Analisi lessicale nel compilatore
L’analisi lessicale nel compilatore è il primo passo nell’analisi del programma sorgente. L’analisi lessicale legge il flusso di input dal programma sorgente carattere per carattere e produce la sequenza di token. Questi token sono forniti come input per il parser per l’analisi. In questo contesto, discuteremo il processo di analisi lessicale in breve insieme agli errori lessicali e al loro recupero.
Contenuto: Analisi lessicale nel compilatore
- Terminologie nell’analisi lessicale
- Che cos’è l’analisi lessicale?
- Esempi di Analisi Lessicale
- Ruolo dell’Analizzatore Lessicale
- Lessicale di Errore
- Recupero di Errore
- Takeaway Chiave
Terminologie in Analisi Lessicale
Prima di entrare in quello che l’analisi lessicale è come viene eseguita parliamo di alcune terminologie che ci si troverà di fronte mentre si discute di analisi lessicale.
- Lexeme
Lexeme può essere definito come una sequenza di caratteri che forma un modello e può essere riconosciuto come un token. - Pattern
Dopo aver identificato il pattern del lessema si può descrivere quale tipo di token può essere formato. Ad esempio, il modello di alcuni lessemi forma una parola chiave, il modello di alcuni lessemi forma un identificatore. - Token
Un lessema con un modello valido forma un token. Nell’analisi lessicale, un token valido può essere identificatori, parole chiave, separatori, caratteri speciali, costanti e operatori.
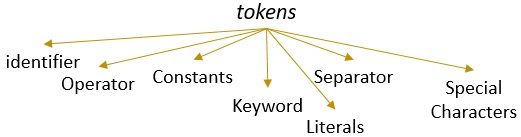
Cos’è l’analisi lessicale?
In precedenza abbiamo dismesso l’analizzatore lessicale nel nostro compilatore di contenuti nel computer. Abbiamo appreso che il compilatore esegue l’analisi del programma sorgente attraverso diverse fasi per trasformarlo nel programma di destinazione. L’analisi lessicale è la prima fase che il programma sorgente deve attraversare.
L’analisi lessicale è il processo di tokenizzazione cioè legge la stringa di input di un programma sorgente carattere per carattere e non appena identifica una fine del lessema, identifica il suo pattern e lo converte in un token.
L’analizzatore lessicale è costituito da due processi consecutivi che includono la scansione e l’analisi lessicale.
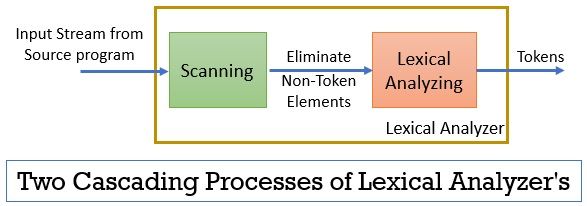
- Scansione: la sola fase di scansione elimina gli elementi non token dal programma sorgente. Come eliminare i commenti, compattare gli spazi bianchi consecutivi, ecc.
- Analisi lessicale: La fase di analisi lessicale esegue la tokenizzazione sull’output fornito dallo scanner e quindi produce token.
Il programma utilizzato per eseguire l’analisi lessicale è denominato lexer o lexical analyzer. Ora prendiamo un esempio di analisi lessicale eseguita su una dichiarazione:
Esempio 1 di analisi lessicale:
Analisi lessicale nella progettazione del compilatore, identificare i token.
Ora, quando leggeremo questa affermazione, possiamo facilmente identificare che ci sono nove token nella dichiarazione precedente.
- Identificatori -> lessicale
- Identificatori -> analisi
- Identificatori -> in
- Identificatori -> compilatore
- Identificatori -> design
- Separatore -> ,
- Identificatori -> identificare
- Identificatori -> token
- Separatore -> .
Così come in totale, ci sono 9 token nel flusso di caratteri sopra.
Esempio 2 di analisi lessicale:
printf(” il valore di i è %d “, i);
Ora proviamo a trovare i token da questo flusso di input.
- parola Chiave -> printf
- Carattere Speciale -> (
- Letterale -> “Valore di i è %d “
- Separatore -> ,
- Identificatore -> i
- Carattere Speciale -> )
- Separatore -> ;
Nota:
- L’intera stringa all’interno di doppie virgolette, ad esempio “” è considerato un unico token.
- Lo spazio vuoto che separa i caratteri nel flusso di input separa solo i token e quindi viene eliminato durante il conteggio dei token.
Ruolo dell’analizzatore lessicale
Essendo la prima fase nell’analisi del programma sorgente l’analizzatore lessicale svolge un ruolo importante nella trasformazione del programma sorgente nel programma di destinazione.
Questo intero scenario può essere realizzato con l’aiuto della figura riportata di seguito:
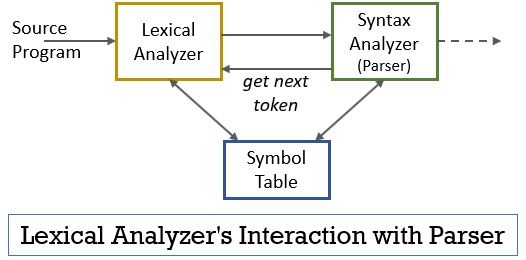
- La fase dell’analizzatore lessicale ha lo scanner o il programma lexer implementato in esso che produce token solo quando sono comandati dal parser a farlo.
- Il parser genera il comando getNextToken e lo invia all’analizzatore lessicale come risposta a questo l’analizzatore lessicale inizia a leggere il flusso di input carattere per carattere finché non identifica un lessema che può essere riconosciuto come token.
- Non appena viene prodotto un token, l’analizzatore lessicale lo invia all’analizzatore di sintassi per l’analisi.
- Insieme all’analizzatore di sintassi, l’analizzatore lessicale comunica anche con la tabella dei simboli. Quando un analizzatore lessicale identifica un lessema come identificatore, inserisce tale lessema nella tabella dei simboli.
- A volte le informazioni dell’identificatore nella tabella dei simboli aiutano l’analizzatore lessicale a determinare il token che deve essere inviato al parser.
- Oltre a identificare i token nel flusso di input, l’analizzatore lessicale elimina anche lo spazio vuoto / spazio bianco e i commenti del programma. Tali altre cose includono caratteri che separano token, schede, spazi vuoti, nuove linee.
- L’analizzatore lessicale aiuta a mettere in relazione i messaggi di errore prodotti dal compilatore. Ad esempio, l’analizzatore lessicale mantiene il record di ogni nuovo carattere di riga che incontra durante la scansione del programma sorgente in modo da collegare facilmente il messaggio di errore con il numero di riga del programma sorgente.
- Se il programma sorgente utilizza macro, l’analizzatore lessicale espande le macro nel programma sorgente.
Errore lessicale
Lo stesso analizzatore lessicale non è efficiente per determinare l’errore dal programma sorgente. Ad esempio, considera un’istruzione:
prtf (“il valore di i è %d”, i);
Ora, nell’istruzione precedente quando viene rilevata la stringa prtf, l’analizzatore lessicale non è in grado di indovinare se il prtf è un’ortografia errata della parola chiave ‘printf’ o è un identificatore di funzione non dichiarato.
Ma secondo la regola predefinita prtf è un lessema valido il cui modello lo conclude come un token identificativo. Ora, l’analizzatore lessicale invierà il token prtf alla fase successiva, ovvero il parser che gestirà l’errore che si è verificato a causa della trasposizione delle lettere.
Recupero degli errori
Beh, a volte è persino impossibile per un analizzatore lessicale identificare un lessema come token, poiché il modello del lessema non corrisponde a nessuno dei modelli predefiniti per i token. In questo caso, dobbiamo applicare alcune strategie di recupero degli errori.
- In modalità panic recovery il carattere successivo dal lessema viene eliminato fino a quando l’analizzatore lessicale identifica un token valido.
- Elimina il primo carattere dall’input rimanente.
- Identificare il possibile carattere mancante e inserirlo nell’input rimanente in modo appropriato.
- Sostituisci un carattere nell’input rimanente per ottenere un token valido.
- Scambia la posizione di due caratteri adiacenti nell’input rimanente.
Durante l’esecuzione delle azioni di ripristino degli errori di cui sopra, verificare se il prefisso dell’input rimanente corrisponde a qualsiasi modello di token. Generalmente, si verifica un errore lessicale a causa di un singolo carattere. Quindi, puoi correggere l’errore lessicale con una singola trasformazione. E per quanto possibile un numero minore di trasformazioni deve convertire il programma sorgente in una sequenza di token validi che può consegnare al parser.
Key Takeaways
- L’analisi lessicale è la prima fase nell’analisi del programma sorgente nel compilatore.
- L’analizzatore lessicale è implementato da due processi consecutivi scanner e analisi lessicale.
- Scanner elimina gli elementi non token dal flusso di input.
- L’analisi lessicale esegue la tokenizzazione.
- Pertanto, l’analizzatore lessicale genera una sequenza di token e li inoltra nel parser.
- Il parser in possesso di un token dall’analizzatore lessicale effettua una chiamata getNextToken che insiste l’analizzatore lessicale leggere il flusso di input di caratteri fino a quando non identifica il token successivo.
- Se l’analizzatore lessicale identifica il modello di un lessema come identificatore, l’analizzatore lessicale inserisce tale lessema nella tabella dei simboli per un uso futuro.
- Lexical analyzer non è efficiente per identificare eventuali errori nel solo programma sorgente.
- Se si verifica un lessema il cui pattern non corrisponde a nessuno dei pattern predefiniti di token, è necessario eseguire azioni di ripristino degli errori per correggere l’errore.
Quindi, questo riguarda l’analisi lessicale che trasforma il flusso di caratteri in token e lo passa al parser. Abbiamo imparato a conoscere il funzionamento dell’analisi lessicale con l’aiuto di un esempio. Abbiamo concluso la discussione con l’errore lessicale e la sua strategia di recupero.
Leave a Reply