Leksikalsk Analyse I Kompilatoren
Leksikalsk Analyse i kompilatoren er det første trinnet i analysen av kildeprogrammet. Den leksikalske analysen leser inngangsstrømmen fra kildeprogrammet karakter for tegn og produserer sekvensen av tokens. Disse tokens er gitt som en inngang til parseren for parsing. I denne sammenheng vil vi diskutere prosessen med leksikalsk analyse i korte trekk sammen med leksikalske feil og deres utvinning.
Innhold: Lexisk Analyse I Kompilatoren
- Terminologier I Leksikalsk Analyse
- Hva Er Leksikalsk Analyse?
- Eksempler På Leksikalsk Analyse
- Rolle Leksikalsk Analysator
- Lexical Error
- Error Recovery
- Key Takeaways
Terminologier I Leksikalsk Analyse
før du får inn hva leksikalsk analyse er hvordan det utføres la oss snakke om noen terminologier som er vi vil komme over mens du diskuterer leksikalsk analyse.
- Lexeme
Lexeme kan defineres som en sekvens av tegn som danner et mønster og kan gjenkjennes som et token. - Mønster
etter å identifisere mønsteret av lexeme kan man beskrive hva slags token kan dannes. Slik som mønsteret til noen lexeme danner et søkeord, danner mønsteret til noen lexemer en identifikator. - Token
et lexeme med et gyldig mønster danner et token. I leksikalsk analyse kan et gyldig token være identifikatorer, søkeord, separatorer, spesialtegn, konstanter og operatører.
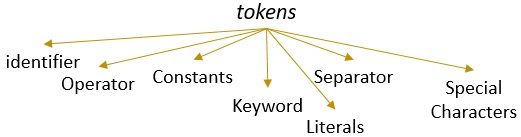
Hva Er Leksikalsk Analyse?
Tidligere har vi nedlagt om lexical analyzer i vår innhold kompilatoren i datamaskinen. Vi har lært at kompilatoren utfører analysen av kildeprogrammet gjennom ulike faser for å forvandle det til målprogrammet. Den leksikalske analysen er den første fasen som kildeprogrammet må gå gjennom.
den leksikalske analysen er prosessen med å tokenisere dvs. den leser inngangsstrengen til et kildeprogram tegn for tegn, og så snart det identifiserer en ende av lexemet, identifiserer det mønsteret og konverterer det til et token.
den leksikalske analysatoren består av to påfølgende prosesser som inkluderer skanning og leksikalsk analyse.
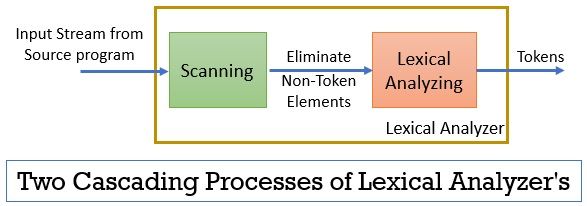
- Skanning: skannefasen-eliminerer bare ikke-token-elementene fra kildeprogrammet. Slik som å eliminere kommentarer, komprimere de påfølgende hvite mellomrom etc.
- Leksikalsk Analyse: Lexisk analysefase utfører tokeniseringen på utgangen fra skanneren og produserer dermed tokens.
programmet som brukes til å utføre leksikalsk analyse, refereres til som lexer eller lexical analyzer. La oss nå ta et eksempel på leksikalsk analyse utført på en uttalelse:
Eksempel 1 Av Leksikalsk Analyse:
Leksikalsk analyse i kompilatordesign, identifiser tokens.
Nå, når vi skal lese denne uttalelsen, kan vi enkelt identifisere at det er ni tokens i ovennevnte uttalelse.
- Identifikatorer -> leksikalske
- Identifikatorer -> analyse
- Identifikatorer -> I
- Identifikatorer -> kompilator
- Identifikatorer -> design
- separator -> ,
- Identifikatorer -> identifiser
- Identifikatorer- > tokens
- Separator – > .
slik som totalt er det 9 tokens i den ovennevnte strømmen av tegn.
Eksempel 2 Av Leksikalsk Analyse:
printf(” verdien av i er %d “, i);
La Oss nå prøve å finne tokens ut av denne inngangsstrømmen.
- Nøkkelord -> printf
- Spesialtegn -> (
- Literal – > ” Verdien av i er % d “
- Separator -> ,
- Identifikator – > I
- Spesialtegn -> )
- Separator -> ;
Merk:
- hele strengen inne i de doble inverterte kommaene, dvs. “” betraktes som et enkelt token.
- det tomme hvite rommet som skiller tegnene i inngangsstrømmen, skiller bare tokens og dermed elimineres det mens du teller tokens.
Rolle Leksikalsk Analysator
å være den første fasen i analysen av kildeprogrammet den leksikalske analysatoren spiller en viktig rolle i transformasjonen av kildeprogrammet til målprogrammet.
Hele dette scenariet kan realiseres ved hjelp av figuren nedenfor:
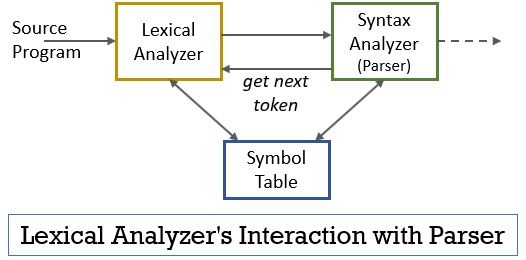
- den leksikalske analysatorfasen har skanneren eller lexer-programmet implementert i den som bare produserer tokens når de blir befalt av parseren for å gjøre det.
- parseren genererer kommandoen getNextToken og sender den til den leksikalske analysatoren som et svar på dette.
- så snart et token er produsert, sender den leksikalske analysatoren den til syntax analyzer for parsing.
- sammen med syntax analyzer kommuniserer den leksikalske analysatoren også med symboltabellen. Når en leksikalsk analysator identifiserer et lexeme som en identifikator, går det inn i det lexemet i symboltabellen.
- noen ganger hjelper informasjonen til identifikator i symboltabellen lexical analyzer til å bestemme token som må sendes til parseren.
- Bortsett fra å identifisere tokens i inngangsstrømmen, eliminerer den leksikalske analysatoren også tomrommet/hvitt mellomrom og kommentarene til programmet. Slike andre ting inkluderer tegn som skiller tokens, faner, tomme mellomrom, nye linjer.
- den leksikalske analysatoren hjelper til med å relatere feilmeldingene produsert av kompilatoren. Bare for eksempel holder den leksikalske analysatoren oversikten over hvert nytt linjetegn det kommer over mens du skanner kildeprogrammet, slik at det enkelt relaterer feilmeldingen med linjenummeret til kildeprogrammet.
- hvis kildeprogrammet bruker makroer, utvider den leksikalske analysatoren makroene i kildeprogrammet.
Leksikalsk Feil
den leksikalske analysatoren selv er ikke effektiv for å bestemme feilen fra kildeprogrammet. Tenk for eksempel på en setning:
prtf (“verdien av i er %d”, i) ;
nå, i ovennevnte setning når strengen prtf oppstår, kan den leksikalske analysatoren ikke gjette om prtf er en feil stavemåte av søkeordet ‘printf’ eller det er en svart funksjonsidentifikator.
men i henhold til den forhåndsdefinerte regelen er prtf et gyldig lexeme hvis mønster konkluderer med at det er et identifikasjonstoken. Nå vil den leksikalske analysatoren sende prtf-token til neste fase, dvs. parser som skal håndtere feilen som oppstod på grunn av transponering av bokstaver.
Feilgjenoppretting
vel, noen ganger er det enda umulig for en leksikalsk analysator å identifisere et lexeme som et token, da lexemets mønster ikke samsvarer med noen av de forhåndsdefinerte mønstrene for tokens. I dette tilfellet må vi bruke noen feilgjenopprettingsstrategier.
- i gjenoppretting av panikkmodus slettes det påfølgende tegnet fra lexemet til lexical analyzer identifiserer et gyldig token.
- Fjern det første tegnet fra den gjenværende inngangen.
- Identifiser det mulige manglende tegnet og sett det inn i den gjenværende inngangen på riktig måte.
- Erstatt et tegn i den gjenværende inngangen for å få et gyldig token.
- Bytt posisjonen til to tilstøtende tegn i den gjenværende inngangen.
kontroller om prefikset for gjenværende inngang samsvarer med et mønster av tokens når du utfører de ovennevnte feilgjenopprettingshandlingene. Vanligvis oppstår en leksikalsk feil på grunn av et enkelt tegn. Så, du kan rette den leksikalske feilen med en enkelt transformasjon. Og så langt som mulig må et mindre antall transformasjoner konvertere kildeprogrammet til en sekvens av gyldige tokens som den kan overlevere til parseren.
Key Takeaways
- Leksikalsk analyse er første fase i analysen av kildeprogrammet i kompilatoren.
- den leksikalske analysatoren er implementert av to påfølgende prosesser skanner og leksikalsk analyse.
- Skanner eliminerer ikke-token-elementene fra inngangsstrømmen.
- Leksikalsk analyse utfører tokenisering.
- således genererer den leksikalske analysatoren en sekvens av tokens og videresender dem til parseren.
- parseren på å ha et token fra den leksikalske analysatoren gjør et kall getNextToken som insisterer på at den leksikalske analysatoren leser inntastingsstrømmen av tegn til den identifiserer neste token.
- hvis den leksikalske analysatoren identifiserer mønsteret til et lexeme som en identifikator, går den leksikalske analysatoren inn i det lexeme i symboltabellen for fremtidig bruk.
- Lexical analyzer er ikke effektiv til å identifisere noen feil i kildeprogrammet alene.
- hvis det oppstår et lexeme hvis mønster ikke samsvarer med noen av de forhåndsdefinerte mønstrene av tokens, må du utføre feilgjenopprettingshandlinger for å fikse feilen.
Så handler dette om leksikalsk analyse som forvandler strømmen av tegn til tokens og sender den til parseren. Vi har lært om arbeidet med leksikalsk analyse ved hjelp av et eksempel. Vi har avsluttet diskusjonen med den leksikalske feilen og dens gjenopprettingsstrategi.
Leave a Reply