{coding}Sight
introdução
o Amazon Web Service, também conhecido como AWS, é um provedor líder de infraestrutura de nuvem para armazenar seus servidores, aplicativos, bancos de dados, redes, controladores de domínio e diretórios ativos em uma arquitetura de nuvem generalizada. A AWS fornece um serviço de armazenamento simples (S3) para armazenar seus objetos ou dados com (119) de durabilidade de dados. O AWS S3 é compatível com PCI-DSS, HIPAA/HITECH, FedRAMP, Diretiva de proteção de dados da UE e FISMA que ajuda a satisfazer os requisitos regulamentares.
ao fazer login no portal da AWS, navegue até o bucket do S3, escolha o bucket necessário e faça o download ou o upload dos arquivos. Fazê-lo manualmente no portal é uma tarefa bastante demorada. Em vez disso, você pode usar a AWS Command Line Interface (CLI) que funciona melhor para operações de arquivos em massa com scripts fáceis de usar. Você pode agendar a execução desses scripts para um download/upload de objeto autônomo.
Configure o AWS CLI
baixe o AWS CLI e instale o AWS Command Line Interface V2 nos sistemas operacionais Windows, macOS ou Linux.

você pode seguir o Assistente de instalação para uma configuração rápida.
crie um usuário IAM
para acessar o bucket do AWS S3 usando a interface de linha de comando, precisamos configurar um usuário IAM. No portal da AWS, navegue até Identity and Access Management (IAM) e clique em Adicionar Usuário.

na página Adicionar usuário, insira o nome de usuário e o tipo de acesso como acesso programático.
em seguida, fornecemos permissões para o usuário IAM usando políticas existentes. Para este artigo, escolhemos as políticas gerenciadas da AWS.
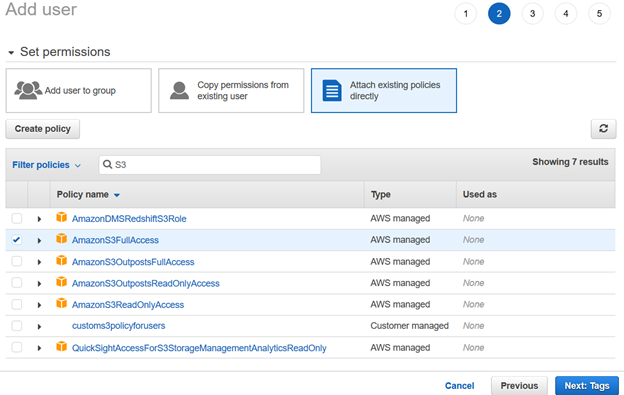
revise a configuração do usuário IAM e clique em Criar usuário.
depois que o usuário do AWS IAM é criado, ele fornece o ID da chave de acesso e a chave de acesso secreta para se conectar usando a CLI da AWS.
Nota: Você deve copiar e salvar essas credenciais. A AWS não permite que você os recupere em um estágio posterior.
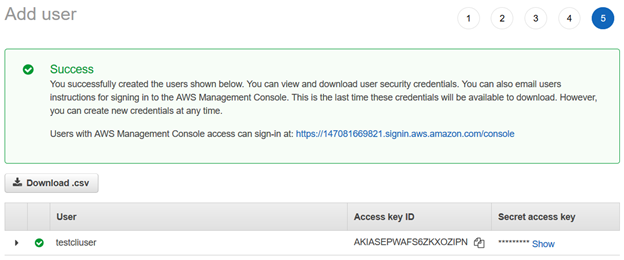
Configure o perfil AWS no seu computador
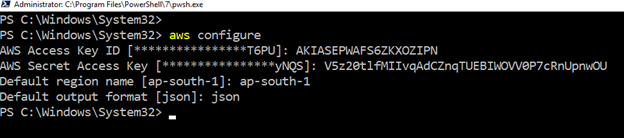
para trabalhar com o AWS CLI nos recursos do Amazon web service, Inicie o PowerShell e execute o seguinte comando.
>aws configurerequer as seguintes entradas de usuário:
- usuário do IAM ID de Chave de Acesso
- AWS chave de Acesso Secreta
- Padrão AWS região-name
- formato de saída Padrão
Criar Bucket S3 Usando o AWS CLI
Para armazenar os arquivos ou objetos, precisamos de um bucket S3. Podemos criá-lo usando o AWS portal e a AWS CLI.
o seguinte comando CLI cria um bucket nomeado na região us-east-1. A consulta retorna o nome do bucket na saída, conforme mostrado abaixo.
>aws s3api create-bucket --bucket mys3bucket-testupload1 --region us-east-1
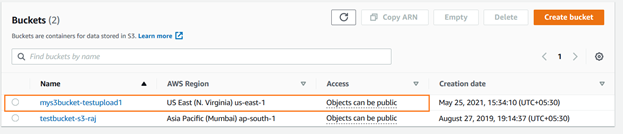
você pode verificar o bucket S3 recém-criado usando o console da AWS. Como mostrado abaixo, o é carregado no leste dos EUA (N. Virginia).
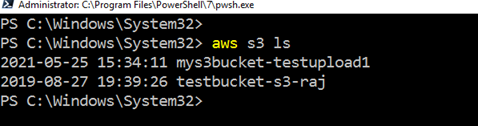
A lista existente bucket S3 usando o AWS CLI, execute o comando da aws s3 ls
Carregar Objetos no Bucket S3 Usando o AWS CLI
Nós pode fazer o upload de um único arquivo ou vários arquivos juntos na AWS bucket S3 usando o AWS comando CLI. Suponha que tenhamos um único arquivo para carregar. O arquivo é armazenado localmente no C:\S3Files com o nome script1.txt.
para carregar o arquivo único, use o seguinte script CLI.
>aws s3 cp C:\S3Files\Script1.txt s3://mys3bucket-testupload1/– carrega o arquivo e retorna a origem-destino, caminhos de arquivo na saída:

Nota: O tempo necessário para carregar o balde S3 depende do tamanho do arquivo e a largura de banda da rede. Para fins de demonstração, usei um pequeno arquivo de alguns KBs.
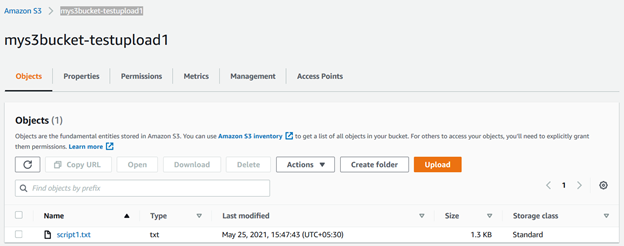
você pode atualizar o bucket s3 e visualizar o arquivo armazenado nele.
da mesma forma, podemos usar o mesmo script CLI com uma ligeira modificação. Ele carrega todos os arquivos da origem para o bucket S3 de destino. Aqui, usamos o parâmetro –recursivo para fazer upload de vários arquivos juntos:
>aws s3 cp c:\s3files s3://mys3bucket-testupload1/ --recursiveComo mostrado abaixo, ele carrega todos os arquivos armazenados dentro do diretório local c:\S3Files para o bucket S3. Você obtém o progresso de cada upload no console.
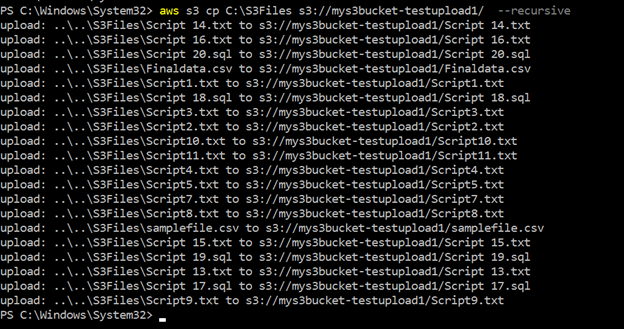
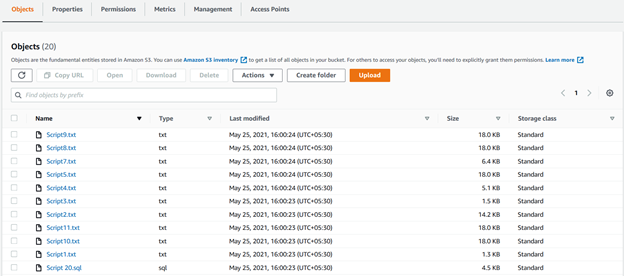
podemos ver todos os arquivos carregados usando recursiva parâmetros no bucket S3 na figura a seguir:
Se você não quer ir para o portal AWS para verificar o upload da lista, execute o CLI script, retornar todos os arquivos, e fazer o upload de carimbos de data / hora.
>aws s3 ls s3://mys3bucket-testupload1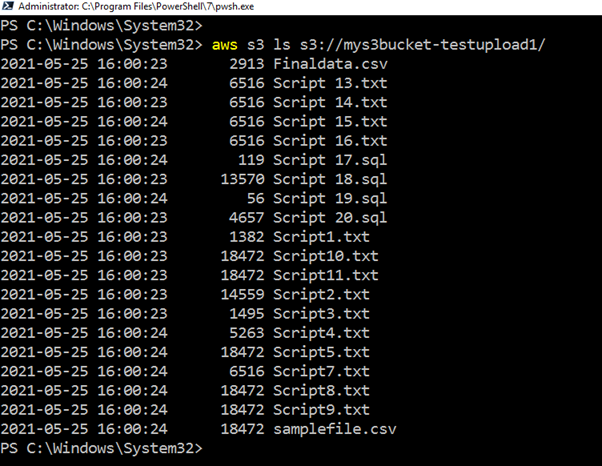
suponha que desejemos fazer upload de apenas arquivos com uma extensão específica para a pasta separada do AWS S3. Você pode fazer a filtragem de objetos usando o script CLI também. Para esse fim, o script usa incluir e excluir palavras-chave.
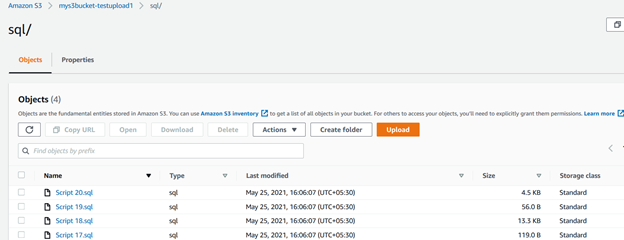
por exemplo, a consulta abaixo verifica arquivos no diretório de origem (c:\s3bucket), filtra arquivos com .extensão sql e os carrega na pasta SQL / do bucket S3. Aqui, especificamos a extensão usando a palavra-chave include:
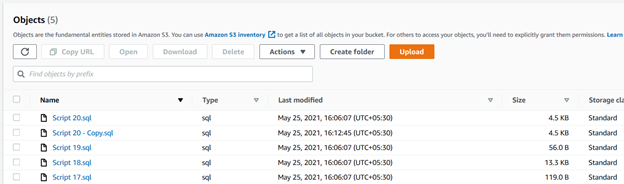
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlna saída do script, você pode verificar se os arquivos com o.extensões sql só foram carregadas.

da mesma forma, o script abaixo carrega arquivos com o.extensão csv para o bucket S3.
>aws s3 cp C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.csv
carregue arquivos novos ou modificados da pasta de origem para o Bucket S3
suponha que você use um bucket S3 para mover os backups do log de transações do banco de dados.
para esse fim, usamos a palavra-chave sync. Ele copia recursivamente novos arquivos modificados do Diretório de origem para o bucket S3 de destino.
>aws s3 sync C:\S3Files s3://mys3bucket-testupload1/ --recursive --exclude * --include *.sqlcomo mostrado abaixo, ele carregou um arquivo que estava ausente no bucket S3. Da mesma forma, se você modificar qualquer arquivo existente na pasta de origem, o script CLI o escolherá e o carregará no bucket S3.

Resumo
O AWS CLI script pode tornar o seu trabalho mais fácil para o armazenamento de arquivos no bucket S3. Você pode usá-lo para fazer upload ou sincronizar arquivos entre pastas locais e o bucket S3. É uma maneira rápida de implantar e trabalhar com objetos na Nuvem AWS.Tags: AWS, aws cli, aws S3, cloud platform última modificação: 16 de setembro de 2021
Leave a Reply