{codificación} Sight
Introducción
Amazon Web Service, también conocido como AWS, es un proveedor líder de infraestructura en la nube para almacenar sus servidores, aplicaciones, bases de datos, redes, controladores de dominio y directorios activos en una arquitectura de nube generalizada. AWS proporciona un Servicio de almacenamiento Simple (S3) para almacenar sus objetos o datos con (119’s) de durabilidad de datos. AWS S3 cumple con PCI-DSS, HIPAA / HITECH, FedRAMP, la Directiva de Protección de Datos de la UE y FISMA, lo que ayuda a satisfacer los requisitos reglamentarios.
Cuando inicie sesión en el portal de AWS, vaya al bucket S3, elija el bucket que desee y descargue o cargue los archivos. Hacerlo manualmente en el portal es una tarea que consume bastante tiempo. En su lugar, puede usar la Interfaz de línea de comandos (CLI) de AWS que funciona mejor para operaciones de archivos masivos con scripts fáciles de usar. Puede programar la ejecución de estos scripts para una descarga/carga de objetos desatendidos.
Configurar AWS CLI
Descargue AWS CLI e instale AWS Command Line Interface V2 en sistemas operativos Windows, macOS o Linux.

Puede seguir el asistente de instalación para una configuración rápida.
Crear un usuario de IAM
Para acceder al bucket AWS S3 mediante la interfaz de línea de comandos, necesitamos configurar un usuario de IAM. En el portal de AWS, vaya a Administración de identidades y acceso (IAM) y haga clic en Agregar usuario.

En la página Agregar usuario, escriba el nombre de usuario y el tipo de acceso como Acceso programático.
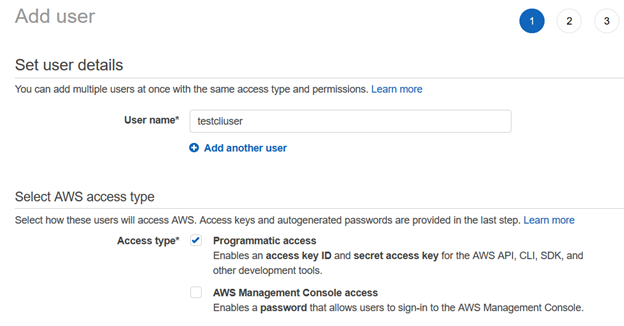
A continuación, proporcionamos permisos al usuario de IAM utilizando las políticas existentes. Para este artículo, hemos elegido entre las políticas administradas de AWS.
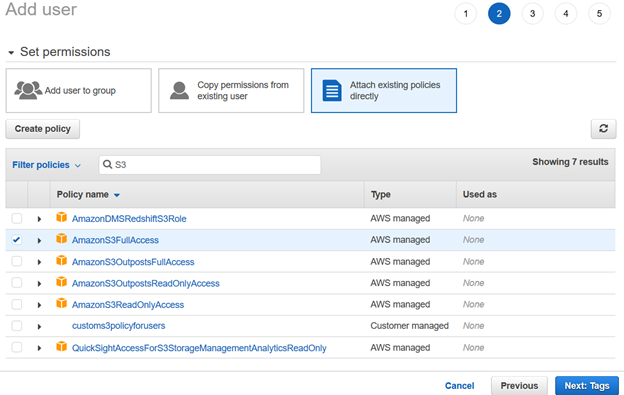
Revise la configuración de usuario de IAM y haga clic en Crear usuario.
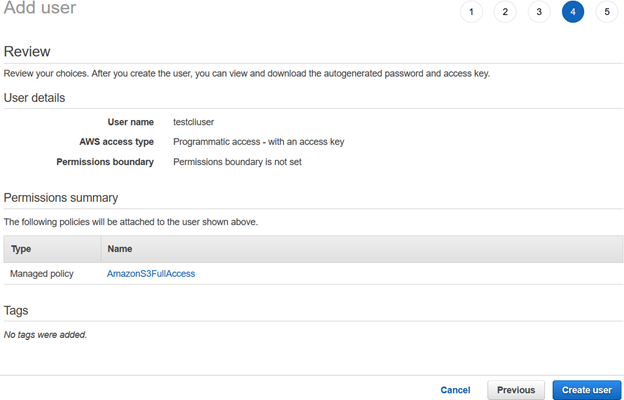
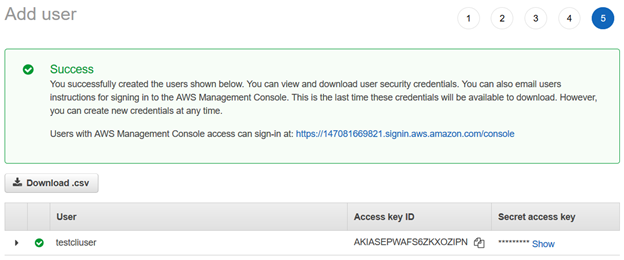
Una vez que se crea el usuario de AWS IAM, proporciona el ID de clave de acceso y la clave de acceso secreta para conectarse mediante la CLI de AWS.
Nota: Debe copiar y guardar estas credenciales. AWS no le permite recuperarlos en una etapa posterior.
Configure el perfil de AWS En su equipo
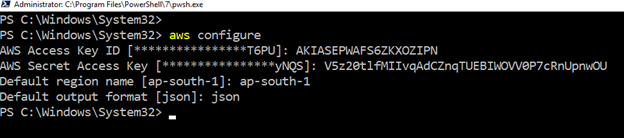
Para trabajar con AWS CLI en recursos de Amazon web service, inicie PowerShell y ejecute el siguiente comando.
>aws configureRequiere las siguientes entradas de usuario:
- ID de clave de acceso de usuario de IAM
- Clave de acceso secreta de AWS
- Nombre de región de AWS predeterminado
- Formato de salida predeterminado
Cree un Bucket S3 Con AWS CLI
Para almacenar los archivos u objetos, necesitamos un bucket S3. Podemos crearlo utilizando el portal de AWS y la CLI de AWS.
El siguiente comando CLI crea un bucket con nombre en la región us-east-1. La consulta devuelve el nombre del bucket en la salida, como se muestra a continuación.
>aws s3api create-bucket --bucket mys3bucket-testupload1 --region us-east-1
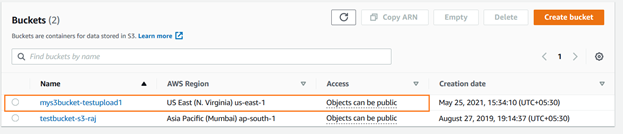
Puede verificar el bucket s3 recién creado mediante la consola de AWS. Como se muestra a continuación, el está cargado en el Este de los Estados Unidos (N. Virginia).
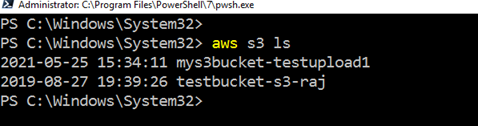
Para enumerar el bucket S3 existente mediante AWS CLI, ejecute el comando – aws s3 ls
Carga de objetos en el Bucket S3 Mediante AWS CLI
Podemos cargar un solo archivo o varios archivos juntos en el bucket AWS S3 mediante el comando AWS CLI. Supongamos que tenemos un solo archivo para cargar. El archivo se almacena localmente en el C:\S3Files con el nombre script1.txt.
Para cargar el archivo único, utilice el siguiente script CLI.
>aws s3 cp C:\S3Files\Script1.txt s3://mys3bucket-testupload1/Carga el archivo y devuelve las rutas de archivo de origen y destino en la salida:

Nota: El tiempo de carga en el bucket S3 depende del tamaño del archivo y del ancho de banda de red. Para el propósito de demostración, utilicé un pequeño archivo de unos pocos KBs.
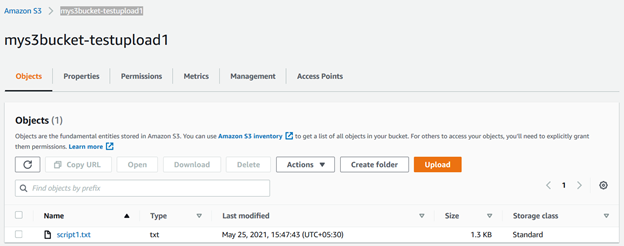
Puede actualizar el bucket s3 y ver el archivo almacenado en él.
Del mismo modo, podemos usar el mismo script CLI con una ligera modificación. Carga todos los archivos del origen al bucket S3 de destino. Aquí, usamos el parámetro recursivo para cargar varios archivos juntos:
>aws s3 cp c:\s3files s3://mys3bucket-testupload1/ --recursiveComo se muestra a continuación, carga todos los archivos almacenados dentro del directorio local c:\S3Files al cubo S3. Obtienes el progreso de cada carga en la consola.
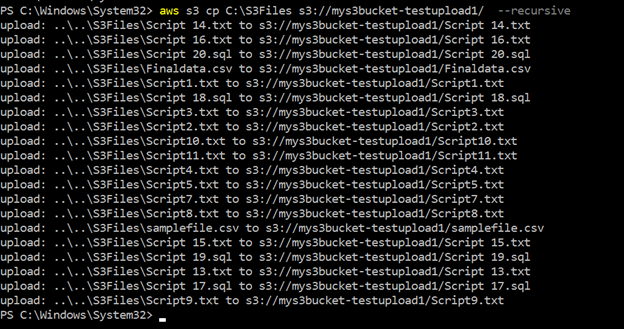
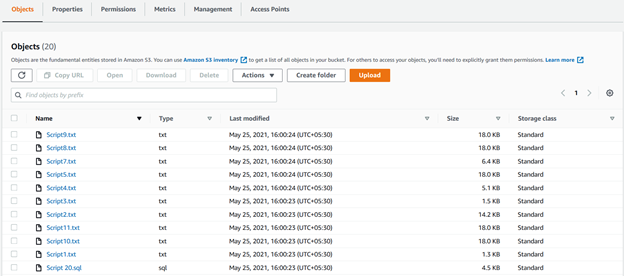
Podemos ver todos los archivos cargados usando parámetros recursivos en el bucket S3 en la siguiente figura:
Si no desea ir al portal de AWS para verificar la lista cargada, ejecute el script CLI, devuelva todos los archivos y cargue las marcas de tiempo.
>aws s3 ls s3://mys3bucket-testupload1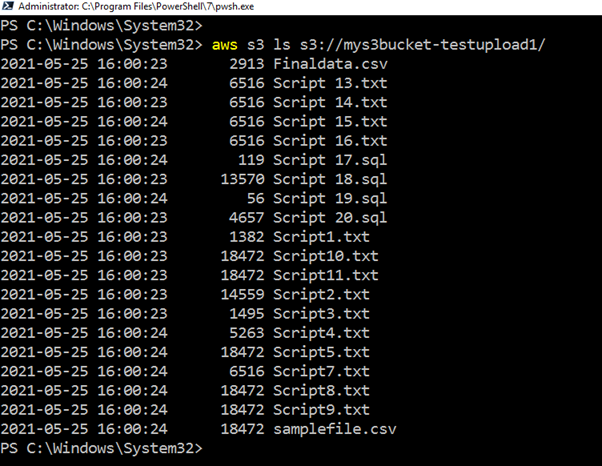
Supongamos que queremos cargar solo archivos con una extensión específica en la carpeta separada de AWS S3. También puede hacer el filtrado de objetos usando el script CLI. Para este propósito, el script utiliza incluir y excluir palabras clave.
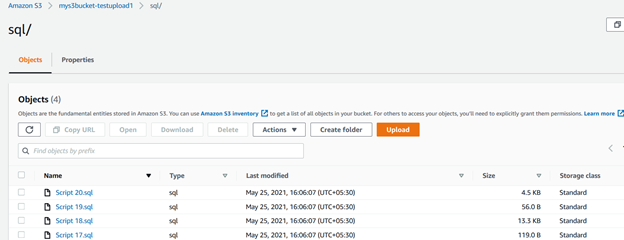
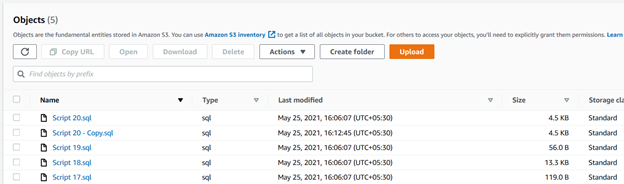
Por ejemplo, la siguiente consulta comprueba los archivos en el directorio fuente (c:\s3bucket), filtra archivos con .extensión sql, y los carga en la carpeta SQL/ del bucket S3. Aquí, especificamos la extensión usando la palabra clave include:
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlEn la salida de script, puede verificar que los archivos con el .solo se cargaron extensiones sql.

Del mismo modo, el siguiente script carga archivos con el .extensión csv en el cubo S3.
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.csv
Cargar Archivos Nuevos o modificados de la Carpeta de origen al Bucket S3
Supongamos que utiliza un bucket S3 para mover las copias de seguridad del registro de transacciones de la base de datos.
Para este propósito, usamos la palabra clave sync. Copia recursivamente archivos nuevos y modificados del directorio de origen al bucket s3 de destino.
>aws s3 sync C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlComo se muestra a continuación, cargó un archivo que estaba ausente en el bucket de s3. Del mismo modo, si modifica cualquier archivo existente en la carpeta de origen, el script CLI lo seleccionará y lo cargará en el bucket S3.

Resumen
El script de CLI de AWS puede facilitar su trabajo para almacenar archivos en el bucket de S3. Puede usarlo para cargar o sincronizar archivos entre carpetas locales y el bucket S3. Es una forma rápida de implementar y trabajar con objetos en la nube de AWS.
Etiquetas: AWS, aws cli, aws s3, plataforma en la nube Última modificación: 16 de septiembre de 2021
Leave a Reply