Validation des Données et Vérification des Données – Du Dictionnaire à l’Apprentissage Automatique
Par Aditya Aggarwal, Responsable de la pratique Analytique Avancée, et Arnab Bose, Directeur scientifique, Abzooba
Très souvent, nous utilisons la vérification des données et la validation des données de manière interchangeable lorsque nous parlons de qualité des données. Cependant, ces deux termes sont distincts. Dans cet article, nous allons comprendre la différence dans 4 contextes différents:
- Signification du dictionnaire de la vérification et de la validation
- Différence entre la vérification des données et la validation des données en général
- Différence entre la vérification et la validation du point de vue du développement logiciel
- Différence entre la vérification des données et la validation des données du point de vue de l’apprentissage automatique
Signification du dictionnaire de la vérification et de la validation
Le tableau 1 explique la signification dans le dictionnaire des mots vérification et validation avec quelques exemples.

Pour résumer, la vérification est une question de vérité et d’exactitude, tandis que la validation consiste à soutenir la force d’un point de vue ou l’exactitude d’une allégation. La validation vérifie l’exactitude d’une méthodologie tandis que la vérification vérifie l’exactitude des résultats.
Différence entre la vérification des données et la validation des données en général
Maintenant que nous comprenons le sens littéral des deux mots, explorons la différence entre “vérification des données” et “validation des données”.
- Vérification des données : pour s’assurer que les données sont exactes.
- Validation des données : pour s’assurer que les données sont correctes.
Développons avec des exemples dans le tableau 2.

Différence entre la vérification et la validation du point de vue du développement logiciel
Du point de vue du développement logiciel,
- La vérification est effectuée pour s’assurer que le logiciel est de haute qualité, bien conçu, robuste et sans erreur sans entrer dans sa convivialité.
- La validation est effectuée pour garantir la convivialité du logiciel et la capacité de répondre aux besoins du client.
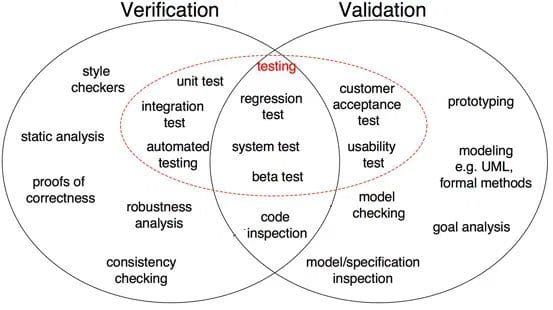
Figure 1: Différences entre la Vérification et la Validation dans le développement de logiciels (Source)
Comme le montre la figure 1, la preuve d’exactitude, l’analyse de robustesse, les tests unitaires, les tests d’intégration et autres sont toutes des étapes de vérification où les tâches sont orientées pour vérifier les spécificités. La sortie du logiciel est vérifiée par rapport à la sortie souhaitée. D’autre part, l’inspection des modèles, les tests de boîtes noires, les tests d’utilisabilité sont toutes des étapes de validation où les tâches sont orientées pour comprendre si le logiciel répond aux exigences et aux attentes.
Différence entre la vérification des données et la validation des données du point de vue de l’apprentissage automatique
Le rôle de la vérification des données dans le pipeline d’apprentissage automatique est celui d’un contrôleur d’accès. Il garantit des données précises et mises à jour au fil du temps. La vérification des données se fait principalement à la nouvelle étape d’acquisition des données, c’est-à-dire à l’étape 8 du pipeline ML, comme le montre la Fig. 2. Des exemples de cette étape consistent à identifier les enregistrements en double et à effectuer une déduplication, et à nettoyer les discordances dans les informations client dans un champ comme l’adresse ou le numéro de téléphone.
D’autre part, la validation des données (à l’étape 3 du pipeline ML) garantit que les données incrémentielles de l’étape 8 ajoutées aux données d’apprentissage sont de bonne qualité et similaires (du point de vue des propriétés statistiques) aux données d’apprentissage existantes. Par exemple, cela comprend la recherche d’anomalies de données ou la détection de différences entre les données de formation existantes et les nouvelles données à ajouter aux données de formation. Sinon, tout problème de qualité des données / différences statistiques dans les données incrémentales peut être omis et les erreurs de formation peuvent s’accumuler au fil du temps et détériorer la précision du modèle. Ainsi, la validation des données détecte les changements importants (le cas échéant) dans les données d’entraînement incrémentielles à un stade précoce, ce qui facilite l’analyse des causes profondes.
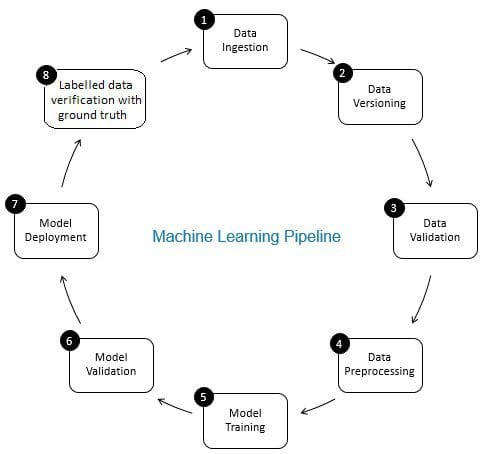
Figure 2: Composants du pipeline d’apprentissage automatique
Aditya Aggarwal est responsable de la pratique en Science des données chez Abzooba Inc. Avec plus de 12 ans d’expérience dans la réalisation d’objectifs commerciaux grâce à des solutions axées sur les données, Aditya est spécialisée dans l’analyse prédictive, l’apprentissage automatique et la stratégie d’entreprise & dans un large éventail de secteurs.
Dr. Arnab Bose est Directeur scientifique chez Abzooba, une société d’analyse de données et professeur auxiliaire à l’Université de Chicago où il enseigne l’Apprentissage Automatique et l’Analyse Prédictive, les Opérations d’Apprentissage Automatique, l’Analyse et la Prévision de Séries chronologiques et l’Analyse de la Santé dans le cadre du programme de Maîtrise en Sciences en Analyse analytique. Il est un vétéran de l’industrie de l’analyse prédictive de 20 ans qui aime utiliser des données non structurées et structurées pour prévoir et influencer les résultats comportementaux dans les soins de santé, le commerce de détail, la finance et les transports. Ses domaines d’intérêt actuels incluent la stratification des risques pour la santé et la gestion des maladies chroniques à l’aide de l’apprentissage automatique, ainsi que le déploiement et la surveillance en production de modèles d’apprentissage automatique.
Liés:
- MLOps – “Pourquoi est-ce nécessaire?” et “Qu’est-ce que c’est”?
- Mon modèle d’apprentissage automatique n’apprend pas. Que devrais-je faire?
- Observabilité des données, Partie II: Comment créer vos Propres Moniteurs de Qualité des Données À l’aide de SQL
Leave a Reply