データ検証とデータ検証–辞書から機械学習へ
By Aditya Aggarwal,Advanced Analytics Practice Lead,And Arnab Bose,Chief Scientific Officer,Abzooba
データ品質について話すとき、データ検証とデータ検証を交互に使用することがよくあります。 しかし、これらの2つの用語は区別されます。 この記事では、4つの異なるコンテキストの違いを理解します:
- 辞書検証と検証の意味
- 一般的なデータ検証とデータ検証の違い
- ソフトウェア開発の観点からの検証と検証の違い
- 機械学習の観点からのデータ検証とデータ検証の違い
辞書検証と検証の意味
表1は、単語の検証と検証の辞書の意味をいくつかの例で説明しています。

要約すると、検証は真実と正確さに関するものであり、検証は視点の強さまたは主張の正しさを支持することに関するものです。 検証はメソドロジの正確さをチェックし、検証は結果の正確さをチェックします。
データ検証とデータ検証の違い一般的に
二つの言葉の文字通りの意味を理解したので、”データ検証”と”データ検証”の違いを見てみましょう。
- データ検証:データが正確であることを確認します。
- データ検証:データが正しいことを確認します。
表2の例について詳しく説明しましょう。

ソフトウェア開発の観点から見た検証と検証の違い
ソフトウェア開発の観点から見た検証と検証の違い,
- 検証は、ソフトウェアがその使いやすさに入ることなく、高品質、よく設計された、堅牢でエラーのないものであることを確認するために行われます。
- 検証は、ソフトウェアの使いやすさと顧客のニーズを満たす能力を確保するために行われます。
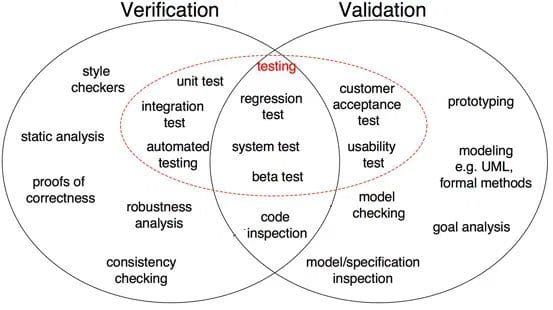
図1: ソフトウェア開発における検証と検証の違い(出典)
図1に示すように、正しさの証明、ロバスト性分析、単体テスト、統合テストなどはすべて、タスクが詳細を検証するように指向された検証ステップです。 ソフトウェア出力は、目的の出力に対して検証されます。 一方、モデル検査、ブラックボックステスト、ユーザビリティテストは、ソフトウェアが要件と期待を満たしているかどうかを理解するためのタスク
機械学習の観点から見たデータ検証とデータ検証の違い
機械学習パイプラインにおけるデータ検証の役割はゲートキーパーの役割です。 これにより、時間の経過とともに正確で更新されたデータが保証されます。 データ検証は、主に、新しいデータ収集段階、すなわち、図8に示されるように、MLパイプラインのステップ8で行われる。 2. この手順の例としては、重複レコードを識別して重複排除を実行し、住所や電話番号などのフィールドの顧客情報の不一致を消去することがあります。
一方、データ検証(MLパイプラインのステップ3)は、学習データに追加されるステップ8からの増分データの品質が良好であり、(統計的特性の観点から)既存のトレーニングデータと類似していることを保証します。 例えば、これには、データ異常の検出、または既存のトレーニングデータと、トレーニングデータに追加される新しいデータとの間の差異の検出が含まれます。 そうしないと、増分データのデータ品質の問題/統計的差異が見逃され、トレーニングエラーが時間の経過とともに蓄積され、モデルの精度が低下する可能性が したがって、データ検証は、根本原因分析に役立つ増分トレーニングデータの大幅な変更(ある場合)を初期段階で検出します。
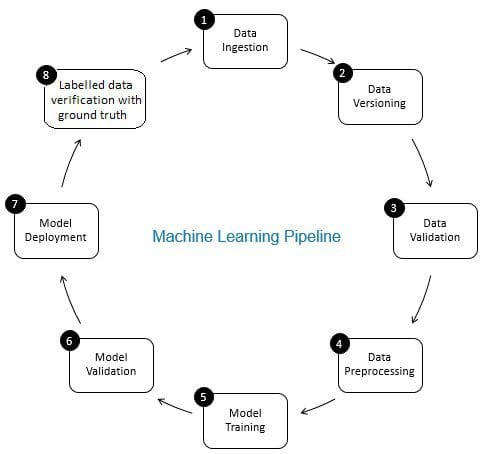
図2:機械学習パイプラインのコンポーネント
Aditya AggarwalはAbzooba Inc.でデータ–サイエンス-プラクティス-リードを務めています。 Adityaは、データ駆動型ソリューションを通じてビジネス目標を推進する12年以上の経験を持ち、予測分析、機械学習、ビジネスインテリジェンス&ビジネス戦略
Arnab Boseは、データ分析会社であり、シカゴ大学の非常勤教員であるAbzoobaの最高科学責任者であり、Master of Science in Analyticsプログラムで機械学習と予測分析、機械学習操作、時系列分析と予測、および健康分析を教えています。 彼は20年の予測分析業界のベテランであり、非構造化および構造化データを使用して、医療、小売、金融、輸送における行動成果を予測し、影響を与えるこ 彼の現在の焦点領域には、機械学習を使用した健康リスクの層別化と慢性疾患管理、機械学習モデルの生産展開と監視が含まれます。
関連:
- MLOps–”なぜそれが必要ですか?”そして、”それは何ですか”?
- 私の機械学習モデルは学習しません。 どうすればいいですか?
- データ可観測性、パートII:SQLを使用して独自のデータ品質モニターを構築する方法
Leave a Reply