Data Validation and data Verification-From Dictionary to Machine Learning
door Aditya Aggarwal, Advanced Analytics Practice Lead, en Arnab Bose, Chief Scientific Officer, Abzooba
heel vaak gebruiken we data verificatie en data validation door elkaar als we het hebben over data quality. Deze twee termen zijn echter verschillend. In dit artikel zullen we het verschil in 4 verschillende contexten begrijpen:
- Woordenboek betekenis van verificatie en validatie
- Verschil tussen data verificatie en validatie van gegevens in het algemeen
- Verschil tussen verificatie en validatie van software ontwikkeling
- Verschil tussen data verificatie en validatie van gegevens van machine learning perspectief
Woordenboek betekenis van verificatie en validatie
Tabel 1 woordenboek verklaart de betekenis van de woorden, verificatie en validatie met een paar voorbeelden.

om samen te vatten, verificatie gaat over waarheid en nauwkeurigheid, terwijl validatie gaat over het ondersteunen van de kracht van een standpunt of de juistheid van een claim. Validatie controleert de juistheid van een methodologie terwijl verificatie de nauwkeurigheid van de resultaten controleert.
verschil tussen verificatie van gegevens en validatie van gegevens in het algemeen
nu we de letterlijke betekenis van de twee woorden begrijpen, gaan we het verschil onderzoeken tussen “verificatie van gegevens” en “validatie van gegevens”.
- verificatie van de gegevens: om ervoor te zorgen dat de gegevens juist zijn.
- gegevensvalidatie: om ervoor te zorgen dat de gegevens correct zijn.
laten we verder gaan met voorbeelden in Tabel 2.

verschil tussen verificatie en validatie vanuit softwareontwikkelingsperspectief
vanuit softwareontwikkelingsperspectief,
- verificatie wordt gedaan om ervoor te zorgen dat de software van hoge kwaliteit, goed ontworpen, robuust en foutloos is zonder in de bruikbaarheid te komen.
- validatie wordt uitgevoerd om de bruikbaarheid van software en de capaciteit om aan de behoeften van de klant te voldoen te garanderen.
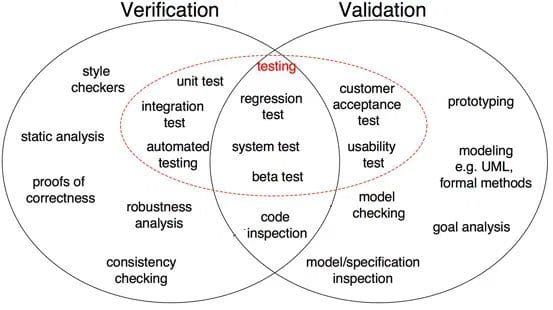
Figuur 1: Verschillen tussen verificatie en validatie in softwareontwikkeling (bron)
zoals weergegeven in Fig 1, bewijs van juistheid, robuustheid analyse, unit tests, integratie test en anderen zijn alle verificatiestappen waarbij taken zijn gericht op het verifiëren van details. Software-uitvoer wordt geverifieerd aan de hand van de gewenste uitvoer. Aan de andere kant zijn modelinspectie, black box testing, usability testing allemaal validatiestappen waarbij taken gericht zijn om te begrijpen of software voldoet aan de eisen en verwachtingen.
verschil tussen gegevensverificatie en gegevensvalidatie vanuit machine learning perspectief
de rol van gegevensverificatie in machine learning pijplijn is die van een gatekeeper. Het zorgt voor nauwkeurige en bijgewerkte gegevens in de tijd. De verificatie van de gegevens vindt voornamelijk plaats in de nieuwe fase van de gegevensverzameling, d.w.z. in Stap 8 van de ML-pijpleiding, zoals in Fig. 2. Voorbeelden van deze stap zijn het identificeren van dubbele records en het uitvoeren van deduplicatie, en het reinigen van mismatch in klantinformatie in het veld zoals adres of telefoonnummer.
anderzijds zorgt gegevensvalidatie (in Stap 3 van de ML-pijplijn) ervoor dat de incrementele gegevens uit stap 8 die aan de leergegevens worden toegevoegd, van goede kwaliteit zijn en vergelijkbaar (vanuit statistisch eigenschappenperspectief) met de bestaande trainingsgegevens. Dit omvat bijvoorbeeld het vinden van gegevensafwijkingen of het opsporen van verschillen tussen bestaande trainingsgegevens en nieuwe gegevens die aan de trainingsgegevens moeten worden toegevoegd. Anders kunnen problemen met de gegevenskwaliteit/statistische verschillen in incrementele gegevens worden gemist en kunnen trainingsfouten zich na verloop van tijd ophopen en de nauwkeurigheid van het model verslechteren. Zo detecteert data validation significante veranderingen (indien van toepassing) in incrementele trainingsgegevens in een vroeg stadium die helpt bij de analyse van de onderliggende oorzaak.
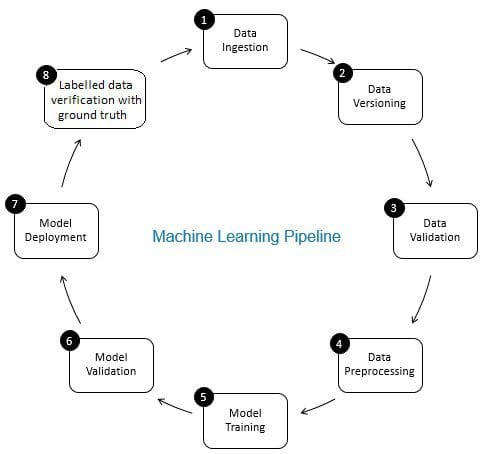
Fig 2: componenten van Machine Learning Pipeline
Aditya Aggarwal fungeert als Data Science-Practice Lead bij Abzooba Inc. Met meer dan 12 jaar ervaring in het sturen van bedrijfsdoelstellingen door middel van data-gedreven oplossingen, is Aditya gespecialiseerd in predictive analytics, machine learning, business intelligence & bedrijfsstrategie in een reeks industrieën.
Dr. Arnab Bose is Chief Scientific Officer bij Abzooba, een data analytics bedrijf en een adjunct faculteit aan de Universiteit van Chicago, waar hij doceert Machine Learning en Predictive Analytics, Machine Learning Operations, Time Series analyse en Forecasting, en Health Analytics in de Master of Science in Analytics programma. Hij is een 20-jarige predictive analytics industrie veteraan die geniet van het gebruik van ongestructureerde en gestructureerde gegevens te voorspellen en te beïnvloeden gedragsresultaten in de gezondheidszorg, retail, financiën, en transport. Zijn huidige aandachtsgebieden zijn onder andere gezondheidsrisico ‘ s stratificatie en chronische ziekte management met behulp van machine learning, en productie implementatie en monitoring van machine learning modellen.
gerelateerd:
- MLOps – ” Waarom is het nodig?”en” wat het is”?
- mijn machine learning model leert niet. Wat moet ik doen?
- data Observability, Part II: How To Build Your Own Data Quality Monitors Using SQL
Leave a Reply