lexicale analyse in Compiler
lexicale analyse in compiler is de eerste stap in de analyse van het bronprogramma. De lexicale analyse leest de inputstroom van het bronprogramma karakter door karakter en produceert de opeenvolging van tekenen. Deze tokens worden verstrekt als input aan de parser voor het ontleden. In deze context zullen we het proces van lexicale analyse in het kort bespreken, samen met de lexicale fouten en hun herstel.
inhoud: Lexicale analyse in Compiler
- terminologieën in lexicale analyse
- Wat is lexicale analyse?
- voorbeelden van lexicale analyse
- rol van Lexical Analyzer
- Lexical Error
- Error Recovery
- Key Takeaways
Terminologies in Lexical Analysis
voordat we ingaan op wat lexical analysis is hoe het wordt uitgevoerd, laten we het hebben over enkele terminologieën die we zullen tegenkomen tijdens het bespreken van lexical analysis.
- Lexeme
Lexeme kan worden gedefinieerd als een reeks tekens die een patroon vormt en kan worden herkend als een token. - patroon
na het identificeren van het patroon van lexeme kan worden beschreven welk soort token kan worden gevormd. Zoals het patroon van sommige lexeme vormt een trefwoord, het patroon van sommige lexemen vormt een identifier. - Token
een lexeme met een geldig patroon vormt een token. In lexicale analyse kan een geldig token identifiers, trefwoorden, scheidingstekens, speciale tekens, constanten en operators zijn.
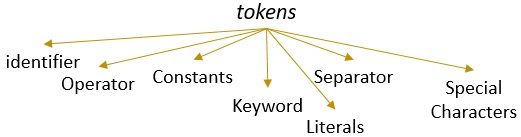
Wat is lexicale analyse?
eerder hebben we lexical analyzer niet meer gebruikt in onze content compiler in computer. We hebben geleerd dat de compiler de analyse van het bronprogramma door verschillende fasen uitvoert om het te transformeren naar het doelprogramma. De lexicale analyse is de eerste fase die het bronprogramma moet doorlopen.
de lexicale analyse is het proces van tokeniseren, d.w.z. het leest de invoerstring van een bronprogramma karakter voor karakter en zodra het een einde van het lexeme identificeert, identificeert het zijn patroon en zet het om in een token.
de lexicale analyzer bestaat uit twee opeenvolgende processen, waaronder scannen en lexicale analyse.
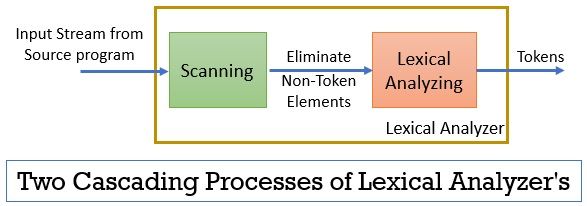
- scannen: de scanfase-alleen verwijdert de niet-token elementen uit het bronprogramma. Zoals het elimineren van opmerkingen, het comprimeren van de opeenvolgende witruimten enz.
- Lexicale Analyse: Lexicale analyse fase voert de tokenization op de output die door de scanner en daardoor produceert tokens.
het programma dat wordt gebruikt voor het uitvoeren van lexicale analyse wordt lexer of lexicale analyzer genoemd. Laten we nu een voorbeeld nemen van lexicale analyse uitgevoerd op een verklaring:
Voorbeeld 1 van lexicale analyse:
lexicale analyse in compilerontwerp, identificeer tokens.
nu, wanneer we dit statement lezen dan kunnen we gemakkelijk identificeren dat er negen tokens in het bovenstaande statement.
- Identifiers – > lexical
- Identifiers – > analyse
- Identifiers – > in
- Identifiers – > compiler
- Identifiers – > design
- scheidingsteken -> ,
- Identifiers – > identifiers
- Identifiers – > tokens
- scheidingsteken – > .
dus zoals in totaal, zijn er 9 tokens in de bovenstaande stroom van tekens.
Voorbeeld 2 van lexicale analyse:
printf (“waarde van i is % d”, i);
laten we nu proberen tokens uit deze invoerstroom te vinden.
- Trefwoord -> printf
- Speciale Tekens -> (
- Letterlijke -> “Waarde van i is %d “
- Separator -> ,
- Id -> i
- Speciale Tekens -> )
- Separator -> ;
Opmerking:
- De hele string in tussen de dubbele aanhalingstekens d.w.z. “” wordt beschouwd als één token.
- de lege witruimte tussen de tekens in de invoerstroom scheidt alleen de tokens en wordt dus geëlimineerd bij het tellen van de tokens.
rol van lexicale Analyzer
als eerste fase in de analyse van het bronprogramma speelt de lexicale analyzer een belangrijke rol in de transformatie van het bronprogramma naar het doelprogramma.
dit hele scenario kan worden gerealiseerd met behulp van de onderstaande figuur:
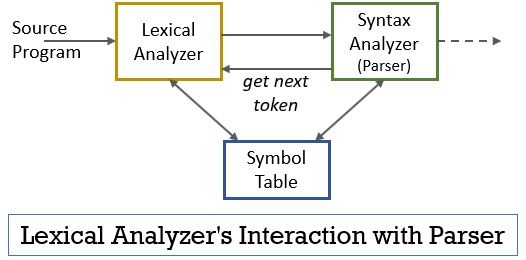
- de lexical analyzer fase heeft de scanner of lexer programma geà mplementeerd in het die tokens produceert slechts wanneer zij door de parser worden bevolen om dit te doen.
- de parser genereert het getNextToken commando en stuurt het naar de lexical analyzer als antwoord hierop de lexical analyzer begint de invoerstroom karakter voor karakter te lezen totdat het een lexeme identificeert die als token herkend kan worden.
- zodra een token wordt geproduceerd, stuurt de lexical analyzer het naar de syntaxis analyzer voor het ontleden.
- samen met de syntaxis analyzer communiceert de lexical analyzer ook met de symbolentabel. Wanneer een lexical analyzer een lexeme identificeert als een identifier, wordt die lexeme ingevoerd in de symbolentabel.
- soms helpt de informatie van identifier in symbolentabel lexical analyzer bij het bepalen van het token dat naar de parser moet worden verzonden.
- behalve het identificeren van de tokens in de invoerstroom, elimineert de lexical analyzer ook de spatie/witruimte en de commentaren van het programma. Dergelijke andere dingen omvatten tekens de scheidt tokens, tabbladen, lege spaties, nieuwe regels.
- de lexical analyzer helpt bij het relateren van de foutmeldingen geproduceerd door de compiler. Gewoon, bijvoorbeeld, de lexical analyzer houdt het record van elke nieuwe regel karakter dat het tegenkomt tijdens het scannen van het bronprogramma, zodat het gemakkelijk de foutmelding met het regelnummer van het bronprogramma relateert.
- als het bronprogramma macro ‘s gebruikt, breidt de lexical analyzer de macro’ s in het bronprogramma uit.
lexicale fout
de lexicale analyzer zelf is niet efficiënt om de fout van het bronprogramma te bepalen. Overweeg bijvoorbeeld een statement:
prtf (“waarde van i is % d”, i);
nu, in het bovenstaande statement wanneer de string prtf wordt aangetroffen, kan de lexical analyzer niet raden of de prtf een onjuiste spelling is van het trefwoord ‘printf’ of dat het een niet-aangegeven functie-ID is.
maar volgens de vooraf gedefinieerde regel is prtf een geldig lexeme waarvan het patroon concludeert dat het een identifier token is. Nu, de lexical analyzer zal prtf token te sturen naar de volgende fase dat wil zeggen parser die de fout die zich heeft voorgedaan als gevolg van de omzetting van letters zal behandelen.
foutherstel
soms is het zelfs onmogelijk voor een lexical analyzer om een lexeme als token te identificeren, omdat het patroon van het lexeme niet overeenkomt met een van de vooraf gedefinieerde patronen voor tokens. In dit geval moeten we een aantal foutherstelstrategieën toepassen.
- in panic mode recovery wordt het opeenvolgende teken uit het lexeme verwijderd totdat de lexical analyzer een geldig token identificeert.
- verwijder het eerste teken uit de resterende invoer.
- Identificeer het mogelijk ontbrekende teken en plaats het op de juiste wijze in de resterende invoer.
- Vervang een teken in de resterende invoer om een geldig token te krijgen.
- Verwissel de positie van twee aangrenzende tekens in de resterende invoer.
controleer tijdens het uitvoeren van de bovenstaande foutherstelacties of het voorvoegsel van de resterende invoer overeenkomt met een patroon van tokens. In het algemeen, een lexicale fout optreedt als gevolg van een enkel teken. Dus, je kunt de lexicale fout corrigeren met een enkele transformatie. En voor zover mogelijk moet een kleiner aantal transformaties het bronprogramma omzetten in een reeks geldige tokens die het kan overdragen aan de parser.
Key Takeaways
- lexicale analyse is de eerste fase in de analyse van het bronprogramma in de compiler.
- de lexical analyzer wordt geïmplementeerd door twee opeenvolgende processen scanner en lexicale analyse.
- Scanner elimineert de niet-token elementen uit de invoerstroom.
- lexicale analyse voert tokenisatie uit.
- de lexical analyzer genereert dus een reeks tokens en stuurt ze door naar de parser.
- de parser bij het bezit van een token van de lexical analyzer voert een aanroep getNextToken die erop staan dat de lexical analyzer de invoerstroom van tekens leest totdat het het volgende token identificeert.
- als de lexical analyzer het patroon van een lexeme identificeert als een identifier, dan voert de lexical analyzer dat lexeme in in de symbolentabel voor toekomstig gebruik.
- Lexical analyzer is niet efficiënt om fouten in het bronprogramma alleen te identificeren.
- als er een lexeme optreedt waarvan het patroon niet overeenkomt met een van de vooraf gedefinieerde patronen van tokens, moet u acties voor foutherstel uitvoeren om de fout te herstellen.
dus, dit gaat allemaal over de lexicale analyse die de stroom van tekens transformeert in tokens en geeft het door aan de parser. We hebben geleerd over de werking van lexicale analyse met behulp van een voorbeeld. We hebben de discussie afgesloten met de lexicale fout en de herstelstrategie.
Leave a Reply