Datavalidering Og Dataverifisering – Fra Ordbok Til Maskinlæring
Av Aditya Aggarwal, Advanced Analytics Practice Lead, Og Arnab Bose, Chief Scientific Officer, Abzooba
ofte bruker vi dataverifisering og datavalidering om hverandre når vi snakker om datakvalitet. Imidlertid er disse to begrepene forskjellige. I denne artikkelen vil vi forstå forskjellen i 4 forskjellige sammenhenger:
- Ordbok betydning av verifisering og validering
- Forskjell mellom data verifisering og datavalidering generelt
- Forskjell mellom verifisering og validering fra programvareutviklingsperspektiv
- Forskjell mellom data verifisering og datavalidering fra maskinlæringsperspektiv
Ordbok betydning av verifisering og validering
tabell 1 forklarer ordbokens betydning av ordene verifisering og validering med noen få eksempler.

for å oppsummere handler verifisering om sannhet og nøyaktighet, mens validering handler om å støtte styrken til et synspunkt eller korrektheten av et krav. Validering kontrollerer riktigheten av en metodikk mens verifisering kontrollerer nøyaktigheten av resultatene.
Forskjell mellom data verifisering og datavalidering generelt
Nå som vi forstår den bokstavelige betydningen av de to ordene, la oss utforske forskjellen mellom “data verifisering” og “data validering”.
- databekreftelse: for å sikre at dataene er nøyaktige.
- datavalidering: for å sikre at dataene er riktige.
la oss utdype eksempler I Tabell 2.

Forskjell mellom verifisering og validering fra programvareutviklingsperspektiv
fra et programvareutviklingsperspektiv,
- Verifisering er gjort for å sikre at programvaren er av høy kvalitet, godt konstruert, robust og feilfri uten å komme inn i brukervennligheten.
- Validering er gjort for å sikre programvarens brukervennlighet og kapasitet til å oppfylle kundens behov.
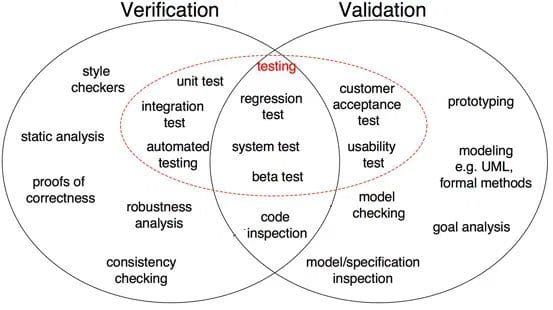
Fig 1: Forskjeller Mellom Verifisering og Validering i programvareutvikling (Kilde)
Som vist I Fig 1, bevis på korrekthet, robusthetsanalyse, enhetstester, integrasjonstest og andre er alle verifikasjonstrinn der oppgaver er orientert for å verifisere detaljer. Programvareutgang er verifisert mot ønsket utgang. På den annen side er modellinspeksjon, svart boks testing, brukbarhetstesting alle valideringstrinn der oppgaver er orientert for å forstå om programvaren oppfyller kravene og forventningene.
Forskjellen mellom dataverifisering og datavalidering fra maskinlæringsperspektiv
rollen som dataverifisering i machine learning pipeline er en gatekeeper. Det sikrer nøyaktige og oppdaterte data over tid. Dataverifisering skjer primært ved det nye datainnsamlingsstadiet, dvs. i trinn 8 I ML-rørledningen, som vist I Fig. 2. Eksempler på dette trinnet er å identifisere dupliserte poster og utføre deduplisering, og å rense mismatch i kundeinformasjon i felt som adresse eller telefonnummer.
på den annen side sikrer datavalidering (i trinn 3 I ML-rørledningen) at inkrementelle data fra trinn 8 som legges til læringsdataene, er av god kvalitet og lignende (fra statistisk egenskapsperspektiv) til eksisterende treningsdata. Dette inkluderer for eksempel å finne dataavvik eller oppdage forskjeller mellom eksisterende treningsdata og nye data som skal legges til treningsdataene. Ellers kan eventuelle datakvalitetsproblemer / statistiske forskjeller i inkrementelle data bli savnet, og treningsfeil kan akkumuleres over tid og forringe modellens nøyaktighet. Dermed oppdager datavalidering betydelige endringer (hvis noen) i inkrementelle treningsdata på et tidlig stadium som hjelper med rotårsaksanalyse.
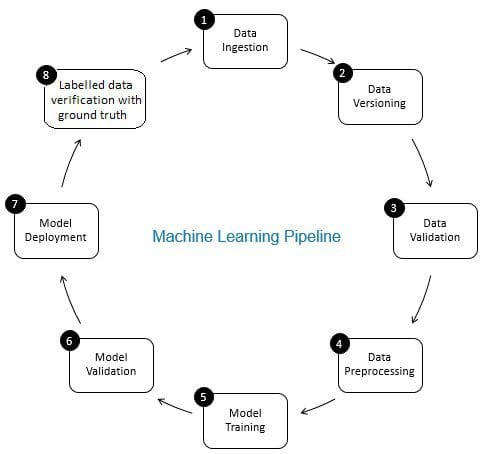
Fig 2: Komponenter Av Maskinlæringsrørledning
Aditya Aggarwal fungerer Som Datavitenskap-Praksis Leder Hos Abzooba Inc. Med mer enn 12 års erfaring i å drive forretningsmål gjennom datadrevne løsninger, spesialiserer Aditya seg på prediktiv analyse, maskinlæring, forretningsintelligens & forretningsstrategi på tvers av en rekke bransjer.
Dr. Arnab Bose er Chief Scientific Officer hos Abzooba, et dataanalyseselskap og et adjungerende fakultet ved University Of Chicago hvor han underviser I Maskinlæring og Prediktiv Analyse, Maskinlæringsoperasjoner, Tidsserieanalyse og Prognoser og Helseanalyse i Master of Science In Analytics-programmet. Han er en 20-årig prediktiv analyseindustri veteran som liker å bruke ustrukturerte og strukturerte data for å prognose og påvirke atferdsmessige utfall i helsevesen, detaljhandel, finans og transport. Hans nåværende fokusområder inkluderer stratifisering av helserisiko og kronisk sykdomsstyring ved hjelp av maskinlæring, og produksjonsdistribusjon og overvåking av maskinlæringsmodeller.
Relatert:
- MLOps – ” Hvorfor er Det nødvendig ?”og” Hva er det”?
- min maskinlæringsmodell lærer ikke. Hva skal jeg gjøre?
- Data Observerbarhet, Del II: Hvordan Bygge Dine Egne Datakvalitetsmonitorer Ved HJELP AV SQL
Leave a Reply