validarea datelor și verificarea datelor – de la dicționar La Machine Learning
de Aditya Aggarwal, Advanced Analytics Practice Lead și Arnab Bose, Chief Scientific Officer, Abzooba
destul de des, folosim verificarea datelor și validarea datelor în mod interschimbabil atunci când vorbim despre calitatea datelor. Cu toate acestea, acești doi termeni sunt distincți. În acest articol, vom înțelege diferența în 4 contexte diferite:
- dicționar semnificația verificării și validării
- diferența dintre verificarea datelor și validarea datelor în general
- diferența dintre verificarea și validarea din perspectiva dezvoltării de software
- diferența dintre verificarea datelor și validarea datelor din perspectiva învățării automate
dicționar semnificația verificării și validării
tabelul 1 explică semnificația din dicționar a cuvintelor verificare și validare cu câteva exemple.

pentru a rezuma, verificarea se referă la adevăr și acuratețe, în timp ce validarea se referă la susținerea puterii unui punct de vedere sau a corectitudinii unei revendicări. Validarea verifică corectitudinea unei metodologii, în timp ce verificarea verifică exactitatea rezultatelor.
diferența dintre verificarea datelor și validarea datelor în general
acum, că înțelegem sensul literal al celor două cuvinte, să explorăm diferența dintre “verificarea datelor” și “validarea datelor”.
- verificarea datelor: pentru a vă asigura că datele sunt corecte.
- validarea datelor: pentru a vă asigura că datele sunt corecte.
să detaliem cu exemple din tabelul 2.

diferența dintre verificare și validare din perspectiva dezvoltării de software
din perspectiva dezvoltării de software,
- verificarea se face pentru a se asigura că software-ul este de înaltă calitate, bine proiectat, robust și fără erori, fără a intra în uzabilitate.
- validarea se face pentru a asigura utilizarea software-ului și capacitatea de a satisface nevoile clientului.
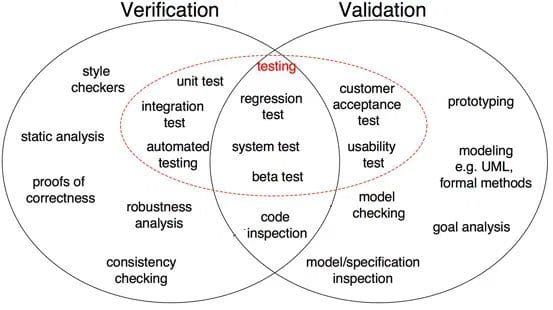
Fig 1: Diferențe între verificare și validare în dezvoltarea de software (Sursă)
după cum se arată în Fig 1, dovada corectitudinii, analiza robusteții, testele unitare, testul de integrare și altele sunt toate etapele de verificare în care sarcinile sunt orientate pentru a verifica specificul. Ieșirea Software este verificată în raport cu ieșirea dorită. Pe de altă parte, inspecția modelului, testarea cutiei negre, testarea utilizabilității sunt toate etapele de validare în care sarcinile sunt orientate pentru a înțelege dacă software-ul îndeplinește cerințele și așteptările.
diferența dintre verificarea datelor și validarea datelor din perspectiva învățării automate
rolul verificării datelor în conducta de învățare automată este cel al unui gatekeeper. Acesta asigură date exacte și actualizate în timp. Verificarea datelor se face în principal în noua etapă de achiziție a datelor, adică la Pasul 8 al conductei ML, așa cum se arată în Fig. 2. Exemple ale acestui pas sunt identificarea înregistrărilor duplicate și efectuarea deduplicării și curățarea nepotrivirii informațiilor despre clienți în câmp, cum ar fi adresa sau numărul de telefon.
pe de altă parte, validarea datelor (la Pasul 3 al conductei ML) asigură că datele incrementale de la Pasul 8 care sunt adăugate la datele de învățare sunt de bună calitate și similare (din perspectiva proprietăților statistice) cu datele de formare existente. De exemplu, aceasta include găsirea anomaliilor de date sau detectarea diferențelor dintre datele de formare existente și datele noi care trebuie adăugate la datele de formare. În caz contrar, orice problemă de calitate a datelor/diferențe statistice în datele incrementale pot fi ratate, iar erorile de instruire se pot acumula în timp și pot deteriora precizia modelului. Astfel, validarea datelor detectează modificări semnificative (dacă există) în datele de antrenament incremental într-un stadiu incipient care ajută la analiza cauzei rădăcină.
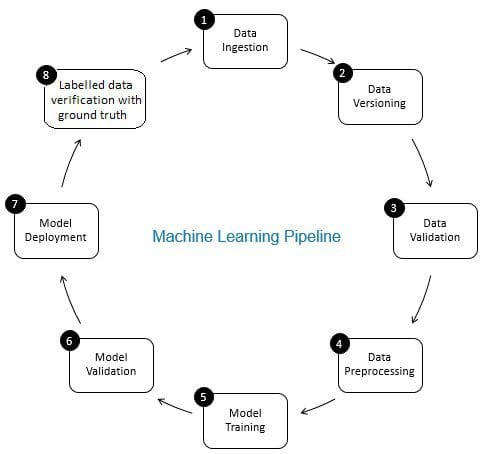
Fig 2: componente ale conductei de învățare automată
Aditya Aggarwal servește ca plumb știință-practică a datelor la Abzooba Inc. Cu peste 12 ani de experiență în conducerea obiectivelor de afaceri prin soluții bazate pe date, Aditya este specializată în analiză predictivă, învățare automată, business intelligence & strategie de afaceri într-o serie de industrii.
Dr. Arnab Bose este Chief Scientific Officer la Abzooba, o companie de analiză a datelor și o facultate adjunctă la Universitatea din Chicago, unde predă învățare automată și analiză predictivă, operațiuni de învățare automată, analiză și prognoză a seriilor de timp și analize de sănătate în programul Master Of Science în Analytics. El este un veteran al industriei de analiză predictivă de 20 de ani, care se bucură de utilizarea datelor nestructurate și structurate pentru a prognoza și influența rezultatele comportamentale în domeniul sănătății, comerțului cu amănuntul, finanțelor și transporturilor. Domeniile sale de interes actuale includ stratificarea riscurilor pentru sănătate și gestionarea bolilor cronice folosind învățarea automată și implementarea producției și monitorizarea modelelor de învățare automată.
legate de:
- MLOps – ” de ce este necesar?”și” ce este”?
- modelul meu de învățare automată nu învață. Ce ar trebui să fac?
- Observabilitatea datelor, partea a II-a: cum să vă construiți propriile monitoare de calitate a Datelor folosind SQL
Leave a Reply