lexikal analys i kompilator
lexikal analys i kompilator är det första steget i analysen av källprogrammet. Den lexikala analysen läser inmatningsströmmen från källprogrammet tecken för tecken och producerar sekvensen av tokens. Dessa tokens tillhandahålls som en ingång till parsern för parsing. I detta sammanhang kommer vi att diskutera processen med lexikal analys i korthet tillsammans med lexikala fel och deras återhämtning.
innehåll: Lexikal analys i kompilator
- terminologier i lexikal analys
- Vad är lexikal analys?
- exempel på lexikal analys
- Roll lexikal analysator
- lexikal fel
- felåterställning
- viktiga Takeaways
terminologier i lexikal analys
innan vi går in i vilken lexikal analys är hur det utförs låt oss prata om några terminologier som vi kommer att stöta på när vi diskuterar lexikal analys.
- Lexeme
Lexeme kan definieras som en sekvens av tecken som bildar ett mönster och kan identifieras som en token. - mönster
efter att ha identifierat lexemmönstret kan man beskriva vilken typ av token som kan bildas. Såsom mönstret för vissa lexeme bildar ett nyckelord, mönstret för vissa lexemes bildar en identifierare. - Token
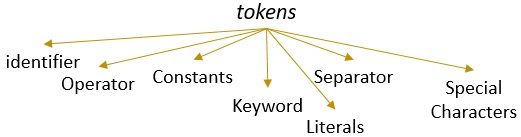
ett lexeme med ett giltigt mönster bildar en token. I lexikal analys kan en giltig token vara identifierare, nyckelord, separatorer, specialtecken, konstanter och operatörer.
Vad är lexisk analys?
tidigare har vi avstått från lexical analyzer i vår innehållskompilator i datorn. Vi har lärt oss att kompilatorn utför analysen av källprogrammet genom olika faser för att omvandla det till målprogrammet. Den lexikala analysen är den första fasen som källprogrammet måste gå igenom.
den lexikala analysen är processen för tokenisering d. v. s. den läser inmatningssträngen för ett källprogram tecken för tecken och så snart det identifierar ett slut på lexemet identifierar det sitt mönster och omvandlar det till ett token.
den lexikala analysatorn består av två på varandra följande processer som inkluderar skanning och lexikal analys.
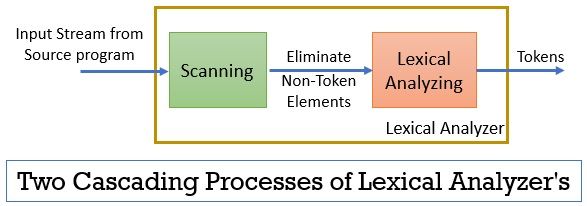
- skanning: skanningsfasen-eliminerar bara de icke-token-elementen från källprogrammet. Såsom att eliminera kommentarer, komprimera de på varandra följande vita utrymmena etc.
- Lexikal Analys: Lexikal analysfas utför tokeniseringen på utgången som tillhandahålls av skannern och producerar därmed tokens.
programmet som används för att utföra lexikal analys kallas lexer eller lexical analyzer. Låt oss nu ta ett exempel på lexisk analys utförd på ett uttalande:
exempel 1 av lexikal analys:
lexikal analys i kompilatordesign, identifiera tokens.
nu, när vi kommer att läsa detta uttalande kan vi lätt identifiera att det finns nio tokens i ovanstående uttalande.
- identifierare – > lexikala
- identifierare – > analys
- identifierare – > i
- identifierare – > kompilator
- identifierare – > design
- Separator -> ,
- identifierare – > identifiera
- identifierare -> tokens
- Separator -> .
så som totalt finns det 9 tokens i ovanstående ström av tecken.
exempel 2 av lexikal analys:
printf(” värdet av i är %d “, i);
låt oss nu försöka hitta tokens ur denna Ingångsström.
- nyckelord – > printf
- specialtecken -> (
- Literal – > “värdet av i är % d”
- Separator -> ,
- identifierare – > i
- specialtecken -> )
- Separator -> ;
notera:
- hela strängen inuti de dubbla inverterade kommatecken, dvs “” anses vara en enda token.
- det tomma vita utrymmet som skiljer tecknen i inmatningsströmmen skiljer bara tokens och därmed elimineras det medan man räknar tokens.
Roll Lexical Analyzer
att vara den första fasen i analysen av källprogrammet lexical analyzer spelar en viktig roll i omvandlingen av källprogrammet till målprogrammet.
hela detta scenario kan realiseras med hjälp av figuren nedan:
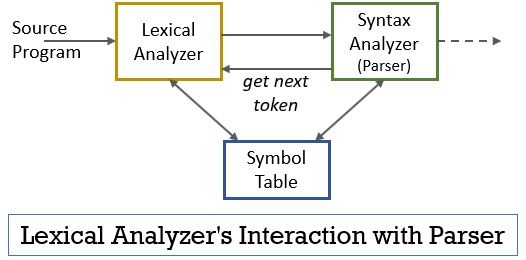
- den lexikala analysatorfasen har skannern eller lexer-programmet implementerat i det som endast producerar tokens när de beordras av tolkaren att göra det.
- tolkaren genererar kommandot getNextToken och skickar det till lexical analyzer som ett svar på detta den lexikala analysatorn börjar läsa inmatningsströmmen tecken för tecken tills den identifierar ett lexeme som kan identifieras som en token.
- så snart en token produceras den lexikala analysatorn skickar den till syntax analyzer för tolkning.
- tillsammans med syntaxanalysatorn kommunicerar den lexikala analysatorn också med symboltabellen. När en lexikal analysator identifierar ett lexeme som en identifierare går det in i lexemet i symboltabellen.
- ibland hjälper informationen om identifieraren i symboltabellen lexical analyzer vid bestämning av token som måste skickas till parsern.
- förutom att identifiera tokens i ingångsströmmen eliminerar lexical analyzer också det tomma utrymmet / det vita utrymmet och programmets kommentarer. Sådana andra saker inkluderar tecken de separerar tokens, flikar, tomma utrymmen, nya linjer.
- den lexikala analysatorn hjälper till att relatera felmeddelandena som produceras av kompilatorn. Bara, till exempel, den lexikala analysatorn håller rekordet för varje ny radtecken som den stöter på när du skannar källprogrammet så att det enkelt relaterar felmeddelandet med källprogrammets radnummer.
- om källprogrammet använder makron expanderar lexical analyzer makron i källprogrammet.
lexikalt fel
den lexikala analysatorn i sig är inte effektiv för att bestämma felet från källprogrammet. Tänk till exempel på ett uttalande:
prtf (“värdet av i är %d”, i);
nu, i ovanstående uttalande när strängen prtf påträffas den lexikala analysatorn inte kan gissa om prtf är en felaktig stavning av nyckelordet ‘printf’ eller det är en odeklarerad funktionsidentifierare.
men enligt den fördefinierade regeln är prtf ett giltigt lexeme vars mönster avslutar att det är en identifieringstoken. Nu kommer den lexikala analysatorn att skicka prtf-token till nästa fas, dvs parser som hanterar felet som uppstod på grund av införlivandet av bokstäver.
felåterställning
Tja, ibland är det till och med omöjligt för en lexikal analysator att identifiera ett lexem som ett token, eftersom lexemmönstret inte matchar något av de fördefinierade mönstren för tokens. I det här fallet måste vi tillämpa vissa felåterställningsstrategier.
- i paniklägeåterställning raderas det successiva tecknet från lexemet tills den lexikala analysatorn identifierar en giltig token.
- ta bort det första tecknet från den återstående inmatningen.
- identifiera det eventuella saknade tecknet och sätt in det i den återstående inmatningen på lämpligt sätt.
- ersätt ett tecken i den återstående inmatningen för att få en giltig token.
- Byt ut positionen för två intilliggande tecken i den återstående inmatningen.
när du utför ovanstående felåterställningsåtgärder, kontrollera om prefixet för den återstående ingången matchar något mönster av tokens. I allmänhet uppstår ett lexiskt fel på grund av ett enda tecken. Så, du kan korrigera det lexiska felet med en enda transformation. Och så långt som möjligt måste ett mindre antal transformationer konvertera källprogrammet till en sekvens av giltiga tokens som det kan överlämna till parsern.
viktiga Takeaways
- lexikal analys är den första fasen i analysen av källprogrammet i kompilatorn.
- den lexikala analysatorn implementeras av två på varandra följande processer scanner och lexikal analys.
- Scanner eliminerar icke-token element från ingångsströmmen.
- lexikal analys utför tokenisering.
- således genererar den lexiska analysatorn en sekvens av tokens och vidarebefordrar dem till parsern.
- parsern på att ha en token från den lexikala analysatorn gör ett samtal getNextToken som insisterar den lexikala analysatorn läsa inmatningsströmmen av tecken tills den identifierar nästa token.
- om den lexikala analysatorn identifierar mönstret för ett lexeme som en identifierare, skriver den lexikala analysatorn det lexemet i symboltabellen för framtida användning.
- Lexical analyzer är inte effektivt för att identifiera eventuella fel i källprogrammet ensam.
- om det uppstår ett lexeme vars mönster inte matchar något av de fördefinierade mönstren för tokens måste du utföra felåterställningsåtgärder för att åtgärda felet.
så det handlar om den lexikala analysen som förvandlar strömmen av tecken till tokens och skickar den till parsern. Vi har lärt oss om arbetet med lexisk analys med hjälp av ett exempel. Vi har avslutat diskussionen med lexical error och dess återhämtningsstrategi.
Leave a Reply