コンパイラでの字句解析
コンパイラでの字句解析は、ソースプログラムの分析の最初のステップです。 字句解析では、ソースプログラムから入力ストリームを文字ごとに読み取り、トークンのシーケンスを生成します。 これらのトークンは、解析のためのパーサーへの入力として提供されます。 この文脈では、字句解析のプロセスと字句エラーとその回復について簡単に議論します。
コンテンツ: コンパイラでの字句解析
- 字句解析の用語
- 字句解析とは何ですか?
- 字句解析の例
- 字句解析の役割
- 字句エラー
- エラー回復
- キーテイクアウト
字句解析における用語
字句解析がどのように実行されるかについて説明する前に、字句解析について議論しながら遭遇するいくつかの用語について話しましょう。
- 字句
字句は、パターンを形成し、トークンとして認識できる一連の文字として定義することができます。 - パターン
字句のパターンを特定した後、どのようなトークンを形成できるかを記述することができます。 いくつかの語彙素のパターンがキーワードを形成するように、いくつかの語彙素のパターンが識別子を形成する。 - トークン
有効なパターンを持つ字句はトークンを形成します。 字句解析では、有効なトークンは、識別子、キーワード、区切り文字、特殊文字、定数、および演算子にすることができます。
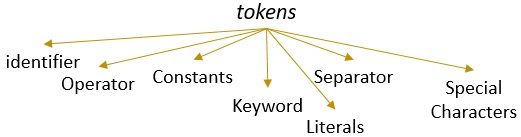
字句解析とは何ですか?
以前は、コンピュータのコンテンツコンパイラで字句解析器について使用していませんでした。 コンパイラはソースプログラムの分析を異なるフェーズで実行し、ターゲットプログラムに変換することを学びました。 字句解析は、ソースプログラムが通過しなければならない最初の段階です。
字句解析は、トークン化のプロセスです。 ソースプログラムの入力文字列を文字ごとに読み取り、字句の終わりを識別するとすぐに、そのパターンを識別してトークンに変換します。
字句解析は、スキャンと字句解析を含む二つの連続したプロセスで構成されています。
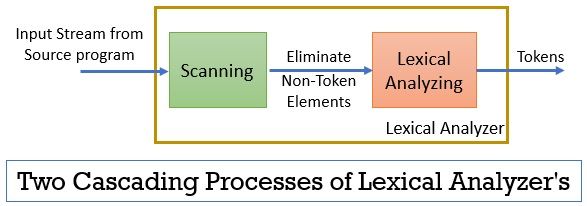
- スキャン:スキャンフェーズ-ソースプログラムから非トークン要素のみを削除します。 コメントを削除したり、連続した空白を圧縮したりするなどです。
- 字句解析: 字句解析フェーズでは、スキャナによって提供される出力に対してトークン化が実行され、トークンが生成されます。
字句解析を行うために使用されるプログラムは、lexerまたはlexical analyzerと呼ばれます。 ここで、文に対して実行される字句解析の例を見てみましょう:
字句解析の例1:
字句解析コンパイラ設計では、トークンを識別します。
さて、この声明を読むと、上記の声明に九つのトークンがあることを簡単に識別できます。
- 識別子->語彙
- 識別子->分析
- 識別子->で
- 識別子->コンパイラ
- 識別子->デザイン
- セパレータ-> ,
- 識別子->識別
- 識別子->トークン
- 区切り文字->を識別します。
合計で、上記の文字列には9つのトークンがあります。
字句解析の例2:
printf(“value of i is%d”,i);
この入力ストリームからトークンを見つけようとしましょう。
- キーワード->printf
- 特殊文字-> (
- リテラル->”iの値は%dです”
- 区切り文字-> ,
- 識別子->i
- 特殊文字-> )
- セパレータ-> ;
メモ:
- 二重反転カンマ内の文字列全体、すなわち””は単一のトークンとみなされます。
- 入力ストリーム内の文字を区切る空白の空白は、トークンのみを区切るため、トークンをカウントする間は削除されます。
字句解析器の役割
ソースプログラムの解析の第一段階字句解析器は、ソースプログラムからターゲットプログラムへの変換において重要な役割を果た
このシナリオ全体は、以下の図の助けを借りて実現することができます:
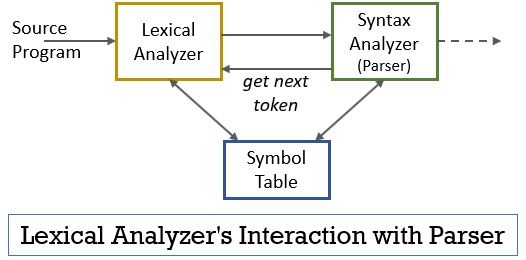
- 字句解析フェーズには、スキャナまたは字句解析プログラムが実装されており、パーサーによって指示された場合にのみトークンを生成します。
- パーサーはgetNextTokenコマンドを生成し、これに対する応答として字句アナライザに送信します。
- トークンが生成されるとすぐに、字句アナライザは構文解析のために構文アナライザに送信します。
- 構文アナライザとともに、字句アナライザもシンボルテーブルと通信します。 字句アナライザが識別子として字句を識別すると、その字句がシンボルテーブルに入力されます。
- シンボルテーブル内の識別子の情報は、構文解析器に送信する必要があるトークンを決定する際に字句解析器に役立つことがあります。
- 入力ストリーム内のトークンを識別することとは別に、字句解析器は空白/空白とプログラムのコメントも排除します。 このような他のものには、区切りトークン、タブ、空白、新しい行が含まれます。
- 字句アナライザは、コンパイラによって生成されたエラーメッセージを関連付けるのに役立ちます。 たとえば、lexical analyzerは、ソースプログラムをスキャンしている間に遭遇する各行の記録を保持するので、エラーメッセージとソースプログラムの行番号を簡単に関
- ソースプログラムがマクロを使用する場合、字句アナライザはソースプログラム内のマクロを展開します。
字句エラー
字句アナライザ自体は、ソースプログラムからのエラーを判断するのに効率的ではありません。 たとえば、次の文を考えます。
prtf(“iの値は%d”,i);
さて、上記の文で文字列prtfが検出されたとき、字句解析器はprtfがキーワード’printf’の誤ったスペルであるか、宣言されていない関数識別子であるかを推測できま
しかし、事前定義されたルールによれば、prtfは有効な語彙素であり、そのパターンは識別子トークンであると結論づけます。 これで、字句解析器はprtfトークンを次のフェーズ、つまり文字の転置のために発生したエラーを処理するパーサーに送信します。
エラー回復
語彙素のパターンがトークンの事前定義されたパターンのいずれとも一致しないため、字句解析器が語彙素をトークンとして識別すること この場合、いくつかのエラー回復戦略を適用する必要があります。
- パニック-モード-リカバリでは、字句解析器が有効なトークンを識別するまで、字句からの連続する文字が削除されます。
- 残りの入力から最初の文字を削除します。
- 欠落している可能性のある文字を特定し、残りの入力に適切に挿入します。
- 有効なトークンを取得するには、残りの入力の文字を置き換えます。
- 残りの入力で隣接する二つの文字の位置を交換します。
上記のエラー回復アクションを実行している間、残りの入力のプレフィックスがトークンのパターンと一致するかどうかを確認します。 一般的に、字句エラーは、単一の文字のために発生します。 したがって、単一の変換で字句誤差を修正することができます。 また、可能な限り、より少ない数の変換は、ソースプログラムをパーサーに引き渡すことができる一連の有効なトークンに変換する必要があります。
キーテイクアウト
- 字句解析は、コンパイラのソースプログラムの解析の最初のフェーズです。
- 字句解析は、スキャナと字句解析の二つの連続したプロセスによって実装されています。
- Scannerは、入力ストリームから非トークン要素を削除します。
- 字句解析はトークン化を実行します。
- したがって、字句解析器は一連のトークンを生成し、それらをパーサーに転送します。
- 字句解析器からのトークンを所有しているパーサーは、次のトークンを識別するまで字句解析器が文字の入力ストリームを読み取ることを要求するgetNextTokenを呼
- 字句解析器が字句のパターンを識別子として識別する場合、字句解析器は将来の使用のためにその字句をシンボルテーブルに入力します。
- Lexical analyzerは、ソースプログラムだけでエラーを識別するのに効率的ではありません。
- パターンが定義済みのトークンのパターンと一致しない字句が発生した場合は、エラー回復アクションを実行してエラーを修正する必要があります。
したがって、これはすべて、文字のストリームをトークンに変換し、それをパーサーに渡す字句分析に関するものです。 私たちは、例の助けを借りて字句解析の作業について学びました。 字句誤差とその回復戦略について議論を終えた。
Leave a Reply