Analiza leksykalna w kompilatorze
Analiza leksykalna w kompilatorze jest pierwszym krokiem w analizie programu źródłowego. Analiza leksykalna odczytuje strumień wejściowy z programu źródłowego znak po znaku i tworzy sekwencję tokenów. Tokeny te są dostarczane jako wejście do parsera w celu parsowania. W tym kontekście omówimy w skrócie proces analizy leksykalnej wraz z błędami leksykalnymi i ich odzyskiwaniem.
zawartość: Analiza leksykalna w kompilatorze
- Terminologie w analizie leksykalnej
- czym jest analiza leksykalna?
- przykłady analizy leksykalnej
- rola analizatora leksykalnego
- błąd leksykalny
- Odzyskiwanie błędów
- najważniejsze wnioski
Terminologie w analizie leksykalnej
zanim przejdziemy do tego, co to jest analiza leksykalna, porozmawiajmy o niektórych terminologiach, które napotkamy podczas omawiania analizy leksykalnej.
- leksem
leksem można zdefiniować jako ciąg znaków, który tworzy wzorzec i może być rozpoznany jako token. - wzór
po zidentyfikowaniu wzoru leksemu można opisać, jaki rodzaj tokenu można utworzyć. Tak jak wzorzec niektórych leksemów tworzy słowo kluczowe, wzorzec niektórych leksemów tworzy identyfikator. - Token
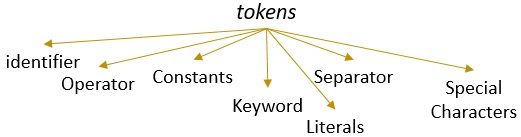
leksem z prawidłowym wzorcem tworzy token. W analizie leksykalnej ważnym tokenem mogą być identyfikatory, słowa kluczowe, separatory, znaki specjalne, stałe i operatory.
czym jest analiza leksykalna?
wcześniej nie używaliśmy analizatora leksykalnego w naszym kompilatorze treści w komputerze. Dowiedzieliśmy się, że kompilator przeprowadza analizę programu źródłowego przez różne fazy, aby przekształcić go w program docelowy. Analiza leksykalna jest pierwszą fazą, przez którą musi przejść program źródłowy.
analiza leksykalna to proces tokenizacji tj. czyta ciąg wejściowy programu źródłowego znak po znaku i jak tylko identyfikuje koniec leksemu, identyfikuje jego wzorzec i konwertuje go na token.
analizator leksykalny składa się z dwóch następujących po sobie procesów, które obejmują skanowanie i analizę leksykalną.
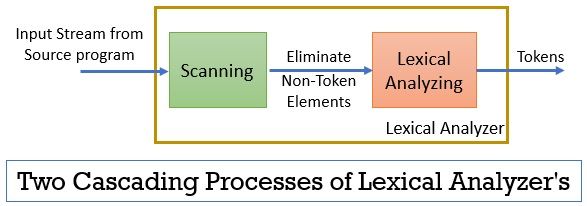
- skanowanie: Faza skanowania-eliminuje tylko elementy niebanalne z programu źródłowego. Takich jak eliminacja komentarzy, zagęszczanie kolejnych białych spacji itp.
- Analiza Leksykalna: Faza analizy leksykalnej wykonuje tokenizację na wyjściu dostarczonym przez skaner i w ten sposób wytwarza tokeny.
program używany do wykonywania analizy leksykalnej jest określany jako lexer lub lexical analyzer. Weźmy teraz przykład analizy leksykalnej wykonanej na oświadczeniu:
przykład 1 analizy leksykalnej:
Analiza leksykalna w projektowaniu kompilatora, identyfikacja tokenów.
teraz, kiedy przeczytamy to oświadczenie, możemy łatwo zidentyfikować, że w powyższym oświadczeniu jest dziewięć żetonów.
- identyfikatory -> leksykalne
- identyfikatory -> analiza
- identyfikatory -> w
- identyfikatory – > kompilator
- identyfikatory – > projektowanie
- Separator -> ,
- identyfikatory – > identyfikacja
- identyfikatory -> tokeny
- Separator -> .
tak więc w sumie w powyższym strumieniu znaków jest 9 tokenów.
przykład 2 analizy leksykalnej:
printf(” value of I is %d “, i);
spróbujmy teraz znaleźć tokeny z tego strumienia wejściowego.
- słowo kluczowe – > printf
- znak specjalny-> (
- Literal – > “wartość i to %d”
- Separator -> ,
- identyfikator- > i
- znak specjalny -> )
- Separator -> ;
Uwaga:
- cały łańcuch wewnątrz podwójnego odwróconego przecinka tj. “” jest uważany za pojedynczy token.
- pusta Biała spacja oddzielająca znaki w strumieniu wejściowym oddziela tylko tokeny i w ten sposób jest eliminowana podczas liczenia tokenów.
rola analizatora leksykalnego
będąc pierwszą fazą analizy programu źródłowego analizator leksykalny odgrywa ważną rolę w transformacji programu źródłowego do programu docelowego.
cały ten scenariusz można zrealizować za pomocą poniższego rysunku:
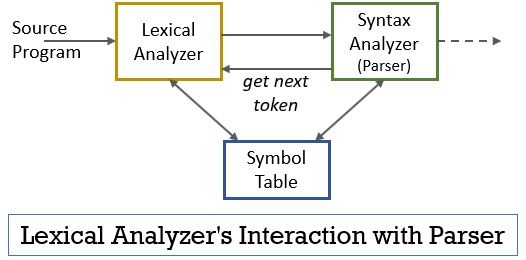
- analizator leksykalny ma zaimplementowany w nim program skanera lub lexera, który wytwarza tokeny tylko wtedy, gdy są one nakazane przez parser.
- parser generuje polecenie getNextToken i wysyła je do analizatora leksykalnego w odpowiedzi na to analizator leksykalny rozpoczyna odczyt strumienia wejściowego znak po znaku, dopóki nie zidentyfikuje leksemu, który może być rozpoznany jako token.
- gdy tylko token zostanie wytworzony, analizator leksykalny wysyła go do analizatora składni w celu przetworzenia.
- wraz z analizatorem składni, analizator leksykalny komunikuje się również z tabelą symboli. Gdy analizator leksykalny identyfikuje leksem jako identyfikator, wprowadza go do tabeli symboli.
- czasami informacja o identyfikatorze w tabeli symboli pomaga analizatorowi leksykalnemu w określeniu tokenu, który ma zostać wysłany do parsera.
- oprócz identyfikacji tokenów w strumieniu wejściowym, analizator leksykalny eliminuje również pustą spację/białą spację i komentarze programu. Takie inne rzeczy obejmują znaki oddziela żetony, tabulatory, spacje, nowe linie.
- analizator leksykalny pomaga w powiązaniu komunikatów o błędach generowanych przez kompilator. Na przykład analizator leksykalny przechowuje zapis każdego nowego znaku linii, który natknie się podczas skanowania programu źródłowego, dzięki czemu łatwo łączy komunikat o błędzie z numerem linii programu źródłowego.
- jeśli program źródłowy używa makr, analizator leksykalny rozszerza makra w programie źródłowym.
błąd leksykalny
sam analizator leksykalny nie jest skuteczny do określenia błędu z programu źródłowego. Na przykład rozważmy polecenie:
prtf (“wartość i to %d”, i);
teraz, w powyższej instrukcji, gdy napotkany jest ciąg prtf, analizator leksykalny nie jest w stanie odgadnąć, czy prtf jest nieprawidłową pisownią słowa kluczowego ‘printf’, czy jest to niezgłoszony identyfikator funkcji.
ale zgodnie z predefiniowaną regułą prtf jest poprawnym leksem, którego wzorzec zakłada, że jest tokenem identyfikującym. Teraz analizator leksykalny wyśle token prtf do następnej fazy, czyli parsera, który będzie obsługiwał błąd, który wystąpił z powodu transpozycji liter.
Odzyskiwanie błędów
cóż, czasami jest nawet niemożliwe, aby analizator leksykalny zidentyfikował leksem jako token, ponieważ wzór leksemu nie pasuje do żadnego z predefiniowanych wzorców dla tokenów. W tym przypadku musimy zastosować kilka strategii odzyskiwania błędów.
- w trybie panic odzyskiwanie kolejnych znaków z leksemu jest usuwane, dopóki analizator leksykalny nie zidentyfikuje poprawnego tokenu.
- wyeliminuj pierwszy znak z pozostałego wejścia.
- Zidentyfikuj ewentualny brakujący znak i włóż go odpowiednio do pozostałych danych wejściowych.
- Zastąp znak w pozostałym wejściu, aby uzyskać prawidłowy token.
- Wymień pozycję dwóch sąsiednich znaków w pozostałym wejściu.
podczas wykonywania powyższych czynności odzyskiwania błędów Sprawdź, czy prefiks pozostałego wejścia pasuje do dowolnego wzorca tokenów. Ogólnie rzecz biorąc, błąd leksykalny występuje z powodu pojedynczego znaku. Można więc skorygować błąd leksykalny za pomocą pojedynczej transformacji. I tak dalece, jak to możliwe, mniejsza liczba przekształceń musi przekształcić program źródłowy w sekwencję ważnych tokenów, które może przekazać parserowi.
kluczowe zagadnienia
- Analiza leksykalna jest pierwszym etapem analizy programu źródłowego w kompilatorze.
- analizator leksykalny realizowany jest przez dwa kolejne procesy: skaner i analizę leksykalną.
- Skaner eliminuje elementy nie-tokenowe ze strumienia wejściowego.
- Analiza leksykalna wykonuje tokenizację.
- tak więc analizator leksykalny generuje sekwencję tokenów i przekazuje je do parsera.
- parser na posiadaniu tokenu z analizatora leksykalnego wykonuje wywołanie getNextToken, które wymaga, aby analizator leksykalny odczytał strumień wejściowy znaków, dopóki nie zidentyfikuje następnego tokena.
- jeśli analizator leksykalny identyfikuje wzorzec leksemu jako identyfikator, to analizator leksykalny wprowadza ten lekseme do tabeli symboli do wykorzystania w przyszłości.
- Analizator leksykalny nie jest skuteczny w wykrywaniu błędów w samym programie źródłowym.
- jeśli wystąpi leksem, którego wzorzec nie pasuje do żadnego z predefiniowanych wzorców tokenów, musisz wykonać działania odzyskiwania błędów, aby naprawić błąd.
chodzi więc o analizę leksykalną, która przekształca strumień znaków w tokeny i przekazuje go do parsera. O działaniu analizy leksykalnej dowiedzieliśmy się na przykładzie. Zakończyliśmy dyskusję błędem leksykalnym i jego strategią odzyskiwania.
Leave a Reply