lexikális elemzés a fordítóban
lexikális elemzés a fordítóban az első lépés a forrásprogram elemzésében. A lexikális elemzés a forrásprogramból származó bemeneti adatfolyamot karakterről karakterre olvassa, és előállítja a tokenek sorrendjét. Ezek a tokenek az elemző bemeneteként szolgálnak az elemzéshez. Ebben az összefüggésben röviden tárgyaljuk a lexikai elemzés folyamatát a lexikai hibákkal és azok helyreállításával együtt.
tartalom: Lexikális elemzés a fordítóban
- terminológiák a lexikális elemzésben
- mi a lexikális elemzés?
- példák a lexikai elemzésre
- szerepe lexikális Analyzer
- lexikális hiba
- Error Recovery
- Key Takeaways
terminológiák lexikális elemzés
mielőtt rátérnénk mi lexikális elemzés hogyan végzik beszéljünk néhány terminológiák, hogy mi lesz ráakad, miközben tárgyalunk lexikális elemzés.
- lexéma
a lexéma karaktersorozatként definiálható, amely mintát alkot és tokenként felismerhető. - Minta
a lexéma mintájának azonosítása után leírható, hogy milyen token alakítható ki. Mint például egyes lexémák mintája kulcsszót képez, egyes lexémák mintája azonosítót képez. - Token
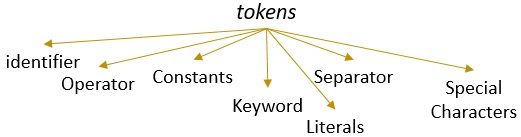
egy érvényes mintával rendelkező lexéma tokent képez. A lexikális elemzésben érvényes token lehet azonosítók, kulcsszavak, elválasztók, speciális karakterek, állandók és operátorok.
mi a lexikai elemzés?
korábban már disused mintegy lexical analyzer a mi tartalom fordító számítógép. Megtudtuk, hogy a fordító elvégzi a forrásprogram elemzését különböző fázisokon keresztül, hogy átalakítsa azt a célprogrammá. A lexikai elemzés az első szakasz, amelyet a forrásprogramnak át kell mennie.
a lexikális elemzés a tokenizálás folyamata, azaz. beolvassa a forrásprogram karakterének bemeneti karakterláncát karakterenként, és amint azonosítja a lexéma végét, azonosítja a mintáját, és tokenné alakítja.
a lexikális analizátor két egymást követő folyamatból áll, amelyek magukban foglalják a szkennelést és a lexikális elemzést.
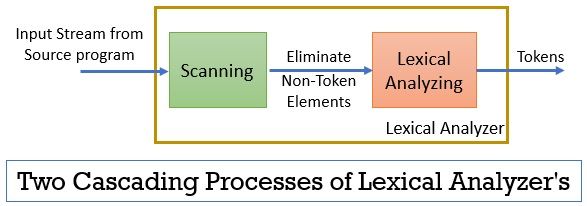
- szkennelés: a szkennelési fázis csak a nem token elemeket távolítja el a forrásprogramból. Mint például a Megjegyzések kiküszöbölése, az egymást követő fehér terek tömörítése stb.
- Lexikai Elemzés: A lexikális elemzési fázis a szkenner által biztosított kimeneten végzi a tokenizálást, ezáltal tokeneket hoz létre.
a lexikai elemzés elvégzéséhez használt programot lexer vagy lexical analyzer néven emlegetik. Most vegyünk egy példát a lexikai elemzésre, amelyet egy nyilatkozaton végeztünk:
1. példa a lexikai elemzésre:
lexikai elemzés a fordító tervezésében, azonosítsa a tokeneket.
Most, amikor elolvassuk ezt az állítást, akkor könnyen azonosíthatjuk, hogy a fenti állításban kilenc token van.
- azonosítók -> lexikális
- azonosítók -> elemzés
- azonosítók -> a
- azonosítók -> fordító
- azonosítók -> tervezés
- elválasztó -> ,
- azonosítók – > azonosítás
- azonosítók – > tokenek
- elválasztó ->.
tehát összesen 9 token van a fenti karakterfolyamban.
a lexikai Elemzés 2.példája:
printf(” I értéke %d “, i);
most próbáljunk meg tokeneket találni ebből a bemeneti adatfolyamból.
- kulcsszó – > printf
- különleges karakter -> (
- Literal – > “az I értéke %d”
- elválasztó -> ,
- Azonosító – > i
- különleges karakter -> )
- elválasztó -> ;
Megjegyzés:
- a teljes karakterlánc a kettős fordított vesszőben, azaz “” egyetlen tokennek tekinthető.
- a bemeneti adatfolyamban lévő karaktereket elválasztó üres fehér tér csak a tokeneket választja el, így a tokenek számlálása közben megszűnik.
a lexikális analizátor szerepe
a forrásprogram elemzésének első fázisaként a lexikális analizátor fontos szerepet játszik a forrásprogram célprogrammá történő átalakításában.
ez az egész forgatókönyv az alábbi ábra segítségével valósítható meg:
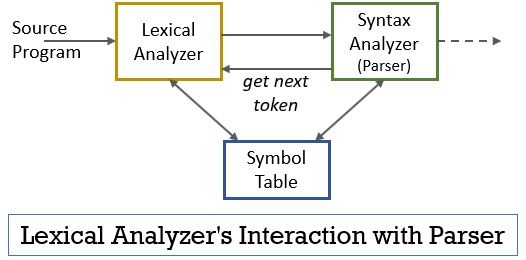
- a lexikális elemző fázisban a szkenner vagy a lexer program van megvalósítva, amely csak akkor állít elő tokeneket, ha az elemző erre utasítja őket.
- az elemző generálja a getnexttoken parancsot, és erre válaszul elküldi a lexikális analizátornak.
- amint egy token létrejön, a lexikai elemző elküldi azt a szintaxis analizátornak elemzés céljából.
- a szintaxis analizátorral együtt a lexikai analizátor is kommunikál a szimbólumtáblával. Amikor egy lexikai elemző azonosítja a lexémát azonosítóként, beírja azt a lexémát a szimbólumtáblába.
- néha az azonosító információ a szimbólumtáblában segít a lexikális analizátornak annak meghatározásában, hogy melyik tokent kell elküldeni az elemzőnek.
- amellett, hogy azonosítja a tokeneket a bemeneti adatfolyamban, a lexikális analizátor kiküszöböli az üres helyet/fehér helyet és a Program megjegyzéseit is. Ilyen egyéb dolgok közé tartoznak a karakterek, amelyek elválasztják a tokeneket, füleket, üres helyeket, új sorokat.
- a lexikális elemző segít a fordító által generált hibaüzenetek összekapcsolásában. Csak, például, a lexical analyzer tartja a rekordot minden új sor karakter jön át, miközben beolvassa a forrás programot, így könnyen kapcsolódik a Hibaüzenet a sorszámot a forrás programot.
- ha a forrásprogram makrókat használ, a lexikális elemző kibővíti a makrókat a forrásprogramban.
lexikális hiba
maga a lexikális elemző nem képes hatékonyan meghatározni a hibát a forrásprogramból. Vegyünk például egy állítást:
prtf (“I értéke %d”, i);
most, a fenti utasításban, amikor a prtf karakterlánc találkozik, a lexikai elemző nem tudja kitalálni, hogy a prtf a ‘printf’ kulcsszó helytelen helyesírása, vagy be nem jelentett függvényazonosító.
de az előre meghatározott szabály szerint a prtf egy érvényes lexéma, amelynek mintája arra a következtetésre jut, hogy azonosító token. Most a lexikai elemző prtf tokent küld a következő fázisba, azaz az elemzőbe, amely a betűk átültetése miatt bekövetkezett hibát kezeli.
Error Recovery
Nos, néha még az is lehetetlen, hogy egy lexikai elemző azonosítson egy lexémát tokenként, mivel a lexéma mintája nem egyezik a tokenek egyik előre meghatározott mintájával sem. Ebben az esetben néhány hiba-helyreállítási stratégiát kell alkalmaznunk.
- pánik mód helyreállításában az egymást követő karakter a lexémából törlődik, amíg a lexikai elemző nem azonosít egy érvényes tokent.
- távolítsa el az első karaktert a fennmaradó bemenetből.
- azonosítsa a lehetséges hiányzó karaktert, és illessze be a fennmaradó bemenetbe megfelelően.
- cseréljen le egy karaktert a fennmaradó bemenetben, hogy érvényes tokent kapjon.
- cserélje ki két szomszédos karakter helyzetét a fennmaradó bemenetben.
a fenti hibajavítási műveletek végrehajtása közben ellenőrizze, hogy a fennmaradó bemenet előtagja megfelel-e a tokenek bármely mintájának. Általában lexikai hiba fordul elő egyetlen karakter miatt. Tehát a lexikai hibát egyetlen átalakítással kijavíthatja. És amennyire csak lehetséges, kisebb számú transzformációnak kell átalakítania a forrásprogramot érvényes tokenek sorozatává, amelyet átadhat az elemzőnek.
kulcs elvihető
- lexikális elemzés az első fázis az elemzés a forrás program a fordító.
- a lexikális analizátort két egymást követő folyamat szkennerrel és lexikális elemzéssel valósítják meg.
- a szkenner eltávolítja a nem token elemeket a bemeneti adatfolyamból.
- a lexikai elemzés tokenizálást végez.
- így a lexikális analizátor tokenek sorozatát generálja és továbbítja azokat az elemzőbe.
- a lexikális analizátorból származó token birtokában lévő elemző hívást kezdeményez getNextToken amelyek ragaszkodnak ahhoz, hogy a lexikális analizátor olvassa a karakterek bemeneti adatfolyamát, amíg nem azonosítja a következő tokent.
- ha a lexikális analizátor azonosítóként azonosítja a lexéma mintáját, akkor a lexikális analizátor beírja ezt a lexémát a szimbólumtáblába későbbi felhasználás céljából.
- a Lexical analyzer önmagában nem képes azonosítani a forrásprogram hibáit.
- ha olyan lexéma fordul elő, amelynek mintája nem egyezik meg a tokenek egyik előre meghatározott mintájával sem, akkor a hiba kijavításához hibajavítási műveleteket kell végrehajtania.
tehát ez az egész a lexikális elemzésről szól, amely a karakterek folyamát tokenekké alakítja át, és átadja az elemzőnek. Megtanultuk a lexikai elemzés munkáját egy példa segítségével. A vitát a lexikális hibával és annak helyreállítási stratégiájával zártuk le.
Leave a Reply