{coding}Sight
Introduzione
Amazon Web Service, noto anche come AWS, è un fornitore leader di infrastrutture cloud per l’archiviazione di server, applicazioni, database, reti, controller di dominio e active directory in un’architettura cloud diffusa. AWS fornisce un servizio di archiviazione semplice (S3) per la memorizzazione di oggetti o dati con (119) di durata dei dati. AWS S3 è conforme a PCI-DSS, HIPAA / HITECH, FedRAMP, direttiva UE sulla protezione dei dati e FISMA che aiuta a soddisfare i requisiti normativi.
Quando accedi al portale AWS, vai al bucket S3, scegli il bucket desiderato e scarica o carica i file. Farlo manualmente sul portale è un compito che richiede molto tempo. Invece, è possibile utilizzare l’interfaccia a riga di comando AWS (CLI) che funziona meglio per le operazioni di file di massa con script facili da usare. È possibile pianificare l’esecuzione di questi script per il download/upload di un oggetto non presidiato.
Configura AWS CLI
Scarica AWS CLI e installa AWS Command Line Interface V2 su sistemi operativi Windows, macOS o Linux.

È possibile seguire la procedura guidata di installazione per una configurazione rapida.
Creare un utente I
Per accedere al bucket AWS S3 utilizzando l’interfaccia a riga di comando, è necessario impostare un utente AWS. Nel portale AWS, accedere a Identity and Access Management (Identity) e fare clic su Aggiungi utente.

Nella pagina Aggiungi utente, immettere il nome utente e il tipo di accesso come accesso programmatico.
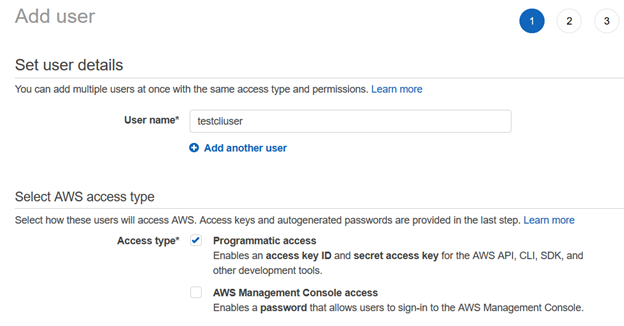
Successivamente, forniamo le autorizzazioni all’utente I utilizzando le politiche esistenti. Per questo articolo, abbiamo scelto tra le policy gestite AWS.
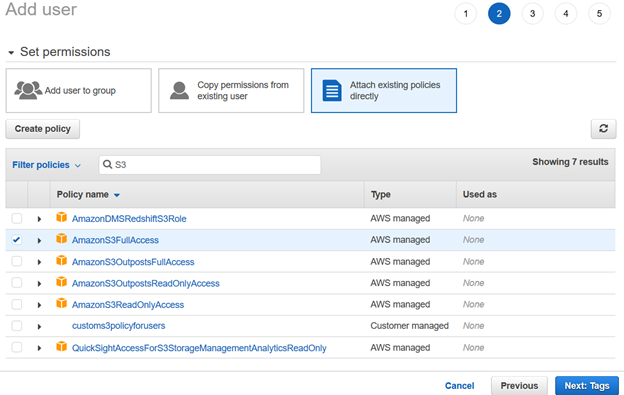
Rivedere la configurazione utente I e fare clic su Crea utente.
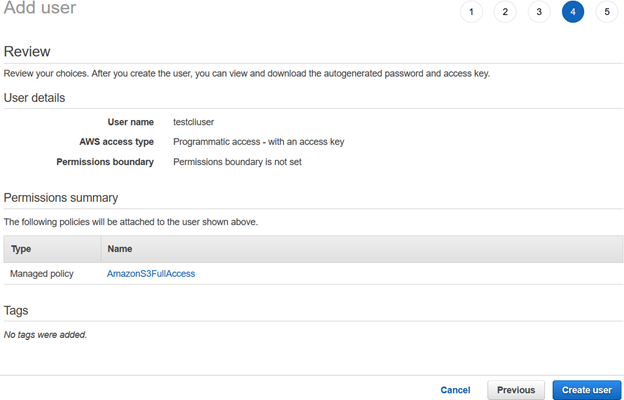
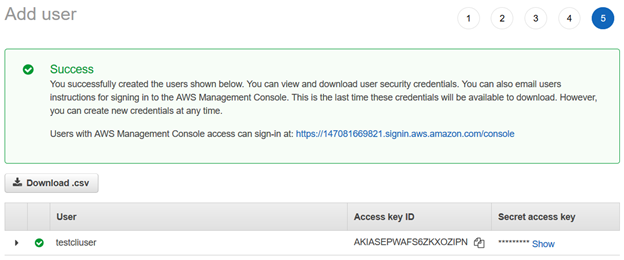
Una volta creato l’utente AWS AWS, fornisce l’ID della chiave di accesso e la chiave di accesso segreta per connettersi utilizzando la CLI AWS.
Nota: È necessario copiare e salvare queste credenziali. AWS non consente di recuperarli in una fase successiva.
Configurare AWS Profile sul computer
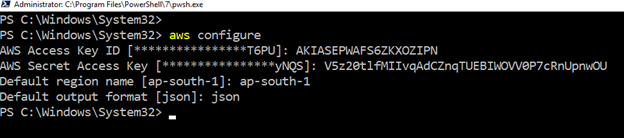
Per lavorare con AWS CLI sulle risorse di Amazon web Service, avviare PowerShell ed eseguire il seguente comando.
>aws configureRichiede i seguenti input dell’utente:
- IAM user ID della Chiave di Accesso
- AWS chiave di Accesso Segreta
- Default AWS regione-nome
- formato di output Predefinito
Creare S3 Secchio Utilizzando AWS CLI
Per memorizzare i file o oggetti, abbiamo bisogno di un S3 secchio. Possiamo crearlo utilizzando sia il portale AWS che AWS CLI.
Il seguente comando CLI crea un bucket denominato nella regione us-east-1. La query restituisce il nome del bucket nell’output, come mostrato di seguito.
>aws s3api create-bucket --bucket mys3bucket-testupload1 --region us-east-1
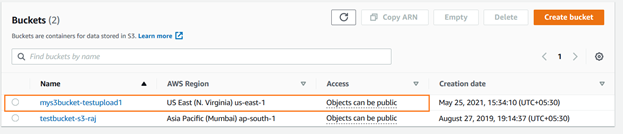
È possibile verificare il bucket s3 appena creato utilizzando la console AWS. Come mostrato di seguito, il viene caricato negli Stati Uniti Est (N. Virginia).
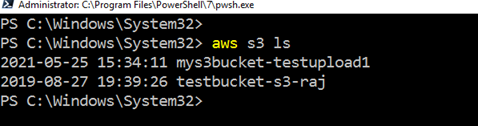
elenco esistente S3 secchio utilizzando AWS CLI, eseguire il comando aws s3 ls
Il caricamento di Oggetti in S3 Secchio Utilizzando AWS CLI
Possiamo caricare un singolo file o più file insieme nel secchio AWS S3 utilizzando il AWS comando CLI. Supponiamo di avere un singolo file da caricare. Il file viene memorizzato localmente nel C:\S3Files con il nome script1.txt.
Per caricare il singolo file, utilizzare il seguente script CLI.
>aws s3 cp C:\S3Files\Script1.txt s3://mys3bucket-testupload1/Carica il file e restituisce i percorsi del file di origine-destinazione nell’output:

Nota: il tempo di caricamento sul bucket S3 dipende dalle dimensioni del file e dalla larghezza di banda della rete. Per lo scopo demo, ho usato un piccolo file di pochi KBs.
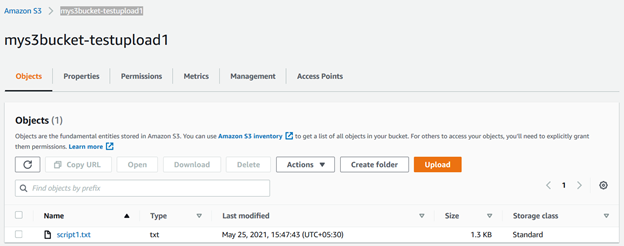
È possibile aggiornare il bucket s3 e visualizzare il file memorizzato in esso.
Allo stesso modo, possiamo usare lo stesso script CLI con una leggera modifica. Carica tutti i file dall’origine al bucket S3 di destinazione. Qui, usiamo il parametro-ricorsivo per caricare più file insieme:
>aws s3 cp c:\s3files s3://mys3bucket-testupload1/ --recursiveCome mostrato di seguito, carica tutti i file memorizzati all’interno della directory locale c:\S3Files al secchio S3. Si ottiene lo stato di avanzamento di ogni caricamento nella console.
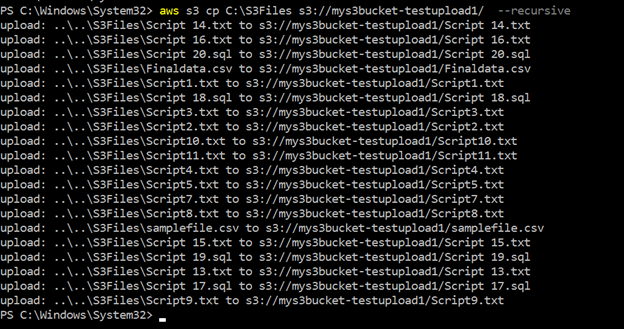
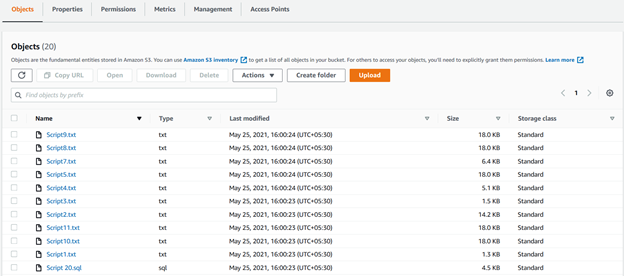
Possiamo vedere tutti i file caricati utilizzando parametri ricorsivi nel bucket S3 nella figura seguente:
Se non si desidera accedere al portale AWS per verificare l’elenco caricato, eseguire lo script CLI, restituire tutti i file e caricare i timestamp.
>aws s3 ls s3://mys3bucket-testupload1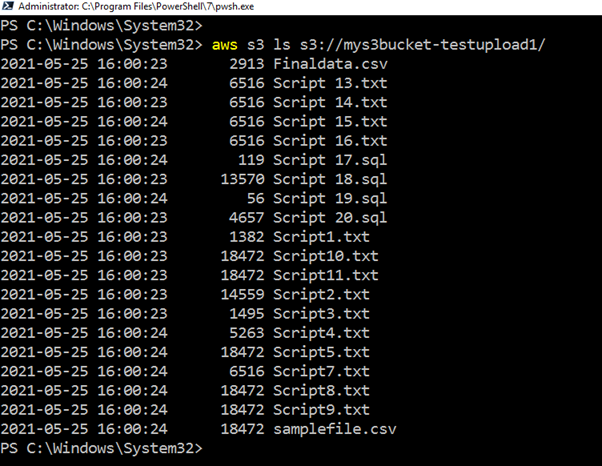
Supponiamo di voler caricare solo file con un’estensione specifica nella cartella separata di AWS S3. È possibile eseguire il filtraggio degli oggetti utilizzando anche lo script CLI. A tale scopo, lo script utilizza le parole chiave include ed exclude.
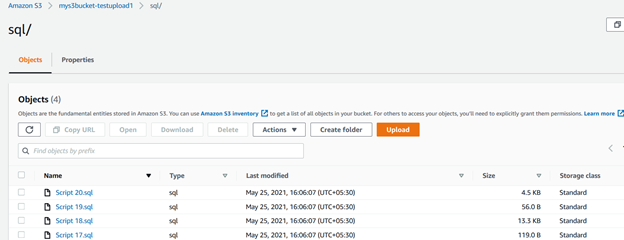
Ad esempio, la query seguente controlla i file nella directory di origine (c:\s3bucket), filtra i file con .estensione sql, e li carica in SQL / cartella del bucket S3. Qui, abbiamo specificato l’estensione utilizzando la parola chiave include:
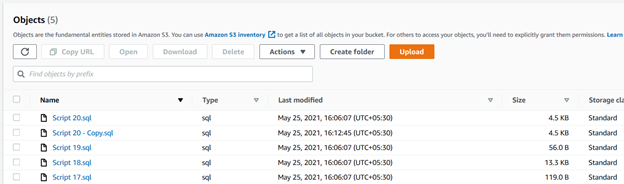
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlNell’output dello script, è possibile verificare che i file con il .sono state caricate solo le estensioni sql.

Allo stesso modo, lo script sotto carica i file con il .estensione csv nel bucket S3.
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.csv
Carica file nuovi o modificati dalla cartella di origine al bucket S3
Supponiamo di utilizzare un bucket S3 per spostare i backup del registro delle transazioni del database.
A questo scopo, usiamo la parola chiave sync. Copia ricorsivamente nuovi file modificati dalla directory di origine al bucket s3 di destinazione.
>aws s3 sync C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlCome mostrato di seguito, ha caricato un file che era assente nel bucket s3. Allo stesso modo, se si modifica un file esistente nella cartella di origine, lo script CLI lo selezionerà e lo caricherà nel bucket S3.

Sommario
Lo script AWS CLI può semplificare il lavoro per l’archiviazione dei file nel bucket S3. È possibile utilizzarlo per caricare o sincronizzare i file tra le cartelle locali e il bucket S3. È un modo rapido per distribuire e lavorare con gli oggetti nel cloud AWS.
Tag: AWS, aws cli, aws s3, cloud platform Ultima modifica: 16 settembre 2021
Leave a Reply