How I Write My Data Analysis Blogs by Kathleen E. ’23
Min kjære venn Og kollega blogger Kidist A. ’22 ba om at jeg skrev et innlegg for å beskrive hvordan jeg går om å skrive mine dataanalyseblogger. Så, her går! Jeg har skissert mine generelle trinn og knyttet til mine gamle innlegg for å gi eksempler på hva jeg snakker om.
Identifiser et spørsmål

jeg begynner med å spørre meg selv følgende:
- Hvilken historie vil jeg fortelle?
- hvordan hjelper dataanalyse å fortelle den historien?
hvis jeg sitter fast, prøver jeg å tenke på livet mitt og verden rundt meg. Er det noen mønstre jeg vil undersøke eller fenomener jeg vil kvantifisere?
her er noen ting jeg har spurt meg selv tidligere:
- Hvordan ser arbeidsmønstrene mine ut? Forvirring, Med Tallene
- Hvordan er det å klatre en 20-etasjers bygning 22 ganger? Green Building Challenge
- Hvordan FØLER mit-studenter om våre sovesalers nye vaskerom? Washlava! En Sentimentanalyse
Deretter spør jeg meg selv hva slags data som vil være nyttig for å svare på spørsmålet ditt. Dette bringer oss til neste trinn:
Samle noen data
Samle data kan være grei eller ganske kjedelig. Dataene kan eksistere allerede, pent kompilert i en database. Hvis databasen er offentlig, er jeg ferdig med dette trinnet! Hvis det er privat, sender jeg vanligvis en forespørsel til eieren om å bruke den. Hvis dataene er inne I En app Som Facebook, ser jeg etter måter som jeg kan be om en data nedlasting. Dataene kan også eksistere et sted litt mer ubeleilig (spredt rundt på nettet, for eksempel), og jeg må samle den.
hvis dataene ikke eksisterer ennå, kan jeg begynne å lage den. Hvis spørsmålet jeg prøver å svare på er mer personlig, kan jeg begynne å spore noe i livet mitt, enten automatisk (som med et trinntellingsklokke) eller manuelt (som å registrere Hva Netflix viser jeg ser hver natt). Eller, hvis dataene handler om andre mennesker, kan jeg utføre et eksperiment eller sende ut en undersøkelse.
Her er et flytskjema jeg laget som oppsummerer hvordan jeg kan gå om å få data:
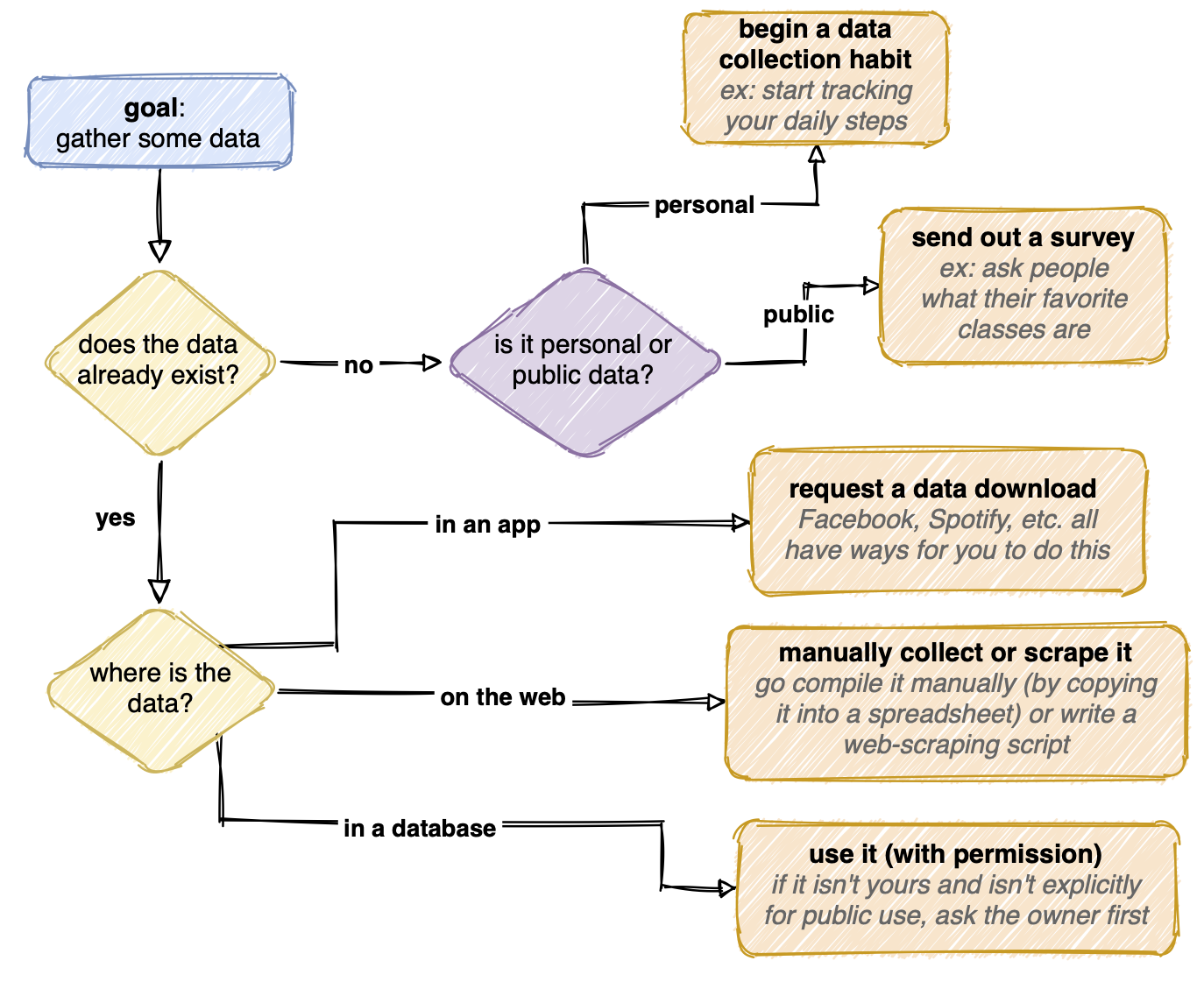
Rengjør dataene

dataene kommer sjelden klar til å analysere. For å få det klart, må jeg “rense” det.
hva betyr det at dataene ikke er klare til å analysere? Kanskje det er mye data som ikke er relatert til spørsmålet mitt. Kanskje dataene er representert på en veldig uorganisert eller inkonsekvent måte. Rengjøring kan bety å trekke ut den relevante delmengden av dataene, organisere den og endre hvordan den representeres for å gjøre en enklere analyse.
for eksempel i dormspam-the-game (Del 1) bestod dataene av en liste over steder hvor hver spiller (i et virtuelt spill av gjemsel) valgte å gjemme seg. Det var imidlertid noen oppføringer i databasen som ble feilstavet, noe som forårsaket feil i koden min da den prøvde å iterere over en liste over steder. Jeg måtte gå erstatte disse oppføringene med riktig stavet versjoner av plasseringen.
Gjør noen dataanalyse!
Jeg bruker Vanligvis Python til å skrive skript for å analysere og visualisere dataene mine. Jeg har satt noen av koden min offentlig på Github, så du kan ta en titt på den. Python er imidlertid ikke det eneste alternativet. Du kan også bruke en rekke andre skriptspråk som har gode analyse – og visualiseringsverktøy. Du kan også gå uten kode og bruke regnearkfunksjoner. Med det sagt, her er hvordan jeg jobber Med Python:
- Jeg liker Å bruke Jupyter Notatbøker (Eller Google Colab notatbøker). Jeg liker disse bedre enn en rå tekstfil fordi de tillater markdown notater/dokumentasjon og visualiseringer å eksistere sammen med koden din ganske pent. Hvis jeg planlegger analysene mine, lærer å bruke et nytt verktøy eller refererer til et tidligere resultat, er det fint at jeg bare kan bla rundt for å se på notater/utdata/tomter i min notatbok i stedet for noen ekstern referanse.
- jeg stoler tungt på pakker. Jeg importerer Nesten Alltid Pandaer, Numpy og Matplotlib for å håndtere og organisere dataene mine, gjøre grunnleggende statistiske og matematiske operasjoner, og lage grunnleggende visualiseringer, henholdsvis. På prosjekt-for-prosjekt basis importerer jeg også flere pakker for å få tilgang til spesielle modeller og visualiseringer som kan være relevante.
- jeg starter med å laste opp dataene mine. Jeg kan laste den lokalt fra en fil på datamaskinen min. Eller, oftere, det jeg gjør er å laste Det opp Til Google Regneark, bruk” publiser på nettet ” – funksjonen for å generere en kobling TIL EN CSV, og bruk deretter den lenken til å laste inn dataene mine. Jeg foretrekker å bruke google-ark over en lokal fil fordi den har bedre versjonshistorikk og samarbeidsfunksjoner.
- Deretter engasjerer Jeg meg I en iterativ prosess der jeg hypoteser om en trend i dataene, gjør en analyse for å undersøke hypotesen, og deretter bruke resultatene til å generere flere hypoteser. Med virkelig interessant eller merkelig data, denne prosessen kan gå på en god stund.
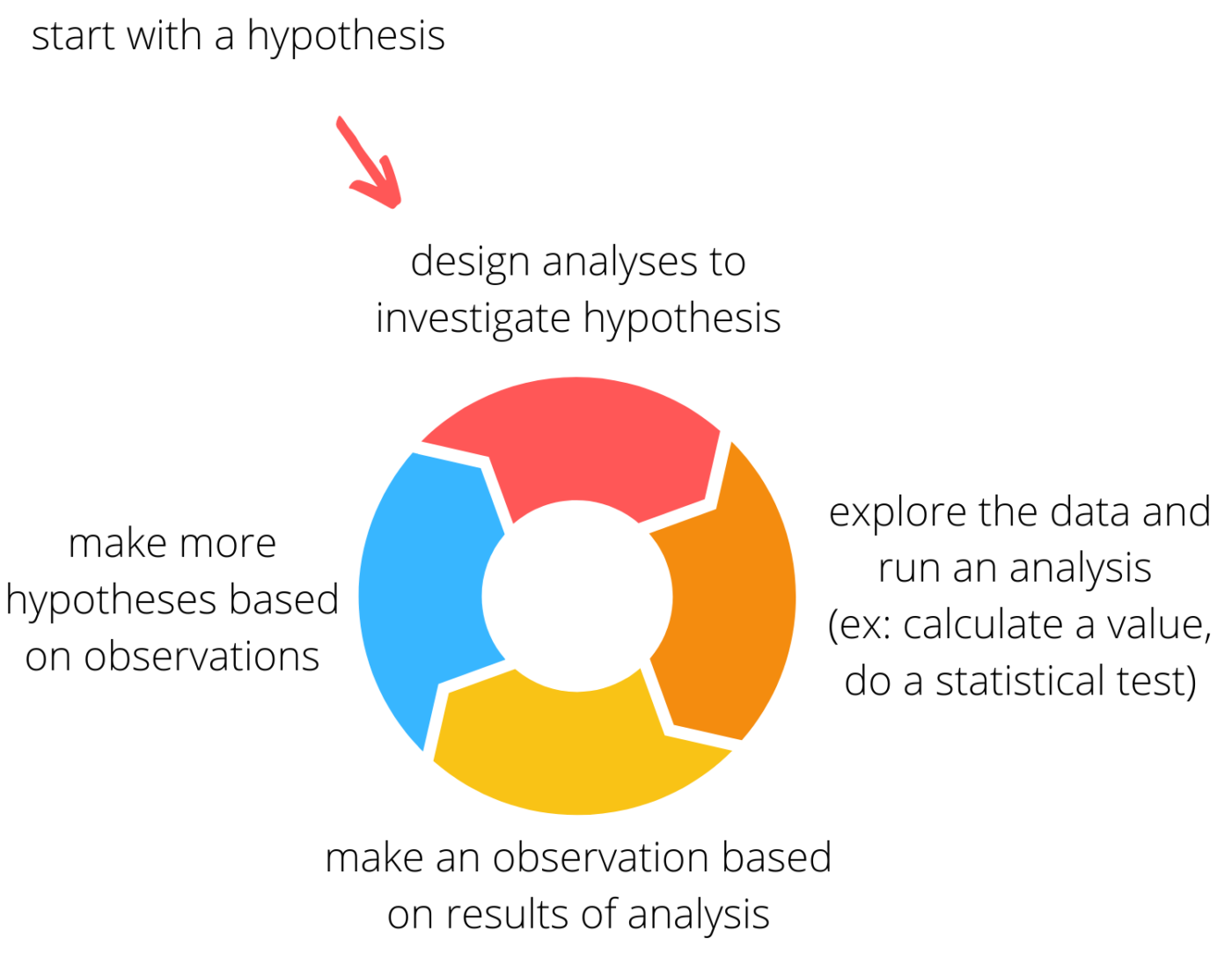
Lag noen tomter
når jeg analyserer dataene, er en nyttig måte å oppdage kule mønstre på å lage visualiseringer. Jeg kan gjøre dette med en rekke grafer. Min første tomten er ofte ganske stygg. Jeg kan bruke ulike funksjoner i mitt plottebibliotek for å gjøre det bedre å markere dataene, både vitenskapelig og estetisk. For eksempel kan jeg justere farger og dimensjonering av datapunkter, linjer og stolper for å bedre demonstrere trender. Jeg kan endre måten x-og y-aksen er representert for å gjøre plottet ser renere ut.
Bortsett fra å lage statiske tomter, liker jeg noen ganger å animere tomter (se Green Building Challenge og dormspam-the-game (Del 1)). Å lage tomter er en kreativ prosess, spesielt når du lager animerte, hvor funksjoner som farge og størrelse kan tjene et annet formål enn de kan i et statisk plott.
Å lage visualiseringer er min favoritt del av prosessen. Jeg elsker å la mine kunstneriske og tekniske sider komme sammen.
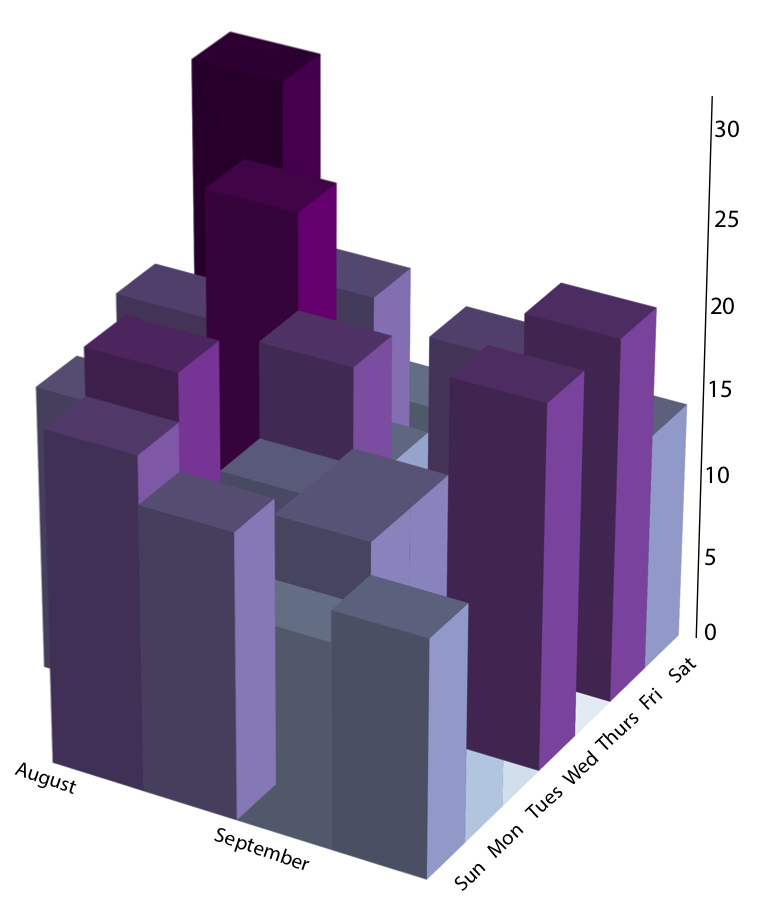
et plott fra mitt første blogginnlegg som viser antall skritt jeg tok, i tusenvis, i de første ukene PÅ MIT
Fortell en historie
Det er viktig å tenke på hvordan dataanalysen og visualiseringene mine kan bidra til å fortelle en historie om trenden jeg undersøker eller fenomenet jeg kvantifiserer. Jeg prøver å lage plott på en måte som gjør at hvert plott kan vise en ny del av historien. Jeg prøver å bestille dem mine tomter mine innlegg på en måte som hver mine ord og mine tomter sammen gradvis fortelle en historie om hva som skjer. For eksempel, når jeg har visualisert dataene fra et spill, kan jeg først beskrive spillets regler, deretter beskrive hvem som vant, og deretter dykke inn i å forstå hvordan forskjellige spillerstrategier påvirket utfallet.
Så det er ganske mye hvordan jeg går om å skrive mine dataanalyseblogger. Jeg separerte det i 6 trinn, men å tenke “bakover” i stedet for strengt trinnvis, kan bidra til å gjøre arbeidet ditt i tidligere trinn mer meningsfylt. Hvis du tenker på hvordan du gjør historien overbevisende, kan du gjøre bedre visualiseringer. Hvis du vet hvilke visualiseringer du kanskje vil gjøre, kan du bedre rette datainnsamlingen din.
Leave a Reply