{coding}Sight
はじめに
Amazon Web Service、別名AWSは、広範なクラウドアーキテクチャにサーバー、アプリケーション、デー AWSは、データの耐久性(119)でオブジェクトまたはデータを保存するための単純なストレージサービス(S3)を提供します。 AWS S3は、PCI-DSS、HIPAA/HITECH、FedRAMP、EUデータ保護指令、およびFISMAに準拠しており、規制要件を満たすことができます。
AWSポータルにログインしたら、S3バケットに移動し、必要なバケットを選択して、ファイルをダウンロードまたはアップロードします。 ポータルで手動で行うことは、非常に時間のかかる作業です。 代わりに、使いやすいスクリプトを使用した一括ファイル操作に最適なAWSコマンドラインインターフェイス(CLI)を使用できます。 無人オブジェクトのダウンロード/アップロードのために、これらのスクリプトの実行をスケジュールできます。
AWS CLIの設定
Aws CLIをダウンロードし、Windows、macOS、またはLinuxオペレーティングシステムにAWS Command Line Interface V2をインストールします。

インストールウィザードに従って、迅速なセットアップを行うことができます。
IAMユーザーの作成
コマンドラインインターフェイスを使用してAWS s3バケットにアクセスするには、IAMユーザーを設定する必要があります。 AWSポータルで、[Identity and Access Management(IAM)]に移動し、[ユーザーの追加]をクリックします。

[ユーザーの追加]ページで、ユーザー名とアクセスタイプを[プログラムアクセス]として入力します。
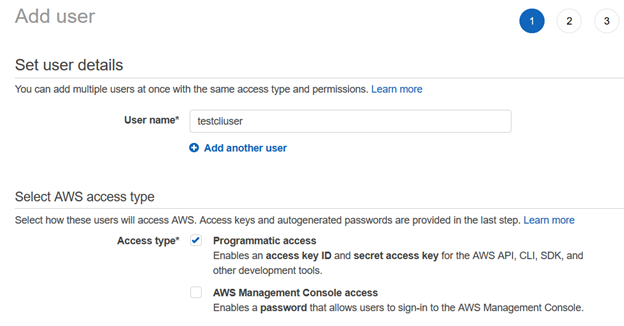
次に、既存のポリシーを使用してIAMユーザーにアクセス許可を提供します。 この記事では、AWS管理ポリシーから選択しました。
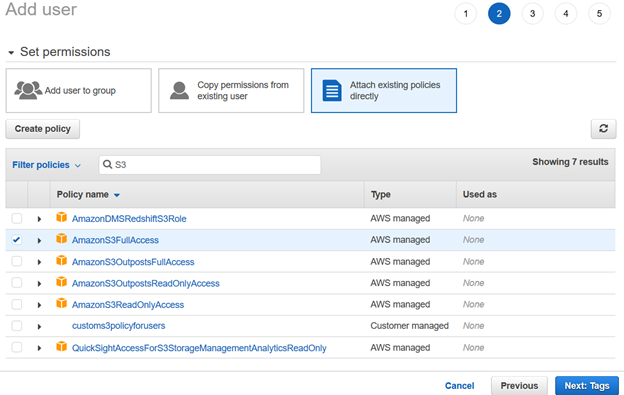
IAMユーザー設定を確認し、[ユーザーの作成]をクリックします。
![IAMユーザー設定を確認し、[ユーザーの作成]をクリックします](http://codingsight.com/wp-content/uploads/2021/07/image-185.png)
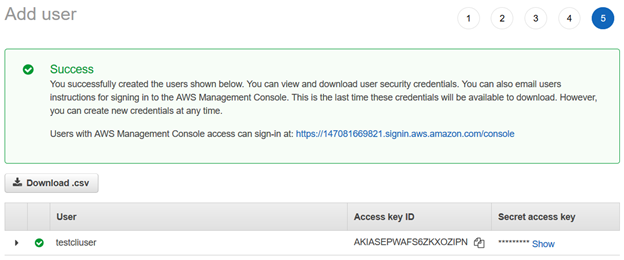
AWS IAMユーザーが作成されると、AWS CLIを使用して接続するためのアクセスキー IDとシークレットアクセスキーが与えられます。
: これらの資格情報をコピーして保存する必要があります。 AWSでは、後の段階でそれらを取得することは許可されていません。
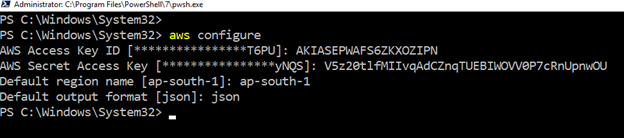
コンピュータでAWSプロファイルを設定する
Amazon web serviceリソースでAWS CLIを使用するには、PowerShellを起動し、次のコマンドを実行します。
>aws configure以下のユーザー入力が必要です:
- IAMユーザーアクセスキー ID
- AWSシークレットアクセスキー
- デフォルトのAWSリージョン名
- デフォルトの出力形式
AWS CLIを使用してS3バケットを作成する
ファイルまたはオブジェクトを保存するには、S3バケットが必要です。 AWS portalとAWS CLIの両方を使用して作成できます。
次のCLIコマンドは、us-east-1リージョンに名前付きバケットを作成します。 クエリは、以下に示すように、出力にバケット名を返します。
>aws s3api create-bucket --bucket mys3bucket-testupload1 --region us-east-1
新しく作成されたs3バケットは、AWSコンソールを使用して確認できます。 以下に示すように、米国東部(N.バージニア州)にアップロードされています。
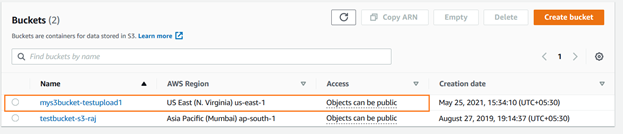
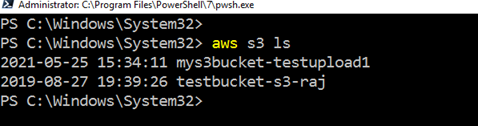
AWS CLIを使用して既存のs3バケットを一覧表示するには、コマンド–aws s3lsを実行します
AWS CLI
を使用したS3バケット内のオブジェクトのアップロードAWS CLIコマンドを使用して、単一のファイルまたは複数のファイルをAWS S3バケット アップロードする単一のファイルがあるとします。 ファイルはローカルに保存されます。C:\S3Files スクリプト1という名前で。txt。
単一のファイルをアップロードするには、次のCLIスクリプトを使用します。
>aws s3 cp C:\S3Files\Script1.txt s3://mys3bucket-testupload1/ファイルをアップロードし、出力にソースと宛先のファイルパスを返します:

注:s3バケットにアップロードする時間は、ファイルサイズとネットワーク帯域幅によって異なります。 デモの目的のために、私は数KBsの小さなファイルを使用しました。
s3バケットを更新して、そこに保存されているファイルを表示できます。
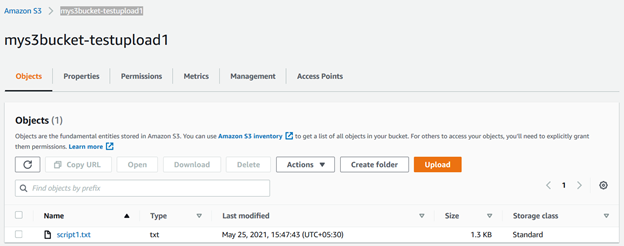
同様に、同じCLIスクリプトをわずかに変更して使用することもできます。 ソースから宛先のs3バケットにすべてのファイルをアップロードします。 ここでは、複数のファイルを一緒にアップロードするためのパラメータ–recursiveを使用します:
>aws s3 cp c:\s3files s3://mys3bucket-testupload1/ --recursive以下に示すように、ローカルディレクトリ内に格納されているすべてのファイルをアップロードしますc:\S3Files s3バケットに。 コンソールで各アップロードの進行状況を取得します。
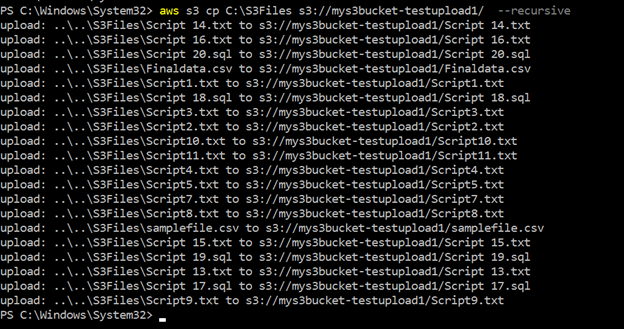
次の図では、s3バケットの再帰パラメータを使用して、アップロードされたすべてのファイルを確認できます:
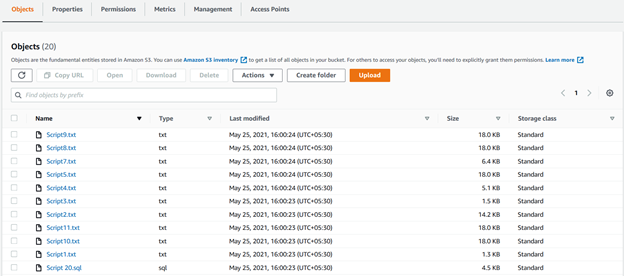
アップロードされたリストを確認するためにAWSポータルに移動しない場合は、CLIスクリプトを実行し、すべてのファイルを返し、タイムスタンプをアッ
>aws s3 ls s3://mys3bucket-testupload1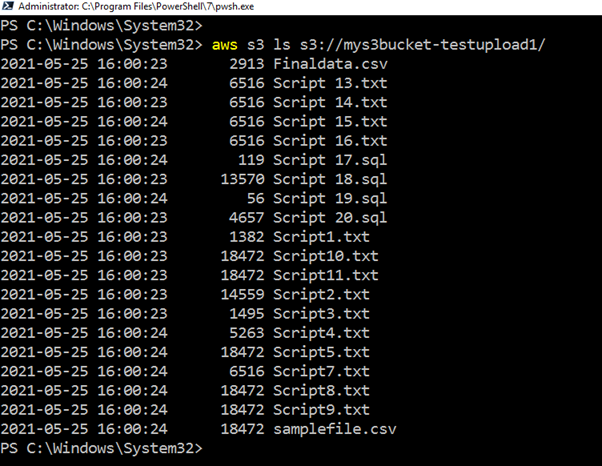
特定の拡張子を持つファイルのみをAWS S3の別のフォルダーにアップロードするとします。 CLIスクリプトを使用してオブジェクトのフィルタリングを行うこともできます。 この目的のために、スクリプトはincludeキーワードとexcludeキーワードを使用します。
たとえば、次のクエリはソースディレクトリ内のファイルをチェックします(c:\s3bucket)、でファイルをフィルタリングします。sql拡張機能を使用して、S3バケットのSQL/フォルダにアップロードします。 ここでは、includeキーワードを使用して拡張機能を指定しました:
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlスクリプト出力では、そのファイルを確認することができます。sql拡張機能のみがアップロードされました。

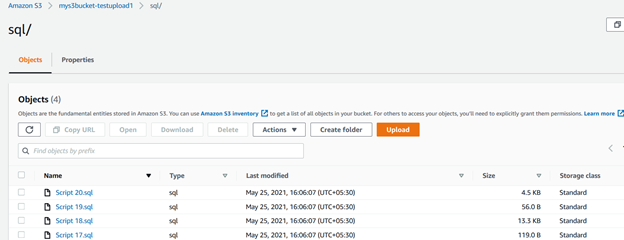
同様に、以下のスクリプトはファイルをアップロードします。s3バケットへのcsv拡張。
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.csv
ソースフォルダからS3バケット
に新しいファイルまたは変更されたファイルをアップロードするs3バケットを使用してデータベーストランザクションログバックアップを移動するとします。
この目的のために、syncキーワードを使用します。 これは、ソースディレクトリからコピー先のs3バケットに、変更された新しいファイルを再帰的にコピーします。
>aws s3 sync C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sql以下に示すように、s3バケットに存在しないファイルをアップロードしました。 同様に、ソースフォルダ内の既存のファイルを変更すると、CLIスクリプトはそれを選択してS3バケットにアップロードします。

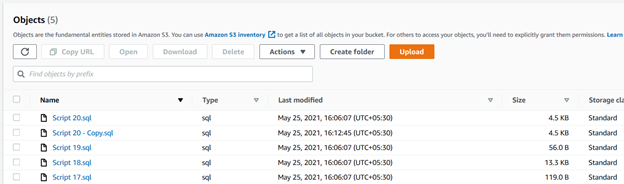
概要
AWS CLIスクリプトを使用すると、S3バケットにファイルを保存する作業が簡単になります。 これを使用して、ローカルフォルダとS3バケット間でファイルをアップロードまたは同期できます。 これは、AWSクラウド内のオブジェクトをデプロイして操作するための簡単な方法です。
タグ:AWS、aws cli、aws s3、cloud platform最終更新日:2021年9月16日
Leave a Reply