Validación de Datos y Verificación de Datos – Del Diccionario al Aprendizaje Automático
Por Aditya Aggarwal, Jefe de Práctica de Análisis Avanzado, y Arnab Bose, Director Científico de Abzooba
Con bastante frecuencia, usamos la verificación de datos y la validación de datos de forma intercambiable cuando hablamos de calidad de datos. Sin embargo, estos dos términos son distintos. En este artículo, entenderemos la diferencia en 4 contextos diferentes:
- Significado de verificación y validación en el diccionario
- Diferencia entre verificación de datos y validación de datos en general
- Diferencia entre verificación y validación desde la perspectiva del desarrollo de software
- Diferencia entre verificación de datos y validación de datos desde la perspectiva del aprendizaje automático
Significado de verificación y validación en el diccionario
La Tabla 1 explica el significado del diccionario de las palabras verificación y validación con algunos ejemplos.

En resumen, la verificación se trata de la verdad y la precisión, mientras que la validación se trata de apoyar la fortaleza de un punto de vista o la exactitud de una afirmación. La validación comprueba la exactitud de una metodología, mientras que la verificación comprueba la exactitud de los resultados.
Diferencia entre la verificación de datos y la validación de datos en general
Ahora que entendemos el significado literal de las dos palabras, exploremos la diferencia entre “verificación de datos” y “validación de datos”.Verificación de datos
- : para asegurarse de que los datos sean precisos.
- validación de Datos: para asegurarse de que los datos son correctos.
Desarrollemos con ejemplos en la Tabla 2.

Diferencia entre verificación y validación desde la perspectiva del desarrollo de software
Desde la perspectiva del desarrollo de software,
- La verificación se realiza para garantizar que el software sea de alta calidad, bien diseñado, robusto y libre de errores sin entrar en su facilidad de uso.
- La validación se realiza para garantizar la usabilidad del software y la capacidad para satisfacer las necesidades del cliente.
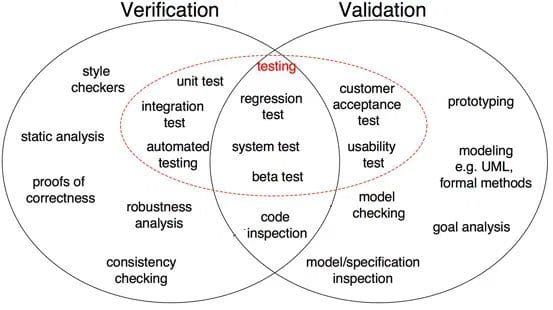
Fig 1: Diferencias entre Verificación y Validación en el desarrollo de software (Fuente)
Como se muestra en la Figura 1, la prueba de corrección, el análisis de robustez, las pruebas unitarias, la prueba de integración y otros son pasos de verificación en los que las tareas están orientadas a verificar detalles específicos. La salida de software se verifica contra la salida deseada. Por otro lado, la inspección de modelos, las pruebas de caja negra y las pruebas de usabilidad son pasos de validación en los que las tareas se orientan a comprender si el software cumple con los requisitos y expectativas.
Diferencia entre la verificación de datos y la validación de datos desde la perspectiva del aprendizaje automático
La función de la verificación de datos en la canalización de aprendizaje automático es la de un gatekeeper. Garantiza datos precisos y actualizados a lo largo del tiempo. La verificación de datos se realiza principalmente en la nueva etapa de adquisición de datos, es decir, en el paso 8 de la tubería de ML, como se muestra en la Fig. 2. Ejemplos de este paso son identificar registros duplicados y realizar deduplicaciones, y limpiar la falta de coincidencia en la información del cliente en el campo, como la dirección o el número de teléfono.
Por otro lado, la validación de datos (en el paso 3 de la tubería de aprendizaje automático) garantiza que los datos incrementales del paso 8 que se agregan a los datos de aprendizaje sean de buena calidad y similares (desde la perspectiva de las propiedades estadísticas) a los datos de entrenamiento existentes. Por ejemplo, esto incluye encontrar anomalías en los datos o detectar diferencias entre los datos de entrenamiento existentes y los nuevos datos que se agregarán a los datos de entrenamiento. De lo contrario, cualquier problema de calidad de los datos o diferencia estadística en los datos incrementales puede perderse y los errores de entrenamiento pueden acumularse con el tiempo y deteriorar la precisión del modelo. Por lo tanto, la validación de datos detecta cambios significativos (si los hay) en los datos de entrenamiento incrementales en una etapa temprana que ayuda con el análisis de la causa raíz.
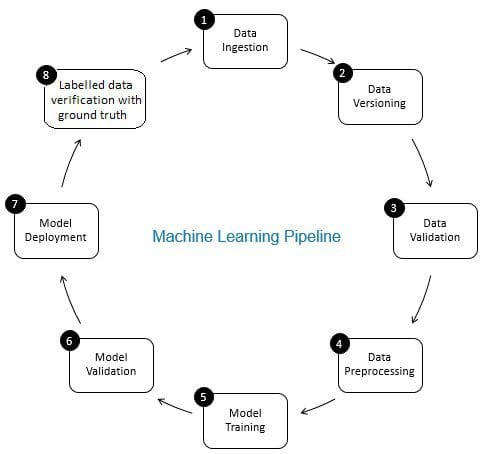
Figura 2: Componentes de la Canalización de Aprendizaje Automático
Aditya Aggarwal se desempeña como Líder de Práctica de Ciencia de Datos en Abzooba Inc. Con más de 12 años de experiencia en la consecución de objetivos empresariales a través de soluciones basadas en datos, Aditya se especializa en análisis predictivo, aprendizaje automático, inteligencia de negocios &, estrategia de negocios en una amplia gama de industrias.
Dr. Arnab Bose es Director Científico de Abzooba, una empresa de análisis de datos y profesor adjunto de la Universidad de Chicago, donde enseña Aprendizaje Automático y Análisis Predictivo, Operaciones de Aprendizaje Automático, Análisis y Pronóstico de Series Temporales y Análisis de Salud en el programa de Maestría en Ciencias en Análisis. Es un veterano de la industria de análisis predictivo de 20 años que disfruta del uso de datos estructurados y no estructurados para pronosticar e influir en los resultados de comportamiento en la atención médica, el comercio minorista, las finanzas y el transporte. Sus áreas de enfoque actuales incluyen la estratificación de riesgos para la salud y el manejo de enfermedades crónicas mediante el aprendizaje automático, y la implementación de producción y el monitoreo de modelos de aprendizaje automático.
Relacionados:
- MLOps- ” ¿Por qué se requiere?”y” ¿Qué es”?
- Mi modelo de aprendizaje automático no aprende. ¿Qué debo hacer?
- Observabilidad de datos, Parte II: Cómo Crear Sus Propios Monitores de Calidad de Datos Utilizando SQL
Leave a Reply