Validação de Dados e de Verificação de Dados – a Partir de Dicionário para Machine Learning
Por Aditya Aggarwal, análises Avançadas Práticas de Chumbo, e Arnab Bose, Chief Scientific Officer, Abzooba
muitas vezes, usamos os dados de verificação e validação de dados de forma intercambiável, quando falamos sobre a qualidade dos dados. No entanto, esses dois termos são distintos. Neste artigo, vamos entender a diferença em 4 contextos diferentes:
- Dicionário de significado de verificação e validação
- Diferença entre os dados de verificação e validação de dados em geral
- Diferença entre verificação e validação a partir da perspectiva de desenvolvimento de software
- Diferença entre os dados de verificação e validação de dados a partir da máquina perspectiva de aprendizado
Dicionário de significado de verificação e validação
A tabela 1 explica dicionário o significado das palavras que a verificação e a validação com alguns exemplos.

para resumir, a verificação é sobre verdade e precisão, enquanto a validação é sobre apoiar a força de um ponto de vista ou a correção de uma reivindicação. A validação verifica a exatidão de uma metodologia enquanto a verificação verifica a precisão dos resultados.
Diferença entre os dados de verificação e validação de dados em geral
Agora que entendemos o significado literal das palavras, vamos explorar a diferença entre a “data de verificação” e “validação de dados”.
- verificação de dados: para se certificar de que os dados são precisos.
- validação de dados: para se certificar de que os dados estão corretos.
vamos elaborar com exemplos na Tabela 2.

Diferença entre verificação e validação a partir da perspectiva de desenvolvimento de software
a Partir de uma perspectiva de desenvolvimento de software,
- a Verificação é feita para garantir que o software é de alta qualidade, com boa engenharia, robusto e livre de erros, sem entrar em sua usabilidade.
- a validação é feita para garantir a usabilidade e a capacidade do software para atender às necessidades do cliente.
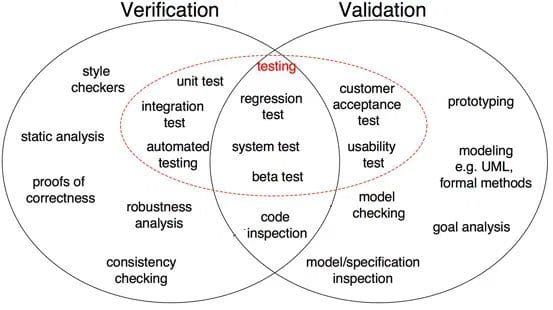
Fig 1: Diferenças entre verificação e validação no desenvolvimento de software (Fonte)
conforme mostrado na Fig 1, prova de correção, análise de robustez, testes de Unidade, Teste de integração e outros são todas as etapas de verificação em que as tarefas são orientadas para verificar detalhes. A saída do Software é verificada contra a saída desejada. Por outro lado, inspeção de modelo, teste de caixa preta, teste de usabilidade são todas as etapas de validação em que as tarefas são orientadas para entender se o software atende aos requisitos e expectativas.
diferença entre verificação de dados e validação de dados da perspectiva de aprendizado de máquina
o papel da verificação de dados no pipeline de aprendizado de máquina é o de um gatekeeper. Ele garante dados precisos e atualizados ao longo do tempo. A verificação de dados é feita principalmente no novo estágio de aquisição de dados, ou seja, na Etapa 8 do pipeline de ML, conforme mostrado na Fig. 2. Exemplos desta etapa São identificar registros duplicados e executar a desduplicação e limpar a incompatibilidade nas informações do cliente em campo, como endereço ou número de telefone.Por outro lado, a validação de dados (na Etapa 3 do pipeline de ML) garante que os dados incrementais da Etapa 8 que são adicionados aos dados de aprendizagem sejam de boa qualidade e semelhantes (da perspectiva de propriedades estatísticas) aos dados de treinamento existentes. Por exemplo, isso inclui encontrar anomalias de dados ou detectar diferenças entre dados de treinamento existentes e novos dados a serem adicionados aos dados de treinamento. Caso contrário, qualquer problema de qualidade de dados/diferenças estatísticas em dados incrementais podem ser perdidas e erros de treinamento podem se acumular ao longo do tempo e deteriorar a precisão do modelo. Assim, a validação de dados detecta mudanças significativas (se houver) nos dados de treinamento incremental em um estágio inicial que ajuda na análise de causa raiz.
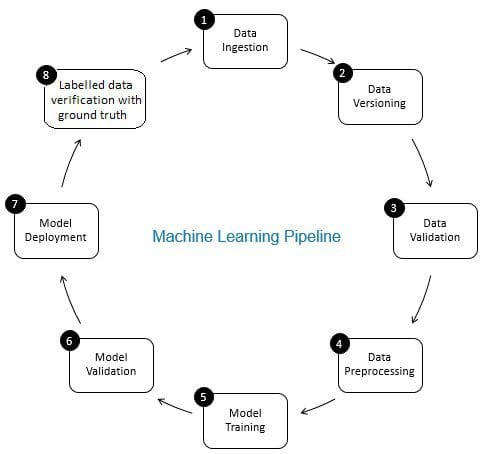
Fig 2: componentes do Pipeline de aprendizado de máquina
Aditya Aggarwal atua como líder em Ciência de dados na Abzooba Inc. Com mais de 12 anos de experiência na condução de metas de negócios por meio de soluções baseadas em dados, a Aditya é especializada em análise preditiva, aprendizado de máquina, inteligência de negócios & estratégia de negócios em vários setores.
Dr. Arnab Bose é Diretor Científico da Abzooba, uma empresa de análise de dados e um corpo docente adjunto da Universidade de Chicago, onde ensina aprendizado de máquina e Análise Preditiva, operações de aprendizado de máquina, Análise e previsão de Séries Temporais e Análise de Saúde no Programa de Mestrado em análise. Ele é um veterano do setor de análise preditiva de 20 anos que gosta de usar dados não estruturados e estruturados para prever e influenciar resultados comportamentais em saúde, varejo, finanças e transporte. Suas Áreas de foco atuais incluem estratificação de risco à saúde e gerenciamento de doenças crônicas usando aprendizado de máquina e implantação e monitoramento de produção de modelos de aprendizado de máquina.
Relacionados:
- MLOps – “Por que é necessária?”e” o que é”?
- meu modelo de aprendizado de máquina não aprende. O que devo fazer?
- observabilidade de Dados, Parte II: como construir seus próprios monitores de qualidade de dados usando SQL
Leave a Reply