Convalida dei dati e verifica dei dati-Dal dizionario all’apprendimento automatico
Di Aditya Aggarwal, Advanced Analytics Practice Lead e Arnab Bose, Chief Scientific Officer, Abzooba
Molto spesso, usiamo la verifica dei dati e la convalida dei dati in modo intercambiabile quando parliamo di qualità dei dati. Tuttavia, questi due termini sono distinti. In questo articolo, capiremo la differenza in 4 diversi contesti:
- Dizionario il significato di verifica e validazione
- Differenza tra la verifica dei dati e la convalida dei dati in generale
- Differenza tra verifica e validazione del software prospettiva di sviluppo
- Differenza tra i dati di verifica e convalida dei dati da macchina prospettiva di apprendimento
Dizionario il significato di verifica e validazione
La tabella 1 illustra dizionario il significato delle parole di verifica e di convalida, con pochi esempi.

Per riassumere, la verifica riguarda la verità e l’accuratezza, mentre la convalida riguarda il supporto della forza di un punto di vista o la correttezza di un reclamo. La convalida controlla la correttezza di una metodologia mentre la verifica controlla l’accuratezza dei risultati.
Differenza tra la verifica dei dati e la convalida dei dati in generale
Ora che comprendiamo il significato letterale delle due parole, esploriamo la differenza tra “verifica dei dati” e “convalida dei dati”.
- Verifica dei dati: per assicurarsi che i dati siano accurati.
- Convalida dei dati: per assicurarsi che i dati siano corretti.
Cerchiamo di elaborare con esempi nella Tabella 2.

Differenza tra verifica e validazione del software prospettiva di sviluppo
> > In una prospettiva di sviluppo software,
- la Verifica viene fatto per garantire che il software è di alta qualità, ben costruito, robusto e privo di errori senza fare della sua usabilità.
- La convalida viene eseguita per garantire l’usabilità del software e la capacità di soddisfare le esigenze del cliente.
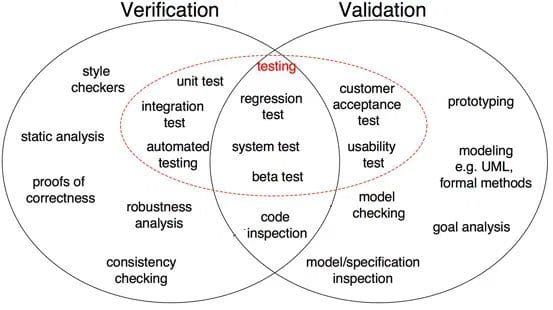
Fig 1: Differenze tra verifica e convalida nello sviluppo del software (Fonte)
Come mostrato in Fig 1, prova di correttezza, analisi di robustezza, test unitari, test di integrazione e altri sono tutti i passaggi di verifica in cui le attività sono orientate alla verifica delle specifiche. L’output del software viene verificato rispetto all’output desiderato. D’altra parte, l’ispezione del modello, il test della scatola nera, il test di usabilità sono tutti passaggi di convalida in cui le attività sono orientate a capire se il software soddisfa i requisiti e le aspettative.
Differenza tra la verifica dei dati e la convalida dei dati dal punto di vista dell’apprendimento automatico
Il ruolo della verifica dei dati nella pipeline di apprendimento automatico è quello di un gatekeeper. Garantisce dati accurati e aggiornati nel tempo. La verifica dei dati viene effettuata principalmente nella nuova fase di acquisizione dei dati, ovvero nella fase 8 della pipeline ML, come mostrato in Fig. 2. Esempi di questo passaggio sono identificare i record duplicati ed eseguire la deduplicazione e pulire la mancata corrispondenza delle informazioni del cliente in campi come indirizzo o numero di telefono.
D’altra parte, la convalida dei dati (al passaggio 3 della pipeline ML) garantisce che i dati incrementali del passaggio 8 aggiunti ai dati di apprendimento siano di buona qualità e simili (dal punto di vista delle proprietà statistiche) ai dati di allenamento esistenti. Ad esempio, ciò include la ricerca di anomalie dei dati o la rilevazione di differenze tra i dati di allenamento esistenti e i nuovi dati da aggiungere ai dati di allenamento. In caso contrario, qualsiasi problema di qualità dei dati/differenze statistiche nei dati incrementali potrebbe essere perso e gli errori di formazione possono accumularsi nel tempo e deteriorare l’accuratezza del modello. Pertanto, la convalida dei dati rileva cambiamenti significativi (se presenti) nei dati di allenamento incrementali in una fase iniziale che aiuta con l’analisi delle cause principali.
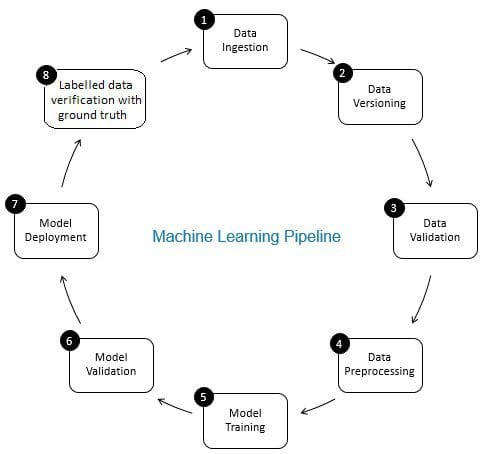
Fig 2: Componenti della pipeline di apprendimento automatico
Aditya Aggarwal serve come scienza dei dati – Pratica piombo a Abzooba Inc. Con oltre 12+ anni di esperienza nella guida degli obiettivi di business attraverso soluzioni basate sui dati, Aditya è specializzata in analisi predittiva, apprendimento automatico, business intelligence & strategia aziendale in una vasta gamma di settori.
Dott. Arnab Bose è Chief Scientific Officer presso Abzooba, una società di analisi dei dati e una facoltà aggiuntiva presso l’Università di Chicago dove insegna Machine Learning e analisi predittiva, operazioni di apprendimento automatico, analisi e previsione di serie temporali e Analisi della salute nel programma Master of Science in Analytics. È un veterano del settore dell’analisi predittiva di 20 anni che si diverte a utilizzare dati non strutturati e strutturati per prevedere e influenzare i risultati comportamentali in sanità, vendita al dettaglio, finanza e trasporti. Le sue attuali aree di interesse includono la stratificazione del rischio per la salute e la gestione delle malattie croniche utilizzando l’apprendimento automatico, e la distribuzione della produzione e il monitoraggio dei modelli di apprendimento automatico.
Correlati:
- MLOps- ” Perché è richiesto?”e” Di cosa si tratta”?
- Il mio modello di apprendimento automatico non impara. Cosa dovrei fare?
- Osservabilità dei dati, parte II: come creare i propri monitor di qualità dei dati utilizzando SQL
Leave a Reply