How I Write My Data Analysis Blogs by Kathleen E. ’23
mijn beste vriend en collega blogger Kidist A.’ 22 verzocht mij een bericht te schrijven om te beschrijven hoe ik mijn data analysis blogs schrijf. Dus, daar gaat ie! Ik heb mijn algemene stappen geschetst en gekoppeld aan mijn oude berichten om voorbeelden te geven van waar ik het over heb.
Identificeer een vraag

:
- welk verhaal wil ik vertellen?
- Hoe helpt data-analyse dat verhaal te vertellen?
als ik vastzit, probeer ik na te denken over mijn leven en de wereld om me heen. Zijn er patronen die ik wil onderzoeken of fenomenen die ik wil kwantificeren?
hier zijn enkele dingen die ik mezelf in het verleden heb afgevraagd:
- Hoe zien mijn werkpatronen eruit? Verwarring, met de getallen
- Hoe is het om 22 keer een gebouw van 20 verdiepingen te beklimmen? Green Building Challenge
- hoe voelen MIT-studenten zich over het nieuwe wassysteem van onze slaapzalen? Washlava! A Sentiment Analysis
vervolgens vraag ik me af wat voor soort gegevens nuttig zijn om uw vraag te beantwoorden. Dit brengt ons bij de volgende stap:
verzamel wat gegevens
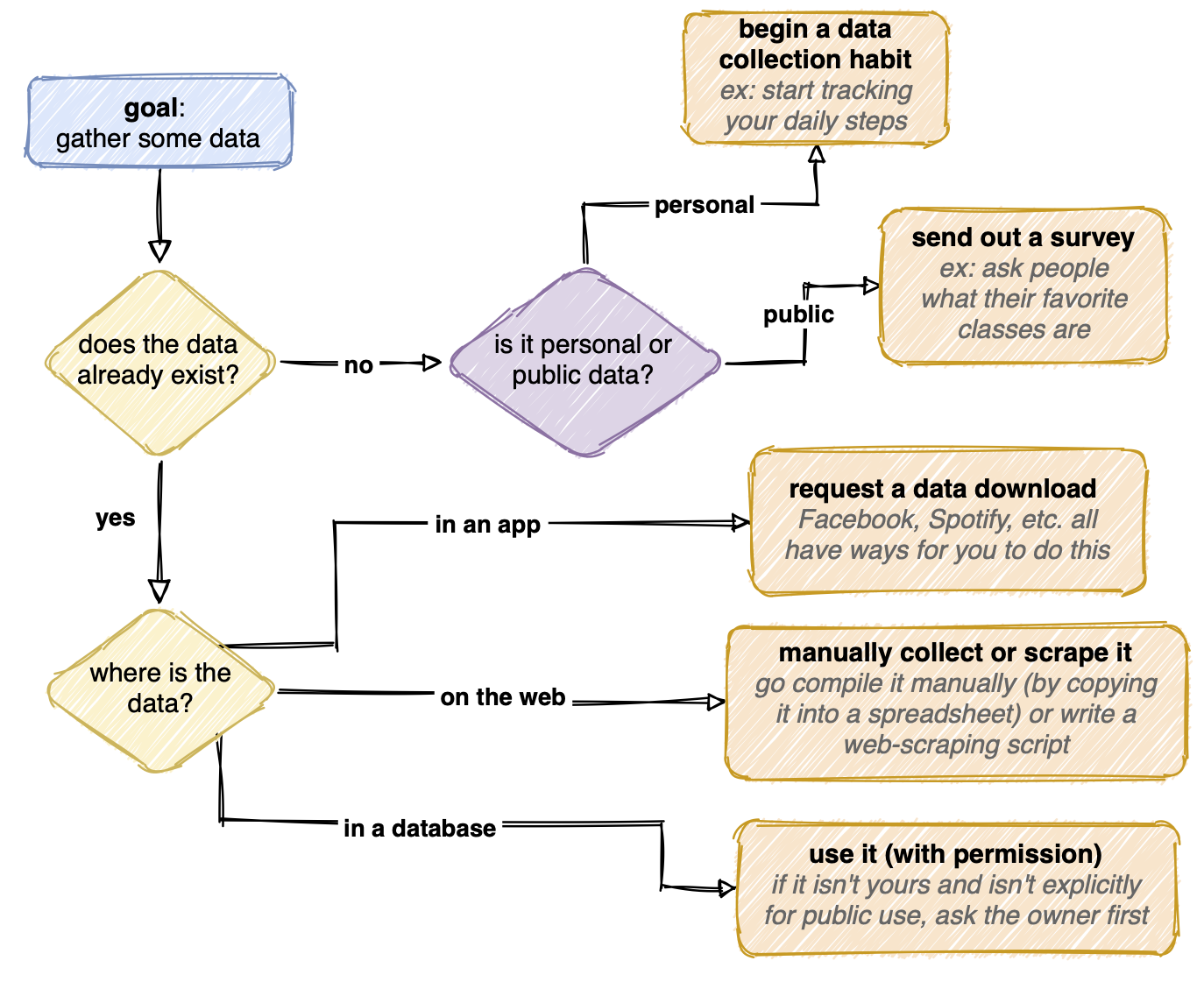
het verzamelen van gegevens kan eenvoudig of heel vervelend zijn. De gegevens kunnen al bestaan, netjes gecompileerd in een database. Als de database openbaar is, ben ik klaar met deze stap! Als het privé is, stuur ik meestal een verzoek naar de eigenaar om het te gebruiken. Als de gegevens zich in een app zoals Facebook bevinden, zoek ik naar manieren waarop ik een gegevensdownload kan aanvragen. De gegevens kunnen ook ergens een beetje meer onhandig bestaan (verspreid over het web, bijvoorbeeld) en ik zou moeten gaan verzamelen.
als de gegevens nog niet bestaan, kan ik beginnen met het aanmaken. Als de vraag die ik probeer te beantwoorden is persoonlijker, ik kan beginnen met het bijhouden van iets in mijn leven, hetzij automatisch (zoals met een stap-tellen horloge) of handmatig (zoals het opnemen van wat Netflix toont ik kijk elke nacht). Of, als de gegevens over andere mensen gaan, kan ik een experiment uitvoeren of een enquête sturen.
hier is een stroomdiagram dat ik heb gemaakt dat een samenvatting geeft van hoe ik zou kunnen gaan over het verkrijgen van gegevens:
gegevens opschonen

de gegevens kunnen zelden worden geanalyseerd. Om het klaar te krijgen, moet ik het “schoonmaken”.
wat betekent het dat de gegevens niet klaar zijn om te analyseren? Misschien zijn er veel gegevens die niets met mijn vraag te maken hebben. Misschien worden de gegevens op een ongeorganiseerde of inconsistente manier weergegeven. Opschonen kan betekenen dat de relevante subset van de gegevens wordt uitgepakt, wordt georganiseerd en hoe het wordt weergegeven, wordt gewijzigd om een meer eenvoudige analyse te maken.
bijvoorbeeld, in dormspam-the-game (Deel 1) bestonden de gegevens uit een lijst van locaties waar elke speler (in een virtueel spel van verstoppertje) ervoor koos zich te verbergen en te zoeken. Echter, er waren een aantal vermeldingen in de database die verkeerd waren gespeld, waardoor fouten in mijn code als het probeerde te herhalen over een lijst van locaties. Ik moest die items vervangen door correct gespelde versies van de locatie.
doe wat gegevensanalyse!
Ik gebruik Python over het algemeen om scripts te schrijven om mijn gegevens te analyseren en te visualiseren. Ik heb wat van mijn code publiekelijk op Github gezet, zodat je er naar kunt kijken. Echter, Python is niet de enige optie. U kunt ook een verscheidenheid aan andere scripttalen gebruiken die geweldige analyse-en visualisatietools hebben. U kunt ook gaan no-code en gebruik maken van spreadsheet functies. Dat gezegd hebbende, zo werk ik met Python:
- Ik gebruik graag Jupyter Notebooks (of Google Colab notebooks). Ik vind deze beter dan een RAW-tekstbestand omdat ze zorgen voor markdown notities/documentatie en visualisaties om te bestaan naast uw code heel mooi. Als ik van plan ben mijn analyses, leren om een nieuwe tool te gebruiken, of verwijzen naar een verleden resultaat, het is leuk dat ik kan gewoon rond scrollen om te kijken naar notities/output/plots in mijn notebook in plaats van een externe referentie.
- ik ben sterk afhankelijk van pakketten. Ik importeer bijna altijd Panda ‘ s, Numpy en Matplotlib voor het verwerken en organiseren van mijn gegevens, het doen van elementaire statistische en wiskundige bewerkingen, en het maken van fundamentele visualisaties, respectievelijk. Op project-per-project basis importeer ik ook extra pakketten om toegang te krijgen tot speciale modellen en visualisaties die relevant kunnen zijn.
- ik begin met het laden van mijn gegevens. Ik kan het lokaal laden vanuit een bestand op mijn computer. Of, vaker, wat ik doe is het uploaden naar Google Spreadsheets, gebruik maken van de” publiceren op het web ” functie om een link naar een CSV te genereren, en gebruik die link om mijn gegevens te laden. Ik gebruik liever google Spreadsheets dan een lokaal bestand omdat het een mooiere versie geschiedenis en samenwerkingsfuncties heeft.
- vervolgens doe ik een iteratief proces waarbij ik een hypothese maak over een trend in de gegevens, een analyse doe om de hypothese te onderzoeken en vervolgens de resultaten gebruik om meer hypothesen te genereren. Met echt interessante of vreemde gegevens, kan dit proces gaan voor een tijdje.
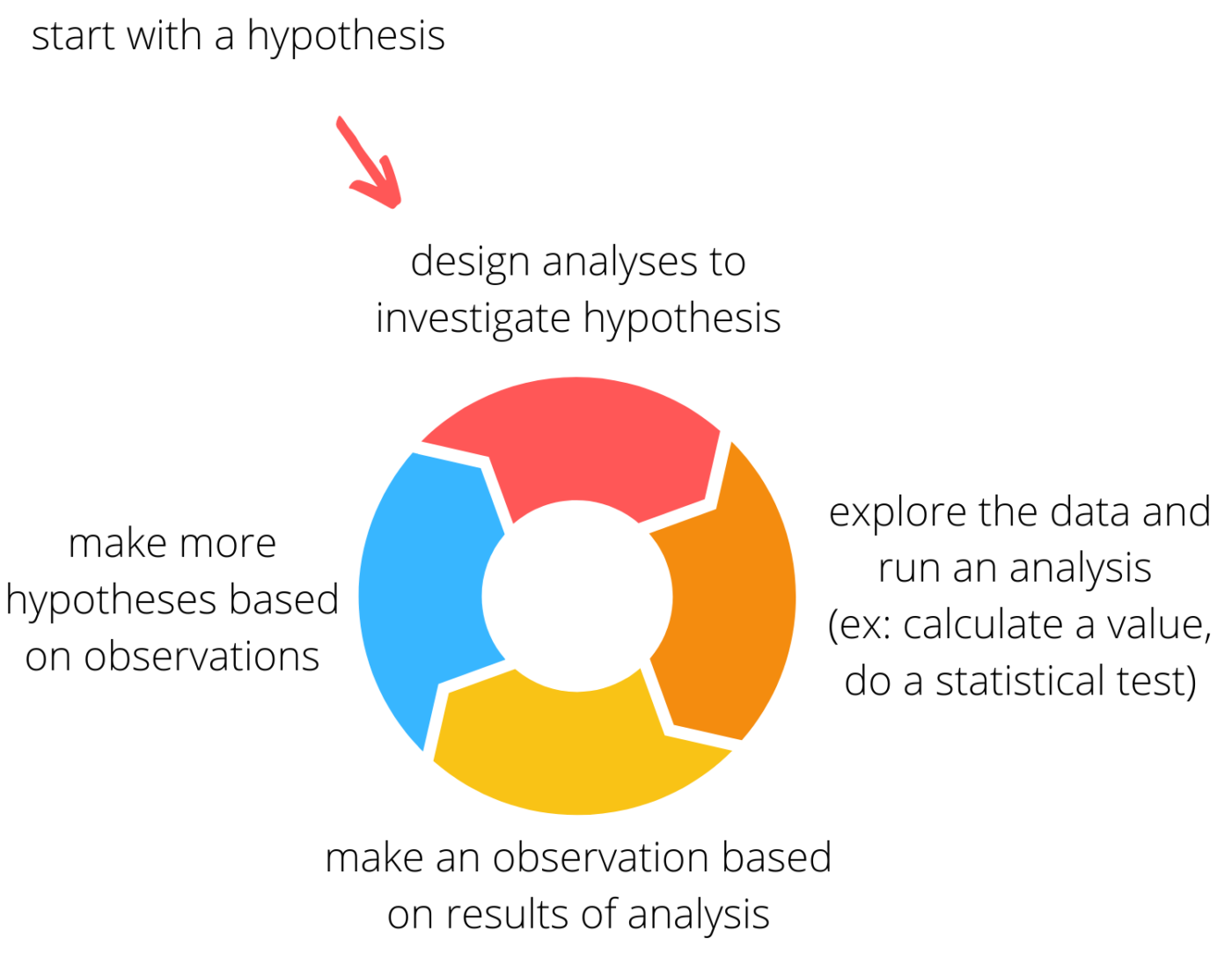
Maak enkele plots
terwijl ik de gegevens analyseer, is een nuttige manier om koele patronen te herkennen door visualisaties te maken. Ik kan dit doen met een verscheidenheid aan grafieken. Mijn eerste plot is vaak behoorlijk lelijk. Ik kan verschillende functies in mijn plotten bibliotheek gebruiken om het beter de gegevens te markeren, zowel wetenschappelijk als esthetisch. Ik kan bijvoorbeeld de kleuren en afmetingen van gegevenspunten, lijnen en balken aanpassen om trends beter aan te tonen. Ik kan de manier waarop de x-en y-as worden weergegeven veranderen om de plot er schoner uit te laten zien.
naast het maken van statische plots, hou ik af en toe van het animeren van percelen (zie Green Building Challenge en dormspam-the-game (Deel 1)). Het maken van plots is een creatief proces, vooral bij het maken van geanimeerde waar functies zoals kleur en grootte een ander doel kunnen dienen dan ze zouden kunnen in een statische plot.
visualisaties maken is mijn favoriete onderdeel van het proces. Ik hou ervan om mijn artistieke en technische kanten samen te laten komen.
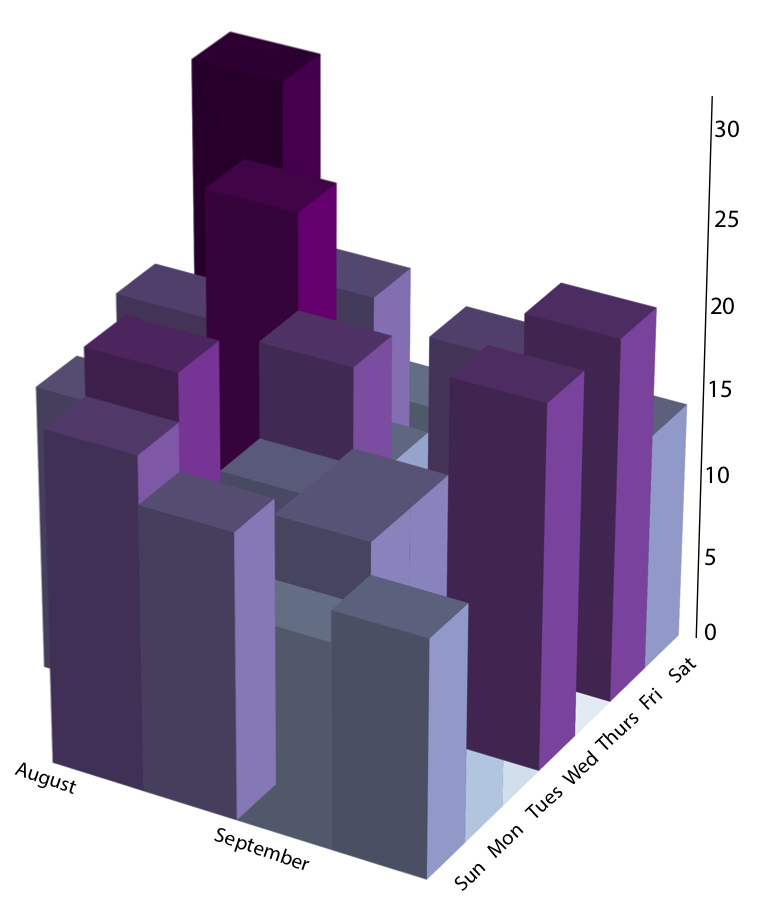
een plot uit mijn allereerste blogpost die het aantal stappen laat zien dat ik in duizenden heb gezet in mijn eerste paar weken aan het MIT
Vertel een verhaal
het is belangrijk om na te denken over hoe mijn gegevensanalyse en visualisaties kunnen bijdragen aan het vertellen van een verhaal over de trend die ik onderzoek of het fenomeen dat ik kwantificeer. Ik probeer plots te maken op een manier die het mogelijk maakt dat elke plot een nieuw deel van het verhaal laat zien. Ik probeer ze mijn complotten mijn posts te ordenen op een manier dat elk mijn woorden en mijn complotten samen geleidelijk een verhaal vertellen over wat er gaande is. Bijvoorbeeld, wanneer ik de gegevens van een spel heb gevisualiseerd, zou ik eerst de regels van het spel kunnen beschrijven, dan beschrijven wie er gewonnen heeft, en dan duiken in het begrijpen hoe verschillende spelerstrategieën de uitkomst beà nvloedden.
dus, dat is ongeveer hoe ik ga over het schrijven van mijn data analyse blogs. Ik scheidde het in 6 stappen, maar denken “achteruit” in plaats van strikt stap-voor-stap kan helpen om uw werk in de vorige stappen betekenisvoller. Als je nadenkt over hoe je het verhaal overtuigend kunt maken, kun je betere visualisaties maken. Als u weet welke visualisaties u zou willen maken, kunt u beter direct uw gegevensverzameling.
Leave a Reply