hur jag skriver mina Dataanalysbloggar av Kathleen E. ‘ 23
min kära vän och kollega bloggare Kidist A. ’22 begärde jag skriver ett inlägg för att beskriva hur jag går om att skriva mina dataanalysbloggar. Så, här går! Jag har beskrivit mina allmänna steg och länkat till mina gamla inlägg för att ge exempel på vad jag pratar om.
identifiera en fråga

jag börjar med att fråga mig följande:
- vilken historia vill jag berätta?
- Hur hjälper dataanalys att berätta den historien?
om jag sitter fast försöker jag tänka på mitt liv och världen runt mig. Finns det några mönster jag skulle vilja undersöka eller fenomen som jag skulle vilja kvantifiera?
här är några saker jag har frågat mig tidigare:
- Hur ser mina arbetsmönster ut? Förvirring, med siffrorna
- hur är det att klättra en 20-våningshus 22 gånger? Green Building Challenge
- Hur känner MIT-studenter om våra sovsalars nya tvättsystem? Washlava! En sentimentanalys
därefter frågar jag mig vilken typ av data som skulle vara till hjälp för att svara på din fråga. Detta leder oss till nästa steg:
samla in några data
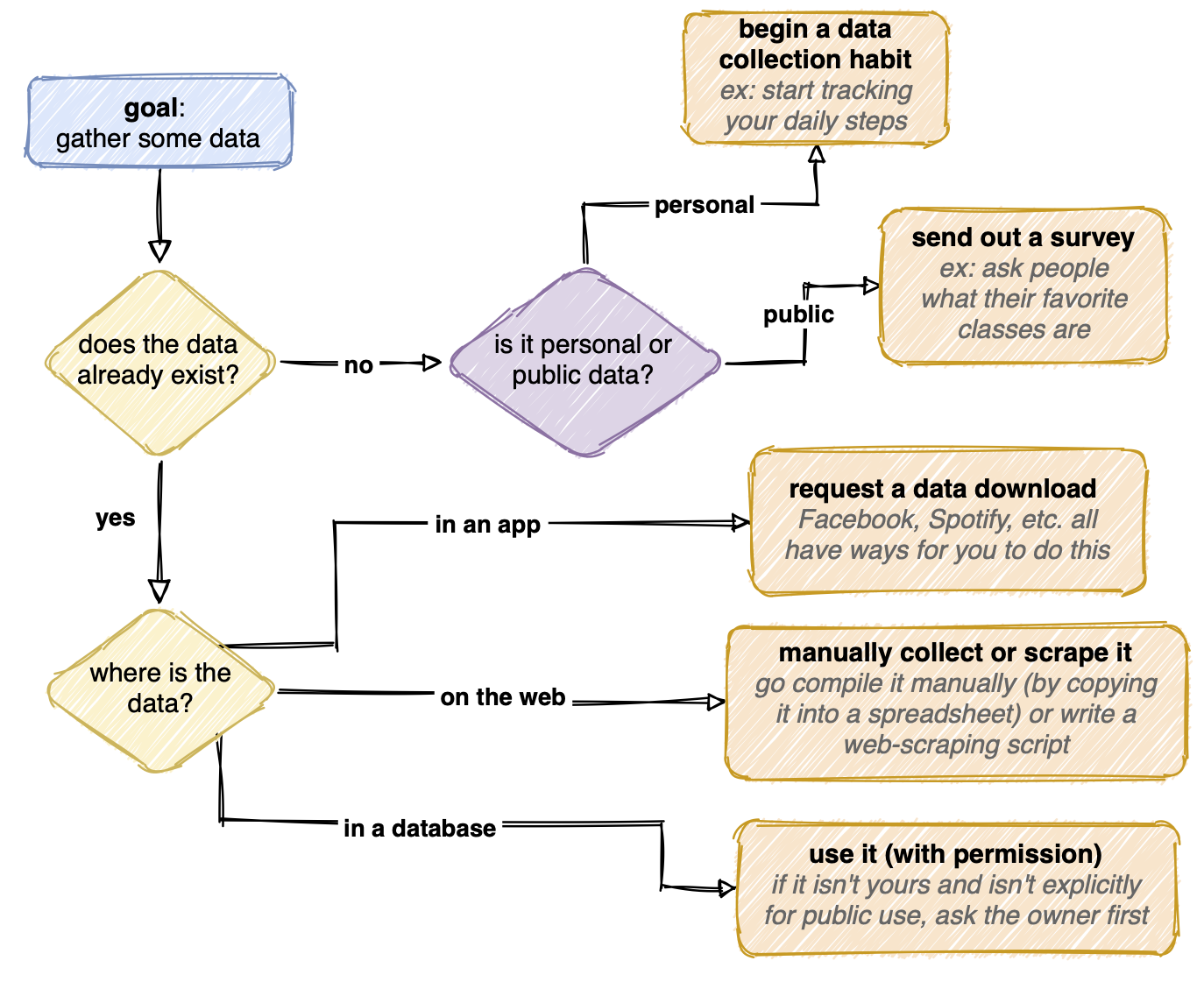
att samla in data kan vara enkelt eller ganska tråkigt. Data kan redan finnas, snyggt sammanställd i en databas. Om databasen är Offentlig är jag klar med det här steget! Om det är privat skickar jag i allmänhet en begäran till ägaren att använda den. Om data finns i en app som Facebook letar jag efter sätt genom vilka jag kan begära en datahämtning. Uppgifterna kan också existera någonstans lite mer obekvämt (spridda på webben, till exempel) och jag måste samla in den.
om data inte finns ännu kan jag börja skapa den. Om frågan jag försöker svara är mer personlig kan jag börja spåra något i mitt liv, antingen automatiskt (som med en stegräkning) eller manuellt (som att spela in vad Netflix visar jag tittar på varje natt). Eller om uppgifterna handlar om andra människor kan jag göra ett experiment eller skicka ut en undersökning.
här är ett flödesschema jag gjorde som sammanfattar hur jag kan gå om att få data:
rengör data

data sällan kommer redo att analysera. För att få det klart måste jag “städa” det.
vad betyder det för att data inte är redo att analysera? Kanske finns det mycket data som inte relaterar till min fråga. Kanske är uppgifterna representerade på ett riktigt oorganiserat eller inkonsekvent sätt. Rengöring kan innebära att extrahera den relevanta delmängden av data, organisera den och ändra hur den representeras för att göra en enklare analys.
till exempel i dormspam-The-game (Del 1) data bestod av en lista över platser där varje spelare (i en virtuell omgång kurragömma) valde att kurragömma. Det fanns dock några poster i databasen som felstavades, vilket orsakade fel i min kod när den försökte iterera över en lista över platser. Jag var tvungen att ersätta dessa poster med korrekt stavade versioner av platsen.
gör lite dataanalys!
Jag använder vanligtvis Python för att skriva skript för att analysera och visualisera mina data. Jag har lagt en del av min kod offentligt på Github, så du kan titta på den. Python är dock inte det enda alternativet. Du kan också använda en mängd andra skriptspråk som har bra analys-och visualiseringsverktyg. Du kan också gå utan kod och använda kalkylarkfunktioner. Med det sagt, här är hur jag arbetar med Python:
- jag gillar att använda Jupyter bärbara datorer (eller Google Colab bärbara datorer). Jag gillar dessa bättre än en rå textfil eftersom de tillåter markdown-anteckningar/dokumentation och visualiseringar att existera tillsammans med din kod ganska snyggt. Om jag planerar mina analyser, lär mig att använda ett nytt verktyg eller referera till ett tidigare resultat, är det trevligt att jag bara kan bläddra runt för att titta på anteckningar/utdata/tomter i min anteckningsbok istället för någon extern referens.
- jag är starkt beroende av paket. Jag importerar nästan alltid pandor, Numpy och Matplotlib för att hantera och organisera mina data, göra grundläggande statistiska och matematiska operationer och göra grundläggande visualiseringar. På projekt-för-projekt-basis importerar jag också ytterligare paket för att komma åt speciella modeller och visualiseringar som kan vara relevanta.
- jag börjar med att ladda upp mina data. Jag kan ladda den lokalt från en fil på min dator. Eller, oftare, vad jag gör är att ladda upp det till Google Sheets, använd funktionen “publicera på webben” för att skapa en länk till en CSV och använd sedan den länken för att ladda mina data. Jag föredrar att använda google sheets över en lokal fil eftersom den har trevligare versionshistorik och samarbetsfunktioner.
- därefter engagerar jag mig i en iterativ process där jag antar om en trend i data, gör en analys för att undersöka hypotesen och sedan använda resultaten för att generera fler hypoteser. Med riktigt intressanta eller udda data kan denna process fortsätta ganska länge.
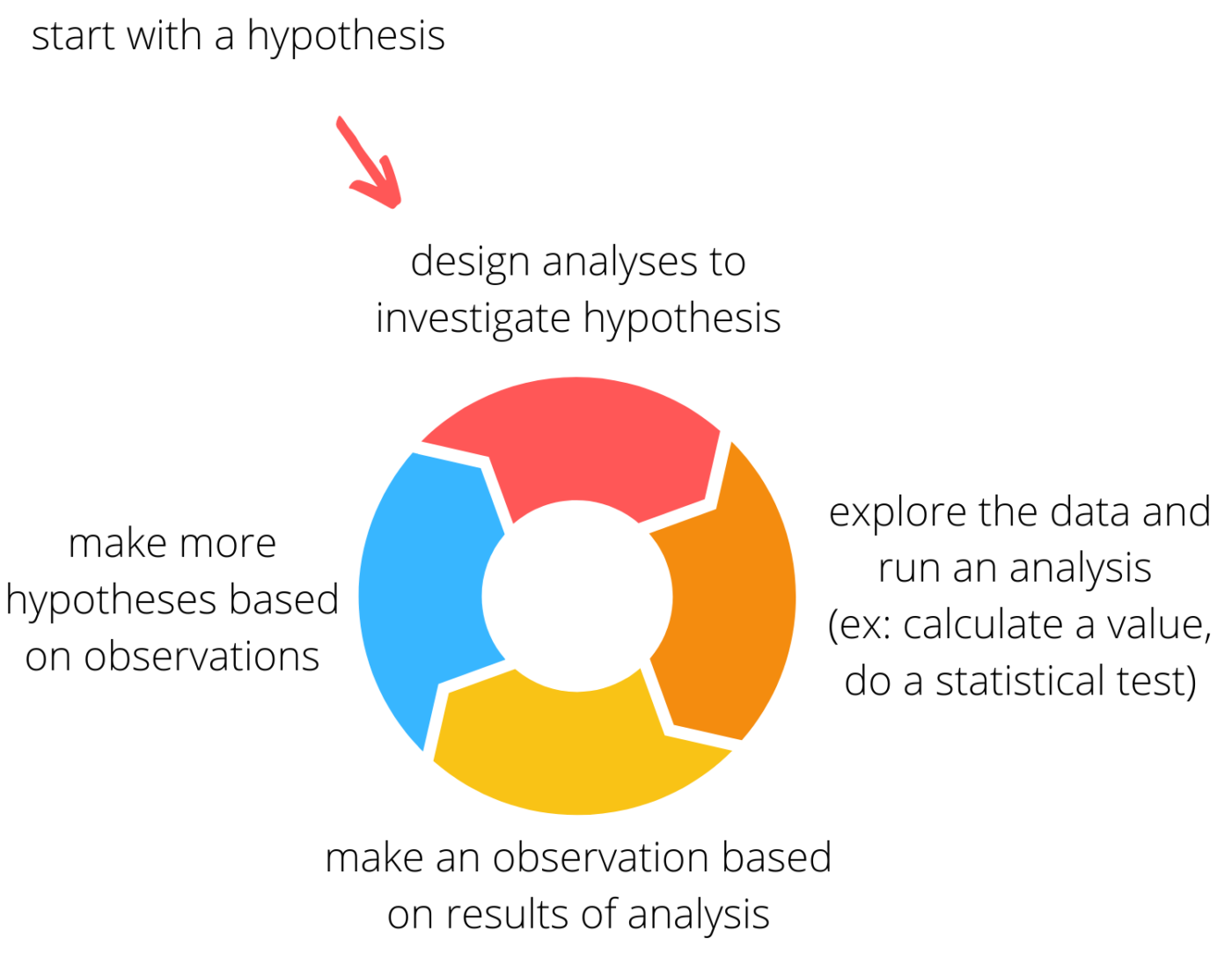
gör några tomter
när jag analyserar data är ett användbart sätt att upptäcka coola mönster att göra visualiseringar. Jag kan göra detta med en mängd olika grafer. Min första plot är ofta ganska ful. Jag kan använda olika funktioner i mitt plottbibliotek för att göra det bättre att lyfta fram data, både vetenskapligt och estetiskt. Till exempel kan jag justera färger och storlek på datapunkter, linjer och staplar för att bättre visa trender. Jag kan ändra hur x-och y-axeln representeras för att göra plottet renare.
bortsett från att göra statiska tomter, gillar jag ibland att animera tomter (se Green Building Challenge och dormspam-The-game (Del 1)). Att skapa tomter är en kreativ process, särskilt när man skapar animerade där funktioner som färg och storlek kan tjäna ett annat syfte än vad de kan göra i en statisk tomt.
att göra visualiseringar är min favorit del av processen. Jag älskar att låta mina konstnärliga och tekniska sidor komma ihop.
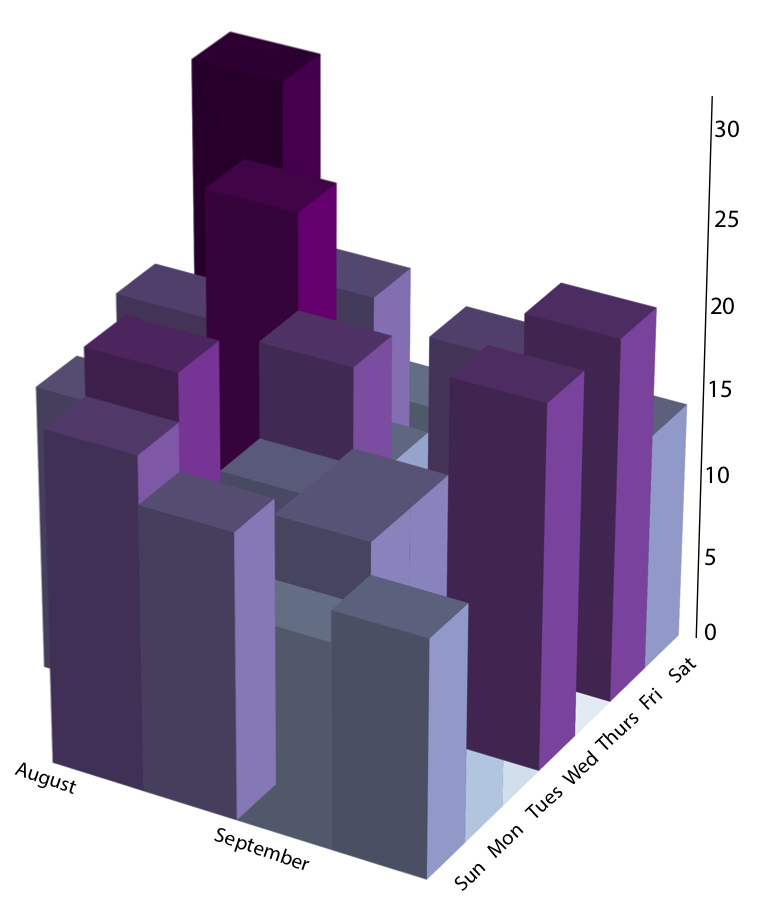
en plot från mitt första blogginlägg som visar antalet steg jag tog i tusentals under mina första veckor på MIT
berätta en historia
det är viktigt att tänka på hur min dataanalys och visualiseringar kan bidra till att berätta en historia om den trend jag undersöker eller fenomen jag kvantifierar. Jag försöker göra tomter på ett sätt som gör att varje plot kan visa en ny del av berättelsen. Jag försöker beställa dem mina tomter mina inlägg på ett sätt som varje mina ord och mina tomter tillsammans successivt berätta en historia om vad som händer. När jag till exempel har visualiserat data från ett spel kan jag först beskriva spelreglerna, sedan beskriva vem som vann och sedan dyka in i att förstå hur olika spelarstrategier påverkade resultatet.
så det är ganska mycket hur jag skriver mina dataanalysbloggar. Jag separerade den i 6 steg, men att tänka “bakåt” snarare än strikt steg för steg kan hjälpa till att göra ditt arbete i tidigare steg mer meningsfullt. Om du funderar på hur du gör historien övertygande kan du göra bättre visualiseringar. Om du vet vilka visualiseringar du kanske vill göra kan du bättre styra din datainsamling.
Leave a Reply