Tabelle di routing
Una tabella di routing è un raggruppamento di informazioni memorizzate su un computer o router di rete in rete che include un elenco di rotte verso varie destinazioni di rete. I dati vengono normalmente memorizzati in una tabella di database e in configurazioni più avanzate include metriche delle prestazioni associate ai percorsi memorizzati nella tabella. Ulteriori informazioni memorizzate nella tabella includeranno la topologia di rete più vicina al router. Sebbene una tabella di routing sia regolarmente aggiornata dai protocolli di routing di rete, le voci statiche possono essere effettuate tramite un’azione manuale da parte di un amministratore di rete.
Come funziona una tabella di routing?
Le tabelle di routing funzionano in modo simile a come l’ufficio postale consegna la posta. Quando un nodo di rete su Internet o una rete locale deve inviare informazioni a un altro nodo, richiede prima un’idea generale di dove inviare le informazioni. Se il nodo o l’indirizzo di destinazione non è collegato direttamente al nodo di rete, le informazioni devono essere inviate tramite altri nodi di rete. Per risparmiare risorse, la maggior parte dei nodi della rete locale non manterrà una tabella di routing complessa. Invece, invieranno pacchetti IP di informazioni a un gateway di rete locale. Il gateway mantiene la tabella di routing principale per la rete e invierà il pacchetto di dati alla posizione desiderata. Al fine di mantenere un record di come instradare le informazioni, il gateway utilizzerà una tabella di routing che tiene traccia della destinazione appropriata per i pacchetti di dati in uscita.
Tutte le tabelle di routing mantengono elenchi di tabelle di routing per le destinazioni raggiungibili dalla posizione del router. Questo include l’indirizzo del prossimo dispositivo collegato in rete sul percorso di rete per l’indirizzo di destinazione che è anche chiamato il “prossimo hop.”Mantenendo informazioni accurate e coerenti sui nodi di rete, l’invio di un pacchetto di dati lungo il percorso più breve verso l’indirizzo di destinazione su Internet normalmente è sufficiente per fornire traffico di rete ed è una delle caratteristiche di base della reteSI e degli strati di rete IP della teoria della rete.
Qual è la funzione primaria di un router di rete?
La funzione principale di un router di rete è quella di inoltrare i pacchetti di dati alla rete di destinazione inclusa nell’indirizzo IP di destinazione del pacchetto di dati in uscita. Al fine di determinare la destinazione appropriata del pacchetto di dati, il router esegue una ricerca degli indirizzi di destinazione memorizzati nella tabella di routing La tabella di routing è memorizzata nella RAM sul router gateway della rete e include informazioni sulle reti di destinazione e le associazioni “next hop” per tali indirizzi. Queste informazioni aiutano il router sia determinare e identificare la migliore posizione in uscita per il pacchetto di dati da inviare per trovare la destinazione finale della rete. Questa posizione può anche essere l’interfaccia gateway di qualsiasi rete collegata direttamente.
Che cos’è una rete connessa direttamente?
Le reti collegate direttamente sono collegate a una delle interfacce router di una rete locale. Poiché l’interfaccia del router è normalmente configurata con una subnet mask e un indirizzo IP, l’interfaccia è anche considerata un host di rete sulla rete collegata. Di conseguenza, sia la subnet mask che l’indirizzo di rete dell’interfaccia vengono inseriti nella tabella di routing memorizzata localmente (insieme al tipo e al numero di interfaccia). La voce è fatta come una rete collegata. Un esempio comune di una rete collegata direttamente sono i server Web che si trovano sulla stessa rete dell’host del computer e costituiscono una rete collegata direttamente nella tabella di routing memorizzata sul gateway o sul router.
Che cos’è una rete remota?
Le reti remote non sono direttamente collegate al gateway o al router sulla rete. Per quanto riguarda una tabella di routing, una rete remota può essere raggiunta solo inoltrando pacchetti di dati ad altri router. Queste reti vengono aggiunte alla tabella di routing locale attraverso la configurazione di percorsi di rete statici o mediante l’uso di un protocollo di routing dinamico. I percorsi dinamici vengono “appresi” dal router tracciando i mezzi più efficienti per fornire pacchetti di dati utilizzando un protocollo di routing dinamico. Gli amministratori di rete saranno in genere gli unici individui autorizzati a configurare manualmente i percorsi statici verso le destinazioni di rete remote.
Quali sono alcuni problemi con le tabelle di routing?
Una delle sfide più significative con le moderne tabelle di routing è la grande quantità di spazio di archiviazione necessario per memorizzare le informazioni necessarie per collegare un gran numero di dispositivi di elaborazione in rete su storage limitato sul router. L’attuale tecnologia utilizzata sulla maggior parte dei router di rete per l’aggregazione degli indirizzi è la tecnologia CIDR (Class Inter-Domain Routing). CIDR fa uso di uno schema di corrispondenza del prefisso bit a bit. Questo schema si basa sul fatto che ogni nota in una rete avrà una tabella di routing valida che è coerente e eviterà i loop. Sfortunatamente, nel modello di routing “Hop/Hop” attualmente impiegato, le tabelle non sono coerenti e i loop si sviluppano. Ciò si traduce in pacchetti di dati che si trovano in un lop senza fine ed è stato un grosso problema per il routing di rete per anni.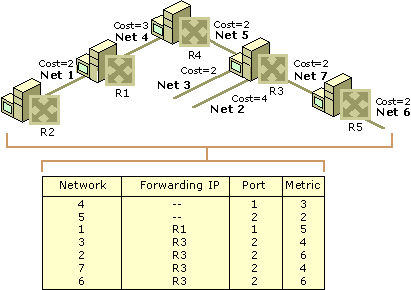
Quali sono i contenuti di una tabella di routing?
Sebbene ogni tabella di routing di rete possa contenere informazioni diverse, i campi primari di ogni tabella includono: l’ID di rete, il costo o la metrica e il salto successivo.
ID di rete: questo campo in una tabella di routing includerà la sottorete dell’indirizzo di destinazione.
Costo o metrica: questo campo consente di risparmiare la metrica o il “costo” del percorso di rete che verrà inviato al pacchetto di dati in uscita.
Next Hop-Il gateway o next hop è l’indirizzo di destinazione del percorso di rete successivo a cui verranno trasmessi i pacchetti di dati nel loro percorso verso l’indirizzo IP di destinazione.
Le informazioni aggiuntive che possono essere trovate in una tabella di routing di rete includono:
Network Route Quality of Service – Nel corso del tempo, alcuni router di rete sono progettati per memorizzare una metrica di qualità del servizio associata a diversi percorsi di rete memorizzati nelle tabelle di routing. Una di queste metriche indica semplicemente che un determinato percorso è operativo e imposta un flag nella tabella per risparmiare memoria.
Criteri di filtraggio o elenchi di accesso-Questa voce contiene informazioni o collegamenti a informazioni che contengono le informazioni più recenti relative agli elenchi di accesso o ai vari criteri di filtraggio che possono essere associati a una determinata rotta di rete.
Informazioni sull’interfaccia di rete: possono rappresentare dati relativi a specifiche schede Ethernet o altre informazioni che possono essere utilizzate per ottimizzare il routing dei pacchetti di dati di rete.
Che cos’è una tabella di inoltro?
Una tabella di inoltro di rete o FIB (forwarding Information Base) viene normalmente utilizzata quando si collegano reti o si eseguono varie operazioni di routing per aiutare a individuare l’interfaccia corretta che un’interfaccia di input alla rete dovrebbe inviare un pacchetto di dati.
Le applicazioni delle tabelle di inoltro a livello di collegamento dati
Le tabelle di inoltro hanno trovato un certo utilizzo a livello di collegamento dati. Ad esempio, i protocolli MAC (media access control) sulle reti locali hanno un indirizzo non significativo al di fuori di questo supporto e possono essere memorizzati per l’uso in una tabella di inoltro per aiutare con il bridging Ethernet. Altri usi includono ATM (Asynchronous Transfer Mode) interruttori, frame relè, e MPLS (multiprotocol label switching). Per l’utilizzo con ATM, ci sono sia gli indirizzi locali del livello di collegamento dati che altri che hanno una discreta quantità di significato per l’uso sulla rete.
Come vengono utilizzate le tabelle di inoltro con il Bridging?
Quando un layer bridge MAC identifica l’interfaccia che un indirizzo di origine è stato visto per la prima volta, viene effettuata l’associazione con l’interfaccia e l’indirizzo. Di conseguenza, quando c’è un frame ricevuto al bridge un indirizzo di destinazione situato nella rispettiva tabella di inoltro, il frame verrà trasmesso all’interfaccia che è stata memorizzata nel FIB. Se l’indirizzo non è stato visto in precedenza, verrà trattato come una” trasmissione ” e invierà le informazioni su tutte le interfacce attive ad eccezione di quella che ha ricevuto le informazioni.
Come funziona un Frame Relay?
Sebbene non esista un metodo o un processo definito centralmente che determini come funziona una tabella di inoltro o un relè frame, il modello tipico trovato in tutto il settore è che uno switch frame relay avrà una tabella di inoltro definita staticamente per interfaccia. Una volta ricevuto un frame insieme a un DLCI (data link Connection identifier) su una determinata interfaccia, la tabella associata all’interfaccia fornirà l’interfaccia in uscita. Ciò fornisce anche il nuovo DLCI da inserire nel campo indirizzo frame nella tabella.
Come funzionano le tabelle di inoltro ATM?
Uno switch ATM contiene una tabella di inoltro a livello di collegamento simile al modello utilizzato in una tabella di relè frame. Invece di usare DLCI; tuttavia, l’interfaccia include tabelle di inoltro che includono l’identificatore del percorso virtuale, l’interfaccia in uscita e l’identificatore del circuito virtuale. La tabella può essere distribuita dal protocollo PNNI (private network to network interface) o definita staticamente. Quando la tabella viene creata da PNNI, gli interruttori ATM che si trovano sul bordo della rete o il cloud e mapperà gli identificatori end-to-end nella rete per identificare il prossimo hop VCI o VPI.
Che cos’è il Multiprotocollo Label Switching (MPLS)?
Multiprotocollo Label Switching (MPLS) ha una serie di aspetti che sono simili a ATM. MPSL utilizza LER (label edge router) che si trovano sui confini della mappa cloud MPSL situata tra un’etichetta locale di collegamento e l’identificatore end-to-end (che può essere un indirizzo IP). Ad ogni hop in MPLS, viene utilizzata una tabella di inoltro per indicare all’LSR quale interfaccia in uscita dovrebbe ricevere il pacchetto. Determina anche quale etichetta applicare quando si inoltra il pacchetto a quell’interfaccia.
Quali sono le applicazioni delle tabelle di inoltro a livello di rete?
A differenza delle tabelle di routing di rete, una tabella di inoltro o FIB è ottimizzata per cercare rapidamente un indirizzo di destinazione per informazioni. Le versioni precedenti delle tabelle di inoltro memorizzavano nella cache un sottoinsieme del numero totale di router utilizzati più frequentemente per l’inoltro dei pacchetti di dati. Sebbene questa metodologia abbia funzionato per il routing a livello aziendale, quando utilizzata per l’accesso a Internet intero, risultati significativi delle prestazioni sono dovuti alla necessità di aggiornare costantemente la cache relativamente piccola. Di conseguenza, le implementazioni della tabella di inoltro hanno iniziato a spostare la metodologia per garantire che un FIB avesse una COSTOLA corrispondente che sarebbe stata ottimizzata e aggiornata con un set completo di percorsi appresi dal router di rete. Ulteriori miglioramenti apportati ai FIBs includono funzionalità di ricerca hardware più veloci e TCAM (ternary content addressable memory). A causa del costo elevato di TCAM; tuttavia, questa tecnologia si trova normalmente sui router edge.
In che modo le tabelle di inoltro aiutano a difendersi dagli attacchi Denial of Service?
Nel corso del tempo, l’utilizzo di una tabella di inoltro (o FIB) per aiutare a filtrare i pacchetti di dati in entrata è diventata una “best practice” di Internet per aiutare a difendersi dagli attacchi DoS (Denial of Service) su una rete. Nella forma più semplice, ingress filtering utilizzerà un elenco di accesso per determinare da chi eliminare i pacchetti e mitigare i danni che un attacco DoS otterrà. Se la rete ha un numero maggiore di reti adiacenti, l’uso del metodo access list può rapidamente influire sulle prestazioni del router. Altre implementazioni avranno l’indirizzo cerca l’indirizzo di origine nel FIB. SE non viene salvata la rotta verso l’indirizzo di origine delle informazioni, l’algoritmo presuppone che il pacchetto provenga da un indirizzo di origine falsificato o falso e viene scartato come possibile parte di un attacco DoS.
Come vengono utilizzate le tabelle di inoltro per la garanzia della qualità del servizio?
Le tabelle FIB possono essere utilizzate in una serie di schemi di gestione della rete per garantire una maggiore qualità del servizio per determinati pacchetti di dati sulla rete. Questa differenziazione può essere basata su un pacchetto di dati int eh campo che indica la priorità di routing del pacchetto in aggiunta a quanto tempo il pacchetto desidera rimanere “vivo” in caso di congestione della rete. Quando i router supportano questo tipo di servizio, in genere sono tenuti a inviare il pacchetto di dati all’interfaccia di rete che “meglio” corrisponde ai requisiti di servizio dei dati normalmente chiamati DSCP (differentiated service code points). Sebbene questo act aumenti leggermente la potenza di calcolo complessiva necessaria per elaborare il pacchetto, l’act non è considerato un impatto significativo sulle risorse di rete.
Leave a Reply