컴파일러의 어휘 분석
컴파일러의 어휘 분석은 소스 프로그램 분석의 첫 번째 단계입니다. 어휘 분석은 원본 프로그램의 입력 스트림을 문자별로 읽고 토큰 시퀀스를 생성합니다. 이러한 토큰은 구문 분석을 위해 파서에 대한 입력으로 제공됩니다. 이러한 맥락에서 우리는 어휘 오류 및 복구와 함께 어휘 분석 과정을 간략하게 논의 할 것입니다.
주요 내용: 컴파일러의 어휘 분석
- 어휘 분석의 용어
- 어휘 분석이란 무엇입니까?
- 어휘 분석의 예
- 어휘 분석기의 역할
- 어휘 오류
- 오류 복구
- 주요 테이크 아웃
어휘 분석의 용어
어휘 분석이 어떻게 수행되는지 알아보기 전에 어휘 분석을 논의하면서 접하게 될 몇 가지 용어에 대해 이야기 해 봅시다.
- 어휘
어휘는 패턴을 형성하고 토큰으로 인식 할 수있는 문자 시퀀스로 정의 할 수 있습니다. - 패턴
어휘의 패턴을 식별 한 후 어떤 종류의 토큰이 형성 될 수 있는지 설명 할 수 있습니다. 일부 어휘의 패턴이 키워드를 형성하는 등,일부 어휘의 패턴은 식별자를 형성한다. - 토큰
유효한 패턴을 가진 어휘가 토큰을 형성합니다. 어휘 분석에서 유효한 토큰은 식별자,키워드,구분 기호,특수 문자,상수 및 연산자가 될 수 있습니다.
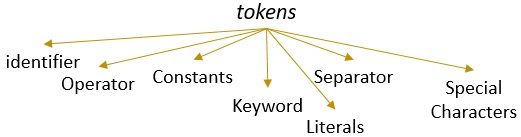
어휘 분석은 무엇입니까?
이전에 우리는 컴퓨터의 콘텐츠 컴파일러에서 어휘 분석기에 대해 사용하지 않았습니다. 우리는 컴파일러가 대상 프로그램으로 변환하기 위해 여러 단계를 통해 소스 프로그램의 분석을 수행하는 것을 배웠다. 어휘 분석은 소스 프로그램이 통과해야하는 첫 번째 단계입니다.
어휘 분석은 토큰 화 과정이다. 그것은 문자로 소스 프로그램 문자의 입력 문자열을 읽고 즉시 어휘의 끝을 식별로,그 패턴을 식별하고 토큰으로 변환합니다.
어휘 분석기는 스캐닝과 어휘 분석을 포함하는 두 개의 연속적인 프로세스로 구성된다.
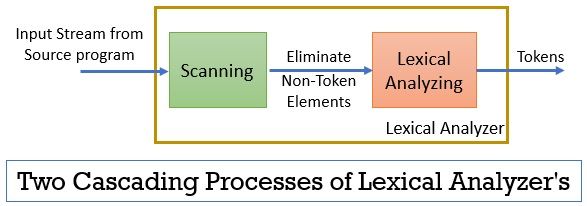
- 스캔:스캔 단계-소스 프로그램에서 토큰이 아닌 요소 만 제거합니다. 주석 제거,연속적인 공백 압축 등과 같은
- 어휘 분석: 어휘 분석 단계는 스캐너가 제공하는 출력에서 토큰화를 수행하여 토큰을 생성합니다.
어휘 분석을 수행하는 데 사용되는 프로그램을 렉서 또는 어휘 분석기라고합니다. 이제 우리가 문에서 수행 어휘 분석의 예를 보자:
어휘 분석의 예 1:
어휘 분석 컴파일러 설계에서 토큰을 식별합니다.
이제 이 문장을 읽을 때 위의 문장에 9 개의 토큰이 있다는 것을 쉽게 식별 할 수 있습니다.
- 식별자->어휘
- 식별자->분석
- 식별자->에서
- 식별자->컴파일러
- 식별자->디자인
- 구분 기호-> ,
- 식별자->식별
- 식별자->토큰
- 구분 기호->.
총과 같이 위의 문자 스트림에 9 개의 토큰이 있습니다.
예제 2 의 어휘 분석:
printf(“값의 나이%d”,i);
지금 우리를 찾으려고 밖으로 토큰의 이 input stream.
- 키워드->인쇄
- 특수 문자-> (
- 이 매개 변수는 다음과 같습니다.-> ,
- 식별자->나는
- 특수 문자-> )
- 구분 기호-> ;
참고:
- 이중 반전 쉼표(예:””)내부의 전체 문자열은 단일 토큰으로 간주됩니다.
- 입력 스트림의 문자를 분리하는 빈 공백은 토큰만 분리하므로 토큰을 세는 동안 제거됩니다.
어휘 분석기의 역할
소스 프로그램 분석의 첫 단계 인 어휘 분석기는 소스 프로그램을 대상 프로그램으로 변환하는 데 중요한 역할을합니다.
이 전체 시나리오는 아래 그림의 도움으로 실현 될 수 있습니다:
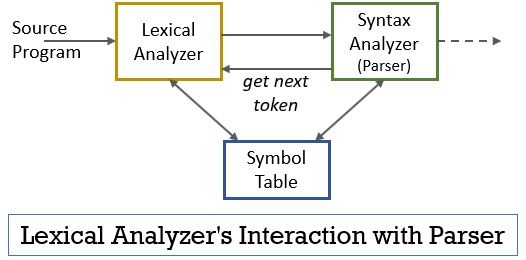
- 어휘 분석기 단계에는 구문 분석기에 의해 그렇게하도록 명령 될 때만 토큰을 생성하는 스캐너 또는 렉서 프로그램이 구현되어 있습니다.어휘 분석기는 토큰으로 인식할 수 있는 어휘를 식별할 때까지 문자별로 입력 스트림을 읽기 시작합니다.
- 토큰이 생성되는대로 어휘 분석기는 구문 분석기에 구문 분석을 위해 보냅니다.
- 구문 분석기와 함께 어휘 분석기는 기호 테이블과 통신합니다. 어휘 분석기는 식별자로 어휘를 식별 할 때 기호 테이블에 해당 어휘를 입력합니다.
- 때로는 기호 테이블의 식별자 정보가 구문 분석기로 전송해야하는 토큰을 결정하는 데 어휘 분석기가 도움이됩니다.
- 입력 스트림에서 토큰을 식별하는 것 외에도 어휘 분석기는 공백/공백 및 프로그램의 주석을 제거합니다. 이러한 다른 것들에는 토큰,탭,공백,새 줄을 구분하는 문자가 포함됩니다.
- 어휘 분석기는 컴파일러에서 생성 된 오류 메시지를 연결하는 데 도움이됩니다. 예를 들어,어휘 분석기는 소스 프로그램을 스캔하는 동안 발생하는 각 새 줄 문자의 레코드를 유지하므로 오류 메시지를 소스 프로그램의 줄 번호와 쉽게 관련시킵니다.
- 소스 프로그램이 매크로를 사용하는 경우 어휘 분석기는 소스 프로그램의 매크로를 확장합니다.
어휘 오류
어휘 분석기 자체가 소스 프로그램의 오류를 확인하는 데 효율적이지 않습니다. 예를 들어,다음과 같은 문을 고려하십시오.
;
이제 위의 문에서 어휘 분석기를 찾을 수 없습니다.
그러나 미리 정의 된 규칙에 따르면 패턴은 식별자 토큰으로 끝나는 유효한 어휘입니다. 즉,문자의 전위로 인해 발생한 오류를 처리하는 파서입니다.
오류 복구
음,어휘 분석기가 어휘의 패턴이 토큰에 대해 미리 정의 된 패턴과 일치하지 않기 때문에 어휘 분석기가 토큰으로 어휘를 식별하는 것도 불가능합니다. 이 경우 일부 오류 복구 전략을 적용해야합니다.
- 패닉 모드 복구에서 어휘 분석기가 유효한 토큰을 식별 할 때까지 어휘에서 연속 문자가 삭제됩니다.
- 나머지 입력에서 첫 번째 문자를 제거합니다.
- 누락 가능한 문자를 식별하고 나머지 입력에 적절하게 삽입하십시오.
- 나머지 입력의 문자를 대체하여 유효한 토큰을 가져옵니다.
- 나머지 입력에서 인접한 두 문자의 위치를 교환합니다.
위의 오류 복구 작업을 수행하는 동안 나머지 입력의 접두사가 토큰 패턴과 일치하는지 확인합니다. 일반적으로 단일 문자로 인해 어휘 오류가 발생합니다. 따라서 단일 변환으로 어휘 오류를 수정할 수 있습니다. 그리고 가능한 한 적은 수의 변환이 소스 프로그램을 파서로 넘겨 줄 수있는 유효한 토큰 시퀀스로 변환해야합니다.
주요 테이크 아웃
- 어휘 분석은 컴파일러에서 소스 프로그램 분석의 첫 번째 단계입니다.
- 어휘 분석기는 두 개의 연속 프로세스 스캐너와 어휘 분석에 의해 구현됩니다.
- 스캐너는 입력 스트림에서 비 토큰 요소를 제거합니다.
- 어휘 분석은 토큰화를 수행합니다.
- 따라서 어휘 분석기는 토큰 시퀀스를 생성하여 파서로 전달합니다.
- 어휘 분석기에서 토큰을 보유하는 파서는 어휘 분석기가 다음 토큰을 식별 할 때까지 문자의 입력 스트림을 읽으라고 주장하는 넥스 토켄을 호출합니다.
- 어휘 분석기가 어휘의 패턴을 식별자로 식별하면 어휘 분석기는 나중에 사용할 수 있도록 해당 어휘를 기호 테이블에 입력합니다.
- 어휘 분석기는 소스 프로그램에서만 오류를 식별하는 데 효율적이지 않습니다.
- 패턴이 사전 정의된 토큰 패턴과 일치하지 않는 어휘가 발생하면 오류 복구 작업을 수행하여 오류를 수정해야 합니다.
그래서,이 모든 토큰에 문자의 스트림을 변환하고 파서에 전달하는 어휘 분석에 관한 것입니다. 우리는 예제의 도움으로 어휘 분석의 작업에 대해 배웠습니다. 우리는 어휘 오류 및 복구 전략에 대한 토론을 마쳤습니다.
Leave a Reply