table de relais de trame. Au lieu d’utiliser DLCI; cependant, l’interface comprend des tables de transfert qui comprennent l’identifiant de chemin virtuel, l’interface sortante et l’identifiant de circuit virtuel. La table peut être distribuée par le protocole PNNI (private network to network interface) ou définie statiquement. Quand la table est créée par PNNI, les commutateurs ATM qui sont situés sur la périphérie du réseau ou du nuage et mapperont les identifiants de bout en bout dans le réseau pour identifier le prochain saut VCI ou VPI.
Qu’est-ce que la commutation d’étiquettes multiprotocoles (MPLS)?
La commutation d’étiquettes multiprotocoles (MPLS) présente un certain nombre d’aspects similaires à l’ATM. MPSL utilise des routeurs LER (label edge routers) situés aux limites de la carte cloud MPSL située entre une étiquette locale de lien et l’identifiant de bout en bout (qui peut être une adresse IP). À chaque saut dans MPLS, une table de transfert est utilisée pour indiquer au LSR quelle interface sortante doit recevoir le paquet. Il détermine également l’étiquette à appliquer lors du transfert du paquet vers cette interface.
Quelles sont les applications des tables de transfert au niveau de la couche réseau ?
Contrairement aux tables de routage réseau, une table de transfert ou FIB est optimisée pour rechercher rapidement des informations sur une adresse de destination. Les versions antérieures des tables de transfert mettaient en cache un sous-ensemble du nombre total de routeurs les plus fréquemment utilisés pour le transfert de paquets de données. Bien que cette méthodologie ait fonctionné pour le routage au niveau de l’entreprise, lorsqu’elle était utilisée pour l’accès à l’ensemble d’Internet, les performances importantes résultaient de la nécessité d’actualiser constamment le cache relativement petit. En conséquence, les implémentations de table de transfert ont commencé à changer de méthodologie pour s’assurer qu’un FIB avait un RIB correspondant qui serait optimisé et mis à jour avec un ensemble complet de routes que le routeur de réseau avait apprises. Les améliorations supplémentaires apportées aux FIB incluent des capacités de recherche matérielle plus rapides et la mémoire TCAM (mémoire adressable de contenu ternaire). En raison du coût élevé de TCAM; cependant, cette technologie se trouve normalement sur les routeurs de périphérie.
Comment Les Tables de Transfert Aident-Elles à se défendre contre les Attaques par Déni de Service ?
Au fil du temps, l’utilisation d’une table de transfert (ou FIB) pour filtrer les paquets de données entrants est devenue une “meilleure pratique” Internet pour aider à se défendre contre les attaques par déni de service (DoS) sur un réseau. Dans la forme la plus basique, le filtrage d’entrée utilisera une liste d’accès pour déterminer à qui déposer les paquets et atténuer les dommages qu’une attaque DoS provoquera. Si le réseau a un plus grand nombre de réseaux adjacents, l’utilisation de la méthode de liste d’accès peut rapidement avoir un impact sur les performances du routeur. D’autres implémentations auront l’adresse de recherche de l’adresse source dans le FIB. S’il n’y a pas d’itinéraire enregistré vers l’adresse source de l’information, l’algorithme suppose que le paquet provient d’une adresse source usurpée ou fausse et est rejeté comme faisant peut-être partie d’une attaque DoS.
Comment les tables de transfert sont-elles utilisées pour l’Assurance de la qualité du service ?
Les tables FIB peuvent être utilisées dans un certain nombre de schémas de gestion de réseau pour garantir une qualité de service supérieure pour certains paquets de données sur le réseau. Cette différenciation peut être basée sur un champ int paquet de données eh qui indique la priorité de routage du paquet en plus de la durée pendant laquelle le paquet souhaite rester ” vivant ” en cas d’encombrement du réseau. Lorsque les routeurs prennent en charge ce type de service, ils sont généralement tenus d’envoyer le paquet de données à l’interface réseau qui “correspond le mieux” aux exigences de service des données normalement appelées DSCP (differentiated service code points). Bien que cette loi augmente légèrement la puissance de calcul globale requise pour traiter le paquet, elle n’est pas considérée comme ayant un impact significatif sur les ressources du réseau.
Leave a Reply