実験における無作為割付け
実験研究では、無作為割付けは、ランダム化を使用してサンプルからの参加者を異なる治療グループに配置する方法です。
単純なランダムな割り当てでは、サンプルのすべてのメンバーは、対照群または実験群に配置される可能性が既知または同等です。 単純な無作為割付けを使用する研究は、完全無作為化計画とも呼ばれます。
ランダムな割り当ては実験設計の重要な部分です。 それはあなたが研究の開始時にすべてのグループが同等であることを確認するのに役立ちます:それらの間の違いは変量要因によるものです。
ランダムな割り当てが重要なのはなぜですか?
ランダムな割り当ては、実験の内部的妥当性を強化するのに役立つため、実験研究における制御の重要な部分です。
実験では、研究者は独立変数を操作して従属変数への影響を評価し、他の変数を制御します。 そのために、参加者のグループごとに異なるレベルの独立変数を使用することがよくあります。
これは、グループ間または独立した尺度設計と呼ばれます。
独立変数のレベルが異なる3つの参加者グループを使用します:
- プラセボを投与された対照群(投与量なし)、
- 低用量を投与された実験群、
- 高用量を投与された第2の実験群。
ランダムな割り当ては、実験の開始時に治療群が体系的または偏った方法で異ならないことを確認するのに役立ちます。
ランダムな割り当てを使用しない場合、結果の代替説明を除外できない場合があります。
- カフェから募集された参加者は対照群に、
- 地元コミュニティセンターから募集された参加者は低用量実験群に、
- ジムから募集された参加者は高
このタイプの課題では、研究の開始時に参加者の特性がすべてのグループで同じであるかどうかを判断するのは難しいです。 ジムユーザーは、カフェやコミュニティセンターを頻繁に使用する人よりも健康的な行動に従事する傾向があり、これはあなたの研究に健康的なユーザーバイア
あなたの研究成果が高用量群でより多くのエネルギーを示している場合、あなたはこの結果をあなたの独立変数操作(鉄サプリメント)にのみ帰 代わりに、この結果は、参加者の特性と独立変数との間の相互作用から来る可能性があります。
ランダムな割り当てはグループ間のベースラインの違いをも助けますが、必ずしもそれらを完全に同等にするとは限りません。 グループ間で異なる無関係な変数が存在する可能性があり、常に偶然から生じるいくつかのグループの違いがあります。
ほとんどの場合、グループ間のランダムな変動は低く、したがって、さらなる分析には許容されます。 これは、大きなサンプルがある場合に特に当てはまります。 一般に、倫理的に可能であり、研究トピックに理にかなっている場合は、常に実験でランダム割り当てを使用する必要があります。
ランダムサンプリングとランダム割り当て
ランダムサンプリングとランダム割り当てはどちらも研究において重要な概念ですが、それらの違いを理解することが重要です。
ランダムサンプリング(確率サンプリングまたはランダム選択とも呼ばれます)は、研究に含める母集団のメンバーを選択する方法です。 対照的に、ランダム割り当ては、サンプル参加者を対照グループと実験グループに分類する方法です。
ランダムサンプリングは多くの種類の研究で使用されていますが、ランダム割り当ては被験者間の実験計画でのみ使用されます。
無作為抽出と無作為割り当ての両方を使用する研究もあれば、どちらか一方のみを使用する研究もあります。
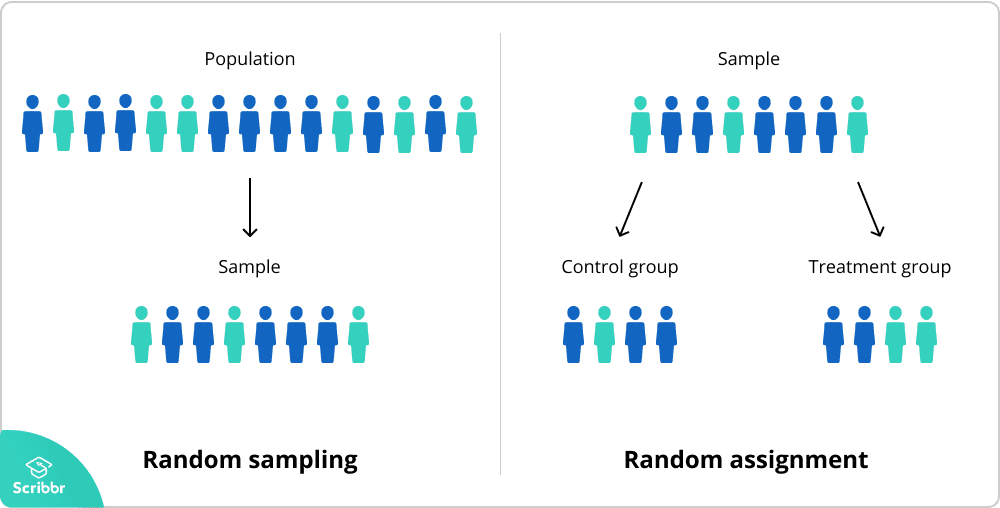
ランダムサンプリングは、サンプルが不偏で母集団全体を代表することを確実にするのに役立つため、結果の外部妥当性または一般化可能性を高めます。 これにより、より強力な統計的推論を行うことができます。
単純な無作為標本を使用してデータを収集します。 母集団全体(全従業員)にアクセスできるため、8000人の従業員すべてに番号を割り当て、乱数ジェネレータを使用して300人の従業員を選択できます。 これらの300人の従業員はあなたの完全なサンプルです。
無作為なサンプルを使用することにより、結果が会社全体に適用されることを合理的に確信することができます。
ランダム割り当ては、各グループの参加者の間に体系的な違いがないことを保証するため、研究の内部妥当性を高めます。 これは、結果が独立変数に起因する可能性があると結論づけるのに役立ちます。
- 介入を受けない対照群。
- 1ヶ月間、毎週遠隔のチームビルディング介入を行う実験グループ。
ランダムな割り当てを使用して、参加者をコントロールグループまたは実験グループに配置します。 これを行うには、参加者のリストを取得し、各参加者に番号を割り当てます。 ここでも、乱数発生器を使用して、各参加者を2つのグループのいずれかに配置します。
ランダムな割り当てを使用すると、従業員のエンゲージメントの結果の違いは、チームビルディングの介入の影響であり、グループ間の他の違いによっ
どのようにランダムな割り当てを使用していますか?
単純なランダム割り当てを使用するには、サンプルのすべてのメンバーに一意の番号を与えることから始めます。 次に、コンピュータプログラムまたは手動の方法を使用して、各参加者をランダムにグループに割り当てることができます。
- 乱数発生器: コンピュータプログラムを使用して、各グループのリストから乱数を生成します。
- 抽選方法:すべての数字を帽子やバケツに個別に置き、グループごとにランダムに数字を描きます。
- コインを反転:あなたが唯一の二つのグループを持っている場合、リスト上の各番号について、彼らはコントロールまたは実験グループになるかどうかを決定す
- サイコロを使う:三つのグループがあるときは、リスト上の各番号について、彼らがどのグループになるかを決定するためにサイコロを転がします。 たとえば、1または2を転がすと、それらが対照群に着地すると仮定します; は実験群で3または4;および第2の対照群または実験群で5または6である。
このタイプのランダム割り当ては、各個人があなたの治療グループのいずれかに配置される可能性が等しいため、参加者を条件に配置する最も強力
ブロック設計におけるランダム割り当て
より複雑な実験設計では、ランダム割り当ては、参加者が何らかの特性(テストスコアや人口統計変数など)に基づいてブロックにグループ化された後にのみ使用されます。 これらのグループ化は、高い統計的検出力を達成するために、より大きなサンプルが必要であることを意味します。
例えば、無作為化ブロック設計では、共有特性(大学生対卒業生など)に基づいて参加者をブロックに配置し、各ブロック内のランダム割り当てを使用して、参加者をすべての治療条件に割り当てることが含まれます。 これは特徴があなたの処置の結果に影響を与えるかどうか査定するのを助けます。
実験的に一致させた計画では、ブロックを使用し、特定の特性に基づいて各ブロックの個々の参加者を一致させます。 各一致したペアまたはグループ内で、各参加者を実験のいずれかの条件にランダムに割り当て、それらの結果を比較します。
ランダム割り当てはいつ使用されないのですか?
単純なランダムな割り当てを使用することは、時には関連性や倫理的ではないため、グループは別の方法で割り当てられます。
異なるグループを比較する場合
場合によっては、参加者間の違いが研究の主な焦点であり、例えば、男性と女性、または健康状態のある人とない人 参加者は、ランダムに異なるグループに割り当てられていませんが、代わりに彼らの特性に基づいて割り当てられています。
このタイプの研究では、関心のある特性(例えば、性別)は独立変数であり、グループは異なるレベル(例えば、男性、女性など)に基づいて異なります。). すべての参加者が同じ方法でテストされ、グループレベルの結果が比較されます。
倫理的に許容されない場合
不健康な行動や危険な行動を勉強するとき、ランダムな割り当てを使用することはできません。 たとえば、重い酒飲みと社会的な酒飲みを研究している場合、2つのグループのいずれかに参加者をランダムに割り当て、実験のために大量のアルコールを
参加者をグループに割り当てることができない場合は、準実験的な研究も行うことができます。 準実験では、あなたがコントロールできないかもしれない治療を受けている既存のグループ(例えば、重い飲酒者や社会的飲酒者)の結果を研究します。 これらのグループは、ランダムに割り当てられていませんが、いくつかの他の変数(例えば、年齢や社会経済的地位)が制御されている場合に比較可能とみな
ランダム割り当てに関するよくある質問
実験研究では、ランダム割り当ては、ランダム化を使用してサンプルからの参加者を異なるグループに配置する方法です。 この方法では、サンプルのすべてのメンバーは、対照群または実験群に配置される既知または等しいチャンスを有する。
ランダム選択、または無作為抽出は、研究のサンプルの母集団のメンバーを選択する方法です。
対照的に、無作為割付けはサンプルを対照群と実験群に分類する方法です。
無作為抽出は結果の外部妥当性または一般化可能性を向上させ、無作為割り当ては研究の内部妥当性を向上させます。
ランダム割り当ては、グループ間または独立した測定計画を使用した実験で使用されます。 この研究デザインでは、通常、対照群と1つ以上の実験群があります。 ランダムな割り当ては、グループが比較可能であることを確認するのに役立ちます。
一般に、倫理的に可能であり、研究トピックに適している場合は、このタイプの実験計画では常にランダム割り当てを使用する必要があります。
ランダムな割り当てを実装するには、研究のサンプルのすべてのメンバーに一意の番号を割り当てます。
次に、乱数発生器または宝くじ方法を使用して、各番号を対照群または実験群にランダムに割り当てることができます。 また、コインを反転したり、ランダムにグループに参加者を割り当てるためにサイコロを転がして、手動で行うことができます。
Leave a Reply