Tablas de Enrutamiento
Una tabla de enrutamiento es una agrupación de información almacenada en un equipo en red o enrutador de red que incluye una lista de rutas a varios destinos de red. Los datos se almacenan normalmente en una tabla de base de datos y en configuraciones más avanzadas incluye métricas de rendimiento asociadas con las rutas almacenadas en la tabla. La información adicional almacenada en la tabla incluirá la topología de red más cercana al enrutador. Aunque una tabla de enrutamiento se actualiza de forma rutinaria mediante protocolos de enrutamiento de red, las entradas estáticas se pueden realizar a través de acciones manuales por parte de un administrador de red.
¿Cómo Funciona una Tabla de Enrutamiento?
Las tablas de enrutamiento funcionan de forma similar a la forma en que la oficina de correos entrega el correo. Cuando un nodo de red en Internet o una red local necesita enviar información a otro nodo, primero requiere una idea general de dónde enviar la información. Si el nodo o la dirección de destino no están conectados directamente al nodo de red, la información debe enviarse a través de otros nodos de red. Para ahorrar recursos, la mayoría de los nodos de red de área local no mantendrán una tabla de enrutamiento compleja. En su lugar, enviarán paquetes IP de información a una puerta de enlace de red local. La puerta de enlace mantiene la tabla de enrutamiento principal de la red y enviará el paquete de datos a la ubicación deseada. Para mantener un registro de cómo enrutar la información, la puerta de enlace utilizará una tabla de enrutamiento que realiza un seguimiento del destino apropiado para los paquetes de datos salientes.
Todas las tablas de enrutamiento mantienen listas de tablas de enrutamiento para los destinos accesibles desde la ubicación del enrutador. Esto incluye la dirección del siguiente dispositivo en red en la ruta de red a la dirección de destino, que también se denomina “siguiente salto”.”Al mantener información precisa y consistente con respecto a los nodos de red, enviar un paquete de datos a lo largo de la ruta más corta a la dirección de destino en Internet normalmente es suficiente para entregar tráfico de red y es una de las características de referencia de la teoría de redes de capas de redes OSI e IP.
¿Cuál es la Función Principal de un Router de red?
La función principal de un enrutador de red es reenviar paquetes de datos a la red de destino incluida en la dirección IP de destino del paquete de datos saliente. Para determinar el destino apropiado del paquete de datos, el enrutador realiza una búsqueda de las direcciones de destino almacenadas en la tabla de enrutamiento La tabla de enrutamiento se almacena en RAM en el enrutador de puerta de enlace de la red e incluye información sobre las redes de destino y las asociaciones de “siguiente salto” para esas direcciones. Esta información ayuda al enrutador a determinar e identificar la mejor ubicación de salida para el paquete de datos que se enviará para encontrar el destino de red definitivo. Esta ubicación también puede ser la interfaz de puerta de enlace de cualquier red conectada directamente.
¿Qué es una Red Conectada directamente?
Las redes conectadas directamente se conectan a una de las interfaces de enrutador de una red local. Dado que la interfaz del enrutador se configura normalmente con una máscara de subred y una dirección IP, la interfaz también se considera un host de red en la red conectada. Como resultado, tanto la máscara de subred como la dirección de red de la interfaz se ingresan en la tabla de enrutamiento almacenada localmente (junto con el tipo y el número de interfaz). La entrada se realiza como una red conectada. Un ejemplo común de una red conectada directamente son los servidores web que se encuentran en la misma red que el host de la computadora y constituyen una red conectada directamente en la tabla de enrutamiento almacenada en la puerta de enlace o enrutador.
¿Qué es una Red Remota?
Las redes remotas no están conectadas directamente a la puerta de enlace o al enrutador de la red. En lo que respecta a una tabla de enrutamiento, solo se puede llegar a una red remota reenviando paquetes de datos a otros enrutadores. Estas redes se agregan a la tabla de enrutamiento local a través de la configuración de rutas de red estáticas o mediante el uso de un protocolo de enrutamiento dinámico. Las rutas dinámicas son “aprendidas” por el enrutador mediante el seguimiento de los medios más eficientes de entrega de paquetes de datos haciendo uso de un protocolo de enrutamiento dinámico. Por lo general, los administradores de red serán las únicas personas autorizadas para configurar manualmente rutas estáticas a destinos de red remotos.
¿Cuáles son algunos problemas con las Tablas de Enrutamiento?
Uno de los desafíos más importantes con las tablas de enrutamiento modernas es la gran cantidad de almacenamiento necesario para almacenar la información necesaria para conectar un gran número de dispositivos informáticos en red en un almacenamiento limitado en el enrutador. La tecnología actual utilizada en la mayoría de los enrutadores de red para la agregación de direcciones es la tecnología de enrutamiento entre dominios de Clase (CIDR). CIDR hace uso de un esquema de coincidencia de prefijos en bits. Este esquema se basa en el hecho de que cada nota en una red tendrá una tabla de enrutamiento válida que es consistente y evitará bucles. Desafortunadamente, en el modelo de enrutamiento “Hop/Hop” actualmente empleado, las tablas no son consistentes y se desarrollan bucles. Esto hace que los paquetes de datos se encuentren en un lop interminable y ha sido un problema importante para el enrutamiento de la red durante años.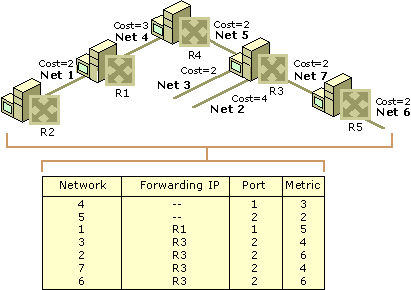
¿Cuál es el contenido de una tabla de enrutamiento?
Aunque cada tabla de enrutamiento de red puede contener información diferente, los campos principales de cada tabla incluyen: el ID de red, coste o métrica, y el siguiente salto.
ID de red: Este campo en una tabla de enrutamiento incluirá la subred de dirección de destino.
Costo o métrica: Este campo guardará la métrica o el” costo ” de la ruta de red a la que se enviará el paquete de datos saliente.
Salto siguiente: La puerta de enlace o salto siguiente es la dirección de destino de la siguiente ubicación de red a la que se transmitirán los paquetes de datos en su camino a la dirección IP de destino.
La información adicional que se puede encontrar en una tabla de enrutamiento de red incluye:
Calidad del servicio de la ruta de red: Con el tiempo, algunos enrutadores de red están diseñados para almacenar una métrica de calidad de servicio asociada con diferentes rutas de red almacenadas en tablas de enrutamiento. Una de estas métricas simplemente indica que una ruta determinada está operativa y establece un indicador en la tabla para ahorrar memoria.
Criterios de filtrado o Listas de acceso: Esta entrada contiene información o enlaces a información que tiene la información más reciente sobre listas de acceso o varios criterios de filtrado que pueden estar asociados con una ruta de red determinada.
Información de interfaz de red: Puede representar datos relativos a tarjetas Ethernet específicas u otra información que se puede utilizar para optimizar el enrutamiento de paquetes de datos de red.
¿Qué es una tabla de reenvío?
Normalmente se utiliza una tabla de reenvío de red o una base de información de reenvío (FIB) cuando se conectan redes o se realizan varias operaciones de enrutamiento para ayudar a localizar la interfaz correcta que una interfaz de entrada a la red debe enviar un paquete de datos.
Las aplicaciones de tablas de reenvío en la Capa de Enlace de datos
Las tablas de reenvío han encontrado algún uso en la capa de enlace de datos. Por ejemplo, los protocolos MAC (control de acceso a medios) en redes locales tienen una dirección que no es significativa fuera de este medio y se pueden almacenar para su uso en una tabla de reenvío para ayudar con el puente Ethernet. Otros usos incluyen conmutadores ATM (Modo de transferencia asíncrona), relés de marco y MPLS (conmutación de etiquetas multiprotocolo). Para su uso con ATM, hay direcciones locales de capa de enlace de datos y otras que tienen una buena cantidad de importancia para su uso en la red.
¿Cómo se usan las tablas de reenvío con el puente?
Cuando un puente de capas MAC identifica la interfaz en la que se vio por primera vez una dirección de origen, se establece la asociación con la interfaz y la dirección. Como resultado, cuando se recibe un marco en el puente una dirección de destino ubicada en la tabla de reenvío respectiva, el marco se transmitirá a la interfaz que se ha almacenado en la FIB. Si la dirección no se ha visto previamente, se tratará como una” transmisión ” y enviará la información a todas las interfaces activas, con la excepción de la que recibió la información.
¿Cómo funciona un Relé de Cuadro?
Aunque no hay un método o proceso definido centralmente que determine cómo funciona una tabla de reenvío o un relé de marco, el modelo típico que se encuentra en toda la industria es que un interruptor de relé de marco tendrá una tabla de reenvío definida estáticamente por interfaz. Una vez que se recibe un marco junto con un DLCI (identificador de conexión de enlace de datos) en una interfaz dada, la tabla asociada a la interfaz proporcionará la interfaz de salida. Esto también proporciona el nuevo DLCI para insertar en el campo de dirección de fotograma de la tabla.
¿Cómo Funcionan Las Mesas de Reenvío de Cajeros Automáticos?
Un conmutador ATM contiene una tabla de reenvío a nivel de enlace similar al modelo utilizado en una tabla de retransmisión de cuadros. En lugar de usar DLCI; sin embargo, la interfaz incluye tablas de reenvío que incluyen el identificador de ruta virtual, la interfaz de salida y el identificador de circuito virtual. La tabla puede distribuirse mediante el protocolo PNNI (interfaz de red privada a red) o definirse estáticamente. Cuando PNNI crea la tabla, los conmutadores ATM que se encuentran en el borde de la red o la nube mapearán los identificadores de extremo a extremo de la red para identificar el siguiente salto VCI o VPI.
¿Qué es el Cambio de etiquetas Multiprotocolo (MPLS)?
La conmutación de etiquetas Multiprotocolo (MPLS) tiene una serie de aspectos que son similares a los ATM. MPSL utiliza LER (enrutadores de borde de etiqueta) que se encuentran en los límites del mapa de nube MPSL ubicado entre una etiqueta local de enlace y el identificador de extremo a extremo (que puede ser una dirección IP). En cada salto en MPLS, se usa una tabla de reenvío para indicar al LSR qué interfaz de salida debe recibir el paquete. También determina qué etiqueta aplicar al reenviar el paquete a esa interfaz.
¿Cuáles son las Aplicaciones de las Tablas de Reenvío en la Capa de red?
A diferencia de las tablas de enrutamiento de red, una tabla de reenvío o FIB está optimizada para buscar información rápidamente en una dirección de destino. Las versiones anteriores de tablas de reenvío almacenaban en caché un subconjunto del número total de enrutadores que se usaban con mayor frecuencia para reenviar paquetes de datos. Aunque esta metodología funcionó para el enrutamiento a nivel empresarial, cuando se empleó para el acceso a toda Internet, se produjeron importantes impactos de rendimiento al tener que actualizar constantemente la caché relativamente pequeña. Como resultado, las implementaciones de tablas de reenvío comenzaron a cambiar la metodología para garantizar que un FIB tuviera una RIB correspondiente que se optimizaría y actualizaría con un conjunto completo de rutas que el enrutador de red había aprendido. Las mejoras adicionales realizadas a FIBs incluyen capacidades de búsqueda de hardware más rápidas y TCAM (memoria direccionable de contenido ternario). Debido al alto costo de TCAM, sin embargo, esta tecnología se encuentra normalmente en enrutadores edge.
¿Cómo ayudan las Tablas de Reenvío a Defenderse de los Ataques de Denegación de Servicio?
Con el tiempo, el uso de una tabla de reenvío (o FIB) para ayudar a filtrar paquetes de datos entrantes se ha convertido en una “práctica recomendada” de Internet para ayudar a defenderse contra ataques de Denegación de Servicio (DoS) en una red. En la forma más básica, el filtrado de ingresos utilizará una lista de acceso para determinar de quién soltar paquetes y mitigar el daño que un ataque DoS logrará. Si la red tiene un mayor número de redes adyacentes, el uso del método de lista de acceso puede convertirse rápidamente en un impacto en el rendimiento del enrutador. Otras implementaciones tendrán la dirección de búsqueda de la dirección de origen en la FIB. SI no hay una ruta guardada a la dirección de origen de la información, el algoritmo asume que el paquete proviene de una dirección de origen falsa o falsa y se descarta como posiblemente parte de un ataque DoS.
¿Cómo se utilizan las Tablas de Reenvío para Garantizar la Calidad del Servicio?
Las tablas FIB se pueden utilizar en una serie de esquemas de administración de red para ayudar a garantizar una mayor calidad de servicio para ciertos paquetes de datos en la red. Esta diferenciación puede basarse en un paquete de datos de campo int eh que indica la prioridad de enrutamiento del paquete además de cuánto tiempo desea el paquete permanecer “vivo” en caso de congestión de la red. Cuando los enrutadores admiten este tipo de servicio, normalmente se les requiere que envíen el paquete de datos a la interfaz de red que “mejor” coincida con los requisitos de servicio de los datos normalmente llamados DSCP (puntos de código de servicio diferenciado). Aunque este acto aumenta ligeramente la potencia informática general necesaria para procesar el paquete, no se considera que tenga un impacto significativo en los recursos de la red.
Leave a Reply