datavalidering och dataverifiering – från ordbok till maskininlärning
av Aditya Aggarwal, Advanced Analytics Practice Lead och Arnab Bose, Chief Scientific Officer, Abzooba
ganska ofta använder vi dataverifiering och datavalidering omväxlande när vi pratar om datakvalitet. Dessa två termer är dock distinkta. I den här artikeln kommer vi att förstå skillnaden i 4 olika sammanhang:
- ordbokens betydelse för verifiering och validering
- skillnad mellan dataverifiering och datavalidering i allmänhet
- skillnad mellan verifiering och validering från mjukvaruutvecklingsperspektiv
- skillnad mellan dataverifiering och datavalidering från maskininlärningsperspektiv
ordbokens betydelse för verifiering och validering
tabell 1 förklarar ordbokens betydelse av orden verifiering och validering med några exempel.

Sammanfattningsvis handlar verifiering om sanning och noggrannhet, medan validering handlar om att stödja styrkan i en synvinkel eller korrektheten i ett krav. Validering kontrollerar riktigheten av en metod medan kontrollen kontrollerar riktigheten av resultaten.
skillnad mellan dataverifiering och datavalidering i allmänhet
nu när vi förstår den bokstavliga betydelsen av de två orden, Låt oss undersöka skillnaden mellan “dataverifiering” och “datavalidering”.
- dataverifiering: för att säkerställa att uppgifterna är korrekta.
- datavalidering: för att säkerställa att uppgifterna är korrekta.
Låt oss utarbeta exempel i Tabell 2.

skillnad mellan verifiering och validering ur mjukvaruutvecklingsperspektiv
ur ett mjukvaruutvecklingsperspektiv,
- verifiering görs för att säkerställa att programvaran är av hög kvalitet, välkonstruerad, robust och felfri utan att komma in i användbarheten.
- validering görs för att säkerställa programvarans användbarhet och kapacitet att uppfylla kundens behov.
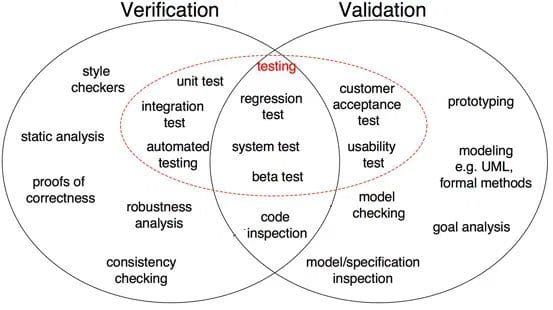
Fig 1: Skillnader mellan verifiering och validering i mjukvaruutveckling (källa)
som visas i Fig 1, bevis på korrekthet, robusthetsanalys, enhetstester, integrationstest och andra är alla verifieringssteg där uppgifter är inriktade på att verifiera detaljer. Programvaruutgången verifieras mot önskad utgång. Å andra sidan är modellinspektion, black box-testning, användbarhetstestning alla valideringssteg där uppgifter är inriktade på att förstå om programvara uppfyller kraven och förväntningarna.
skillnad mellan dataverifiering och datavalidering från maskininlärningsperspektiv
rollen för dataverifiering i maskininlärningspipeline är en gatekeeper. Det säkerställer korrekt och uppdaterad data över tiden. Dataverifiering görs främst vid det nya datainsamlingsstadiet, dvs vid steg 8 I ML-rörledningen, som visas i Fig. 2. Exempel på detta steg är att identifiera dubbla poster och utföra deduplicering, och att rensa obalans i kundinformation i fält som adress eller telefonnummer.
å andra sidan säkerställer datavalidering (i steg 3 I ML-rörledningen) att de inkrementella data från steg 8 som läggs till inlärningsdata är av god kvalitet och liknande (från statistiska egenskaper perspektiv) till befintliga träningsdata. Detta inkluderar till exempel att hitta dataavvikelser eller upptäcka skillnader mellan befintliga träningsdata och nya data som ska läggas till träningsdata. Annars kan eventuella datakvalitetsproblem/statistiska skillnader i inkrementella data missas och träningsfel kan ackumuleras över tiden och försämra modellens noggrannhet. Således upptäcker datavalidering signifikanta förändringar (om några) i inkrementell träningsdata i ett tidigt skede som hjälper till med grundorsaksanalys.
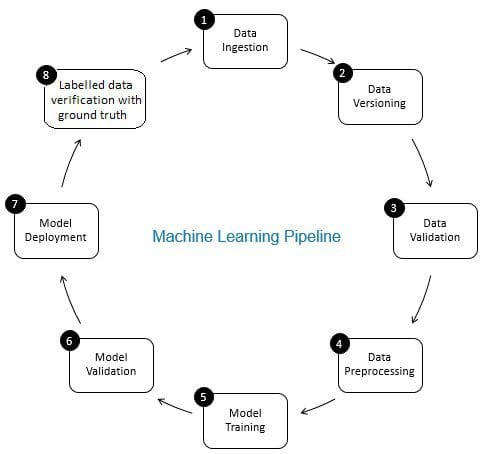
Fig 2: komponenter i Maskininlärningsrörledning
Aditya Aggarwal fungerar som Data Science – Practice Lead på Abzooba Inc. Med mer än 12+ års erfarenhet av att driva affärsmål genom datadrivna lösningar specialiserar Aditya sig på prediktiv analys, maskininlärning, business intelligence & affärsstrategi inom en rad branscher.
Dr. Arnab Bose är Chief Scientific Officer vid Abzooba, ett dataanalysföretag och en adjungerad fakultet vid University of Chicago där han undervisar maskininlärning och prediktiv analys, Maskininlärningsoperationer, tidsserieanalys och prognoser och hälsoanalys i Master of Science i Analytics-programmet. Han är en 20-årig prediktiv analysindustriveteran som tycker om att använda ostrukturerade och strukturerade data för att förutse och påverka beteendemässiga resultat inom hälso-och sjukvård, detaljhandel, Ekonomi och transport. Hans nuvarande fokusområden inkluderar hälsoriskstratifiering och kronisk sjukdomshantering med hjälp av maskininlärning och produktionsinstallation och övervakning av maskininlärningsmodeller.
relaterat:
- MLOps – ” varför krävs det?”och” vad är det”?
- min maskininlärningsmodell lär sig inte. Vad ska jag göra?
- Dataobservabilitet, del II: hur man bygger egna Datakvalitetsmonitorer med SQL
Leave a Reply