Walidacja danych i weryfikacja danych – od słownika do uczenia maszynowego
Aditya Aggarwal, Kierownik ds. zaawansowanych analiz i Arnab Bose, Chief Scientific Officer, Abzooba
dość często używamy weryfikacji danych i walidacji danych zamiennie, gdy mówimy o jakości danych. Jednak te dwa terminy są różne. W tym artykule zrozumiemy różnicę w 4 różnych kontekstach:
- słownikowe znaczenie weryfikacji i walidacji
- różnica między weryfikacją danych a walidacją ogólnie
- różnica między weryfikacją a walidacją z perspektywy rozwoju oprogramowania
- różnica między weryfikacją danych a walidacją danych z perspektywy uczenia maszynowego
słownikowe znaczenie weryfikacji i walidacji
tabela 1 wyjaśnia słownikowe znaczenie słów weryfikacja i walidacja na kilku przykładach.

podsumowując, weryfikacja polega na prawdziwości i dokładności, podczas gdy Walidacja polega na wspieraniu siły punktu widzenia lub poprawności twierdzenia. Walidacja sprawdza poprawność metodologii, podczas gdy weryfikacja sprawdza dokładność wyników.
różnica między weryfikacją danych a walidacją danych ogólnie
teraz, gdy rozumiemy dosłowne znaczenie tych dwóch słów, zbadajmy różnicę między “weryfikacją danych” a “walidacją danych”.
- weryfikacja danych: aby upewnić się, że dane są dokładne.
- walidacja danych: aby upewnić się, że dane są poprawne.
omówmy przykłady w tabeli 2.

różnica między weryfikacją a walidacją z perspektywy rozwoju oprogramowania
z perspektywy rozwoju oprogramowania,
- weryfikacja odbywa się w celu zapewnienia, że oprogramowanie jest wysokiej jakości, dobrze zaprojektowane, solidne i wolne od błędów bez wchodzenia w jego użyteczność.
- Walidacja odbywa się w celu zapewnienia użyteczności oprogramowania i możliwości spełnienia potrzeb klienta.
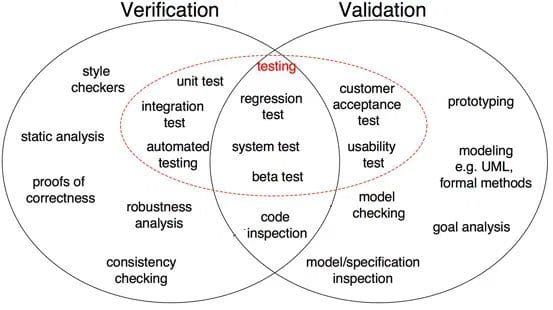
Rys. 1: Różnice między weryfikacją a walidacją w tworzeniu oprogramowania (źródło)
jak pokazano na Rys. 1, Dowód poprawności, analiza solidności, testy jednostkowe, test integracyjny i inne to wszystkie etapy weryfikacji, w których zadania są ukierunkowane na weryfikację specyfiki. Wyjście oprogramowania jest weryfikowane w stosunku do żądanego wyjścia. Z drugiej strony, Kontrola modelu, testowanie czarnej skrzynki, testowanie użyteczności to wszystkie etapy walidacji, w których zadania są zorientowane na zrozumienie, czy oprogramowanie spełnia wymagania i oczekiwania.
różnica między weryfikacją danych a walidacją danych z perspektywy uczenia maszynowego
rola weryfikacji danych w potoku uczenia maszynowego polega na roli strażnika. Zapewnia dokładne i aktualizowane dane w czasie. Weryfikacja danych odbywa się przede wszystkim na nowym etapie pozyskiwania danych, tj. na etapie 8 rurociągu ML, Jak pokazano na Fig. 2. Przykładami tego kroku są identyfikacja zduplikowanych rekordów i wykonanie deduplikacji oraz usunięcie niedopasowania w informacjach o kliencie w polu takim jak adres lub numer telefonu.
z drugiej strony walidacja danych (na etapie 3 potoku ML) zapewnia, że przyrostowe dane z kroku 8, które są dodawane do danych uczenia się, są dobrej jakości i podobne (z perspektywy właściwości statystycznych) do istniejących danych szkoleniowych. Obejmuje to na przykład wykrywanie anomalii danych lub wykrywanie różnic między istniejącymi danymi treningowymi a nowymi danymi, które należy dodać do danych treningowych. W przeciwnym razie wszelkie problemy z jakością danych/różnice statystyczne w danych przyrostowych mogą zostać pominięte, a błędy szkoleniowe mogą gromadzić się w czasie i pogarszać dokładność modelu. W ten sposób walidacja danych wykrywa istotne zmiany (jeśli występują) w przyrostowych danych treningowych na wczesnym etapie, co pomaga w analizie przyczyn źródłowych.
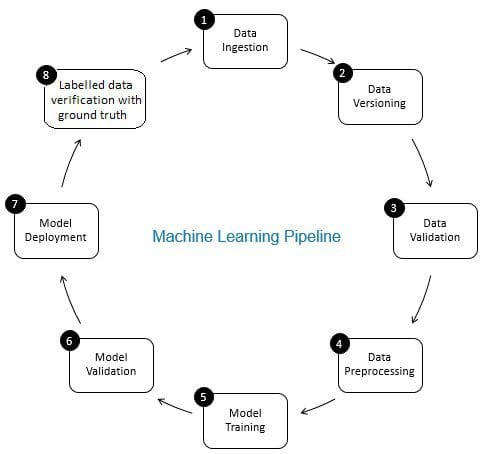
Rys. 2: składniki potoku uczenia maszynowego
Aditya Aggarwal pełni funkcję Data Science-Practice Lead w Abzooba Inc. Z ponad 12-letnim doświadczeniem w realizacji celów biznesowych poprzez rozwiązania oparte na danych, Aditya specjalizuje się w analizie predykcyjnej, uczeniu maszynowym, Business intelligence & strategii biznesowej w wielu branżach.
Dr Arnab Bose jest dyrektorem naukowym w Abzooba, firmie zajmującej się analityką danych i adiunktem na Uniwersytecie w Chicago, gdzie uczy uczenia maszynowego i analizy predykcyjnej, operacji uczenia maszynowego, analizy szeregów czasowych i prognozowania oraz analizy zdrowia w programie Master of Science in Analytics. Jest 20-letnim doświadczonym analitykiem predykcyjnym w branży, który lubi wykorzystywać nieustrukturyzowane i ustrukturyzowane dane do prognozowania i wpływania na wyniki behawioralne w opiece zdrowotnej, handlu detalicznym, finansach i transporcie. Obecnie zajmuje się stratyfikacją ryzyka zdrowotnego i zarządzaniem przewlekłymi chorobami z wykorzystaniem uczenia maszynowego oraz wdrażaniem i monitorowaniem modeli uczenia maszynowego.
podobne:
- MLOps – ” dlaczego jest to wymagane?”i” co to jest”?
- mój model uczenia maszynowego się nie uczy. Co mam zrobić?
- Obserwowalność danych, Część II: Jak zbudować własne Monitory jakości danych za pomocą SQL
Leave a Reply