análise Lexical no compilador
análise Lexical no compilador é o primeiro passo na análise do programa de origem. A análise lexical lê o fluxo de entrada do caractere do programa de origem por caractere e produz a sequência de tokens. Esses tokens são fornecidos como uma entrada para o analisador para análise. Nesse contexto, discutiremos o processo de análise lexical em breve, juntamente com os erros lexicais e sua recuperação.
conteúdo: Análise Lexical no compilador
- terminologias na análise Lexical
- o que é análise Lexical?
- Exemplos de Análise Léxica
- a Função do Analisador Léxico
- Lexical Erro
- Recuperação de Erro
- Pedidas
Terminologias em Análise Léxica
Antes de chegar em que a análise léxica é a forma como ela é executada vamos falar sobre algumas terminologias que vamos encontrar ao discutir a análise léxica.
- lexema
o lexema pode ser definido como uma sequência de caracteres que forma um padrão e pode ser reconhecido como um token. - Pattern
depois de identificar o padrão do lexema, pode-se descrever que tipo de token pode ser formado. Como o padrão de algum lexema forma uma palavra-chave, o padrão de alguns lexemas forma um identificador. - Token
um lexema com um padrão válido forma um token. Na análise lexical, um token válido pode ser identificadores, palavras-chave, separadores, caracteres especiais, constantes e operadores.
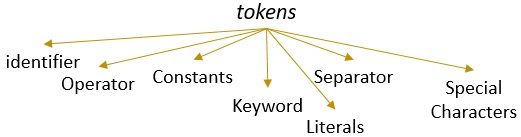
O Que É análise Lexical?
anteriormente, desativamos o lexical analyzer em nosso compilador de conteúdo no computador. Aprendemos que o compilador realiza a análise do programa de origem por meio de diferentes fases para transformá-lo no programa de destino. A análise lexical é a primeira fase pela qual o programa de origem deve passar.
a análise lexical é o processo de tokenização, ou seja, ele lê a string de entrada de um caractere de programa de origem por caractere e, assim que identifica um final do lexema, identifica seu padrão e o converte em um token.
o analisador lexical consiste em dois processos consecutivos que incluem digitalização e análise lexical.
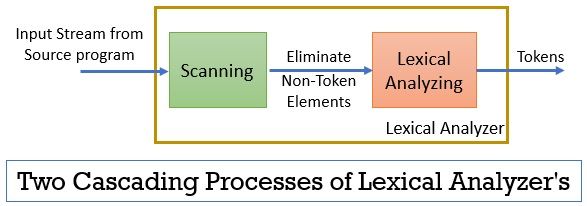
- Digitalização: a fase de digitalização elimina apenas os elementos não simbólicos do programa de origem. Como eliminar comentários, compactando os espaços em branco consecutivos, etc.
- Análise Lexical: A fase de análise Lexical executa a tokenização na saída fornecida pelo scanner e, assim, produz tokens.
o programa utilizado para a realização de análise lexical é referido como lexer ou analisador lexical. Agora vamos dar um exemplo de análise lexical realizada em uma declaração:
exemplo 1 de análise Lexical:
análise Lexical no design do compilador, identifique tokens.
agora, quando lermos esta declaração, Podemos identificar facilmente que existem nove tokens na declaração acima.
- Identificadores -> lexical
- Identificadores -> análise
- Identificadores -> em
- Identificadores -> compilador
- Identificadores -> design
- Separador -> ,
- Identificadores -> identificar
- Identificadores -> tokens
- Separador> .
assim como no total, existem 9 tokens no fluxo de caracteres acima.
Exemplo 2 da Análise Léxica:
printf(” valor de i é %d “, i);
Agora vamos tentar encontrar tokens de fora deste fluxo de entrada.
- Palavra-chave> printf
- Caractere Especial -> (
- Literal -> “Valor de i é %d “
- Separador -> ,
- Identificador -> eu
- Caractere Especial -> )
- Separador de -> ;
Nota:
- toda A cadeia de caracteres dentro do duplo vírgulas invertidas i.e. “” é considerado um único token.
- o espaço em branco que separa os caracteres no fluxo de entrada separa apenas os tokens e, portanto, é eliminado durante a contagem dos tokens.
papel do analisador Lexical
sendo a primeira fase na análise do programa de origem o analisador lexical desempenha um papel importante na transformação do programa de origem para o programa de destino.
todo Este cenário pode ser realizado com a ajuda da figura dada abaixo:
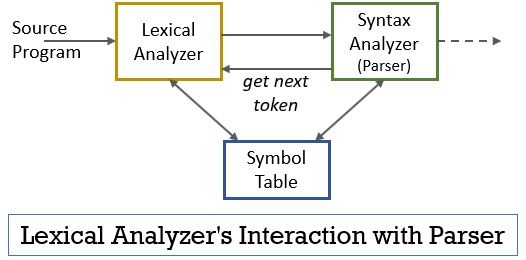
- O analisador léxico da fase de scanner ou lexer programa implantado em que produz tokens apenas quando eles são comandados pelo analisador para fazê-lo.
- o analisador gera o comando getNextToken e o envia para o analisador lexical como resposta a isso, o analisador lexical começa a ler o caractere de fluxo de entrada por caractere até identificar um lexema que pode ser reconhecido como um token.
- assim que um token é produzido, o analisador lexical o envia ao analisador de sintaxe para análise.
- juntamente com o analisador de sintaxe, o analisador lexical também se comunica com a tabela de símbolos. Quando um analisador lexical identifica um lexema como um identificador, ele insere esse lexema na tabela de símbolos.
- às vezes, as informações do identificador na tabela de símbolos ajudam o analisador lexical a determinar o token que deve ser enviado ao analisador.
- além de identificar os tokens no fluxo de entrada, o analisador lexical também elimina o espaço em branco/espaço em branco e os comentários do programa. Essas outras coisas incluem caracteres que separam tokens, guias, espaços em branco, novas linhas.
- o analisador lexical ajuda a relacionar as mensagens de erro produzidas pelo compilador. Apenas, por exemplo, o analisador lexical mantém o registro de cada novo caractere de linha que ele encontra ao digitalizar o programa de origem para que ele facilmente relacione a mensagem de erro com o número da linha do programa de origem.
- se o programa de origem usa macros, o analisador lexical expande as macros no programa de origem.
erro Lexical
o próprio analisador lexical não é eficiente para determinar o erro do programa de origem. Por exemplo, considere uma declaração:
prtf (“valor de I é %d”, i);
agora, na instrução acima, quando a string prtf é encontrada, o analisador lexical não consegue adivinhar se o prtf é uma grafia incorreta da palavra-chave ‘printf’ ou se é um identificador de função não declarado.
mas de acordo com a regra predefinida prtf é um lexema válido cujo padrão conclui que é um token identificador. Agora, o analisador lexical enviará o token prtf para a próxima fase, ou seja, analisador que estará lidando com o erro que ocorreu devido à transposição de letras.
recuperação de erros
bem, às vezes é até impossível para um analisador lexical identificar um lexema como um token, pois o padrão do lexema não corresponde a nenhum dos padrões predefinidos para tokens. Nesse caso, temos que aplicar algumas estratégias de recuperação de erros.
- na recuperação do modo de pânico, o caractere sucessivo do lexema é excluído até que o analisador lexical identifique um token válido.
- elimine o primeiro caractere da entrada restante.
- identifique o possível caractere ausente e insira-o na entrada restante adequadamente.
- substitua um caractere na entrada restante para obter um token válido.
- troque a posição de dois caracteres adjacentes na entrada restante.
ao executar as ações de recuperação de erro acima, verifique se o prefixo da entrada restante corresponde a qualquer padrão de tokens. Geralmente, ocorre um erro lexical devido a um único caractere. Portanto, você pode corrigir o erro lexical com uma única transformação. E, na medida do possível, um número menor de transformações deve converter o programa de origem em uma sequência de tokens válidos que ele pode entregar ao analisador.
key Takeaways
- a análise Lexical é a primeira fase na análise do programa de origem no compilador.
- o analisador lexical é implementado por dois processos consecutivos scanner e análise lexical.
- o Scanner elimina os elementos não simbólicos do fluxo de entrada.
- a análise Lexical realiza a tokenização.
- assim, o analisador lexical gera uma sequência de tokens e os encaminha para o analisador.
- o analisador em possuir um token do analisador lexical faz uma chamada getNextToken que insiste que o analisador lexical leia o fluxo de entrada de caracteres até identificar o próximo token.
- se o analisador lexical identifica o padrão de um lexema como um identificador, o analisador lexical insere esse lexema na tabela de símbolos para uso futuro.
- Lexical analyzer não é eficiente para identificar qualquer erro no programa de origem sozinho.
- se ocorrer um lexema cujo padrão não corresponde a nenhum dos padrões predefinidos de tokens, você deve executar ações de recuperação de erro para corrigir o erro.
então, isso é tudo sobre a análise lexical que transforma o fluxo de caracteres em tokens e o passa para o analisador. Aprendemos sobre o trabalho da análise lexical com a ajuda de um exemplo. Concluímos a discussão com o erro lexical e sua estratégia de recuperação.
Leave a Reply